Descargado 211 veces



![En la mayor parte de las aplicaciones, los parámetros
poblacionales no serán completamente conocidas, y se intentará
utilizar la muestra para hacer inferencia sobre ellos
Los valores µ y 2 se denominarán media poblacional y
varianza poblacional.
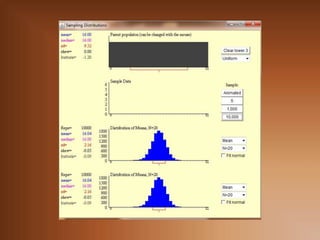
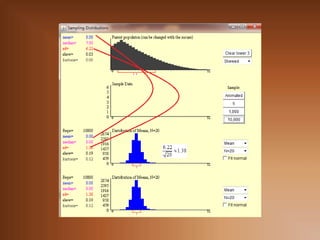
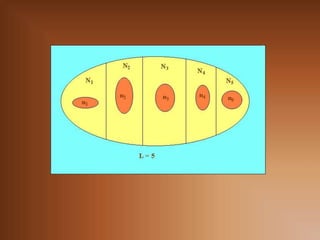
Sean X1, X2, … , Xn los valores de una muestra extraída
de una población . La media muestral se define como:
X 1 ... X n
X
n
Se puede demostrar que el valor esperado de la media
muestral es igual a la media poblacional, esto es:
E[ X ] ](https://image.slidesharecdn.com/4-1teoremacentraldelmite-130101150516-phpapp01/85/4-1-Teorema-Central-de-Limite-3-320.jpg)




















Este documento trata sobre la inferencia estadística y el muestreo. Explica que la inferencia estadística consiste en extraer conclusiones sobre una población a partir de una muestra. También describe diferentes tipos de muestreo como el muestreo aleatorio simple y el muestreo estratificado, y conceptos estadísticos como la media, varianza y distribución normal.





































![[Exposicion] modelos probabilísticos aplicados](https://cdn.slidesharecdn.com/ss_thumbnails/exposicion-modelosprobabilsticosaplicados-120507225205-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)





























