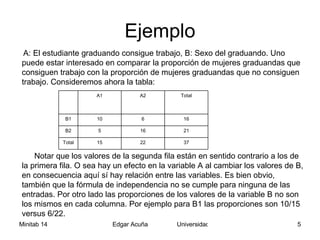
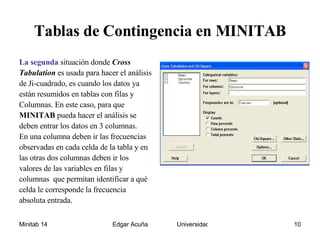
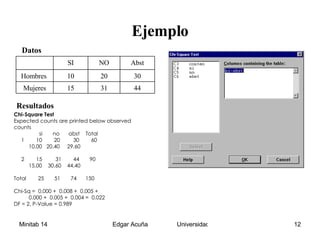
Este documento presenta un resumen de los métodos para analizar datos categóricos. Explica las pruebas de independencia y homogeneidad usando tablas de contingencia y el estadístico chi-cuadrado. También describe medidas de asociación como el coeficiente de contingencia y de Cramer. Por último, introduce la prueba de bondad de ajuste para determinar si un conjunto de datos sigue una distribución conocida.