Descargar como ODP, PPTX
















![Reglas de oro
Internamente siempre utilizar Unicode
>>> dato = 'mxc3xa1scara' # máscara en UTF8
>>> len(dato)
8
>>> print dato[:4]
más
>>> print dato.upper()
MáSCARA
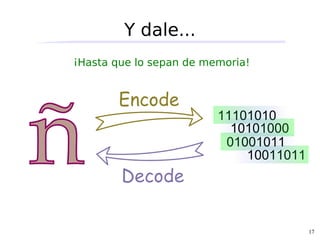
Codificar y decodificar en los bordes
encode/decode
codecs.open() 18](https://image.slidesharecdn.com/unicode-120419123056-phpapp01/85/Entendiendo-Unicode-Facundo-Batista-18-320.jpg)
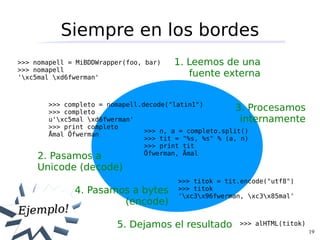




Unicode es un estándar que asigna códigos numéricos únicos a más de 100,000 caracteres. Los caracteres Unicode se pueden codificar en formatos como UTF-8, UTF-16 y UTF-32 para su almacenamiento y transmisión como secuencias de bytes. Es importante codificar y decodificar cadenas al pasar entre representaciones internas de Unicode y formatos de bytes.



















































































