Descargado 17 veces






![. . . . .
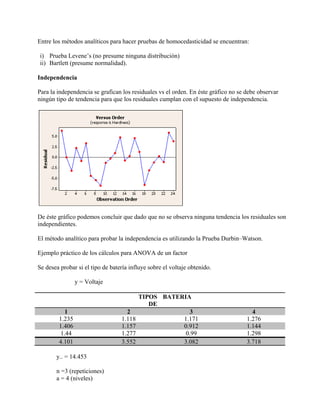
= 0.1782
14.453
1.255 1.406 1.44 1.144 1.298 0.26
12
0.26 0.1782 0.0818
Fuentes Grados de Promedio F calculada F calculada
libertad de
cuadrados
Batería 4-1=3 0.1782 0.1782 0.0594
3 0.0102
0.0594 5.82
Error 8 0.0818 0.0818
8
0.0102
Valor p = 0.21
Mientras mayor la F; p es más pequeña.
Fc= 5.82
Conclusión: Al 5% de error se concluye que el tipo de batería influye sobre el voltaje obtenido.
ANOVA solo detecta si existe diferencia significativa entre por lo menos un par de medias, pero no
puede detectar cuál es el par de medias que difiere. Para poder detectar el par que difiere hay que
utilizar una prueba “ad hoc” (prueba después de ANOVA).
Pruebas después de ANOVA
Scheffé.
Newman Keuls
Duncan Multiple Range
Tukey.
LSD Fisher (Minitab). [Least Significant Difference].
Dunnett.](https://image.slidesharecdn.com/7422401/85/notas19deagosto-9-320.jpg)


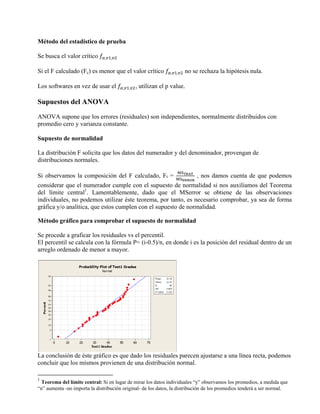
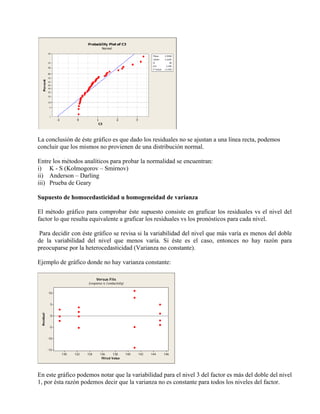
Este documento presenta los conceptos fundamentales del análisis de varianza (ANOVA) para un factor completamente aleatorio. Explica cómo se descompone la variabilidad total en variabilidad entre grupos y dentro de grupos, y cómo se utiliza la distribución F para determinar si al menos un grupo difiere significativamente de los demás. También cubre los supuestos de normalidad, homocedasticidad e independencia del ANOVA y métodos para evaluarlos.




















































































