

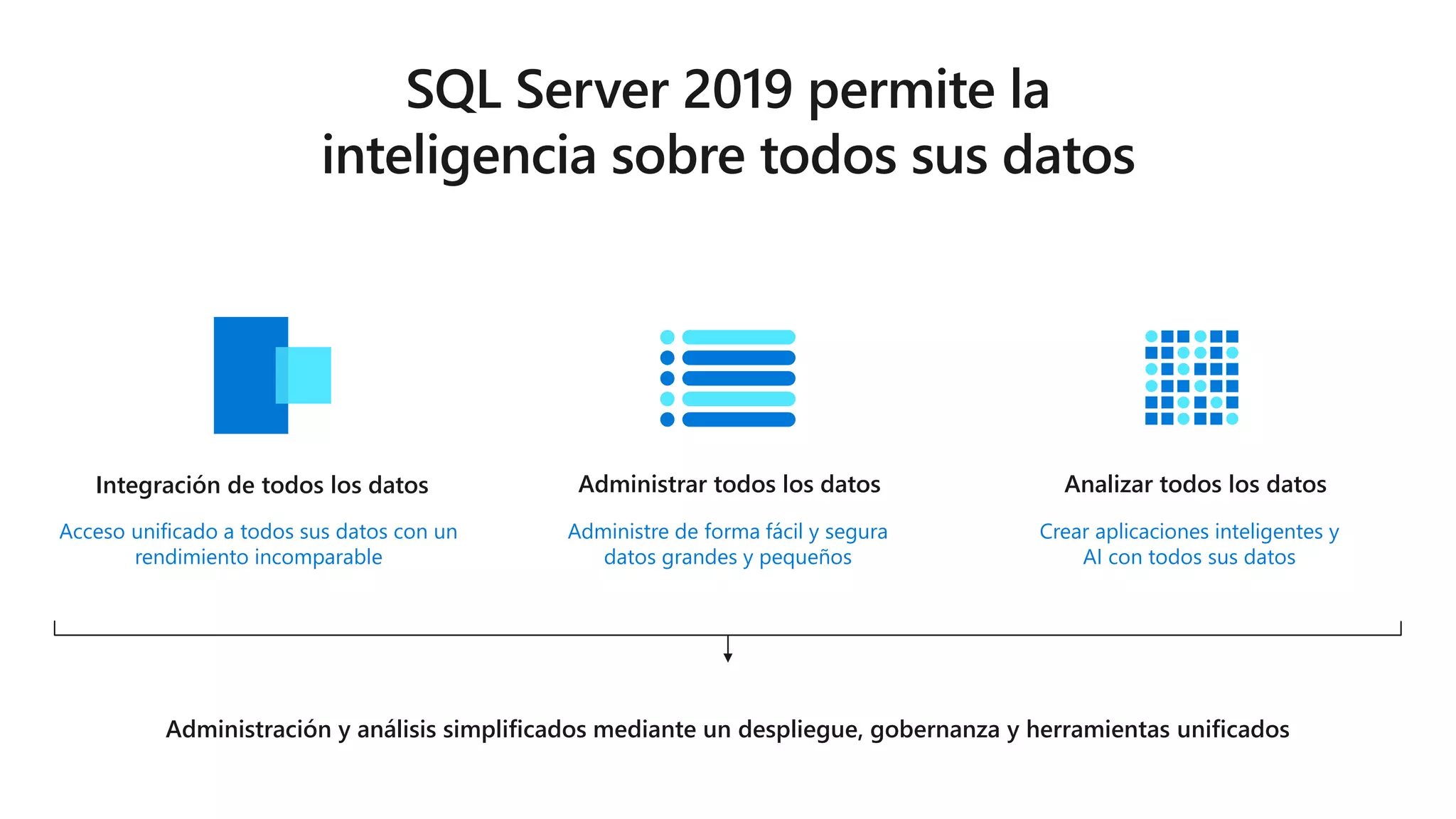

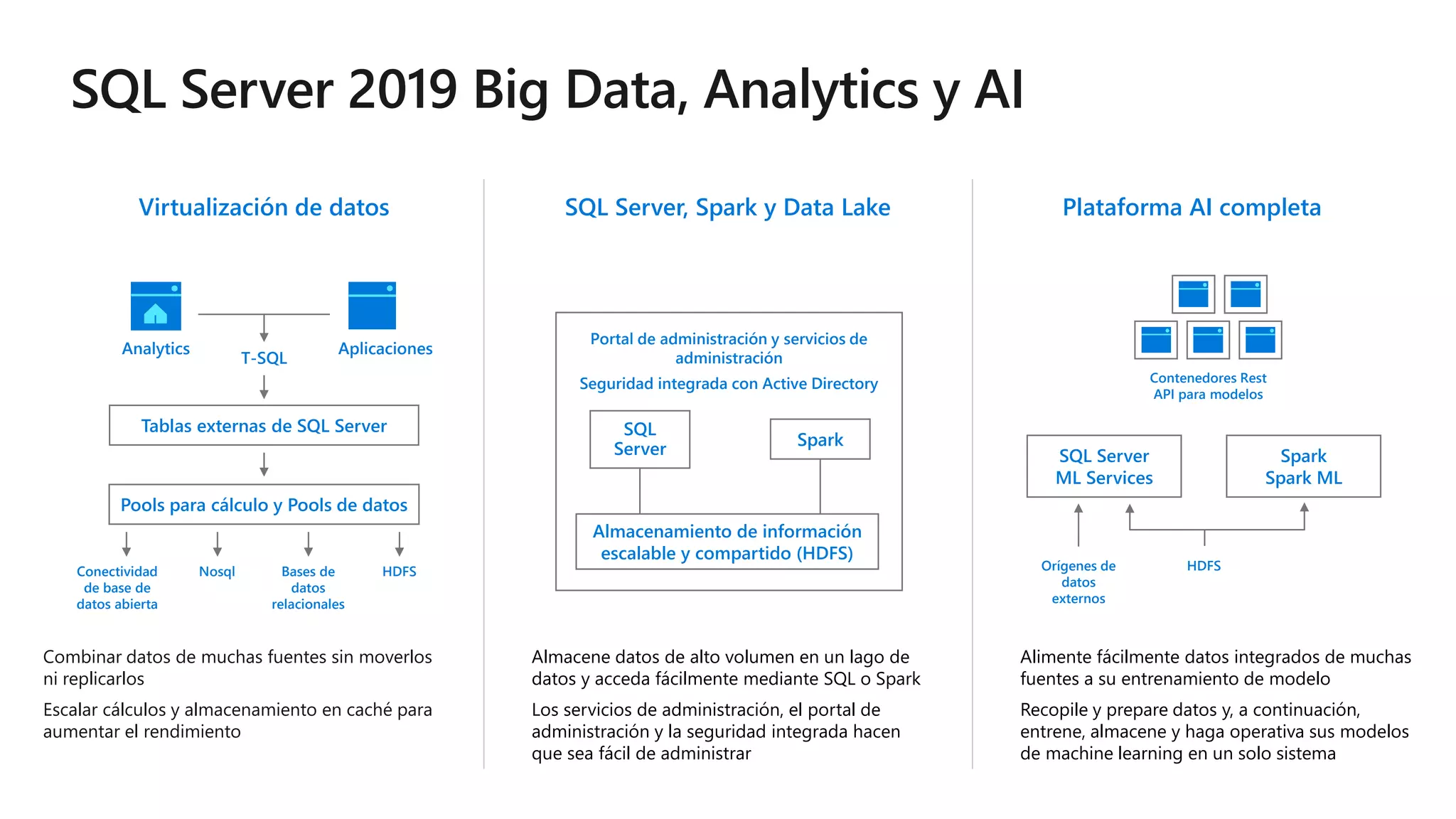
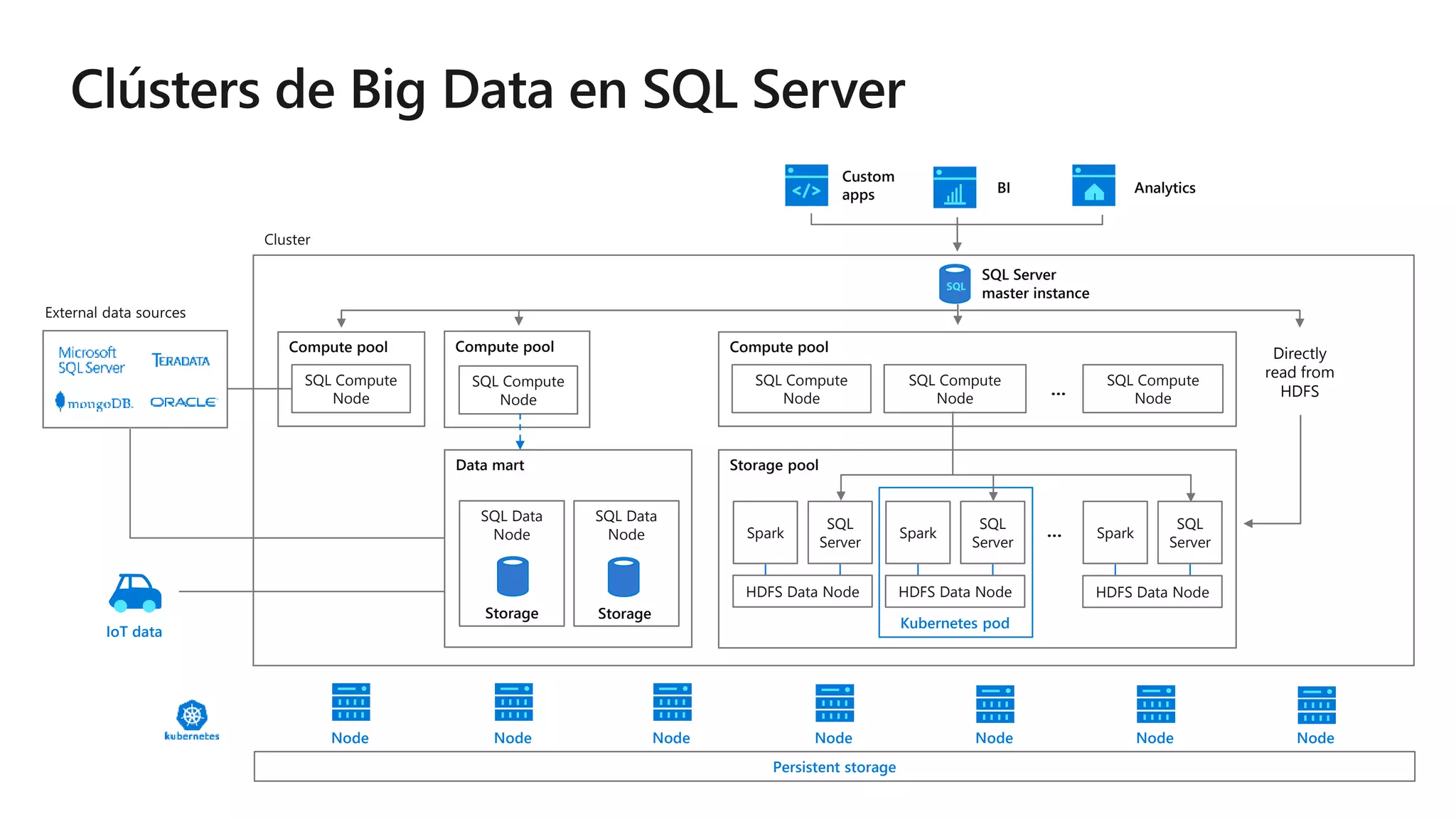
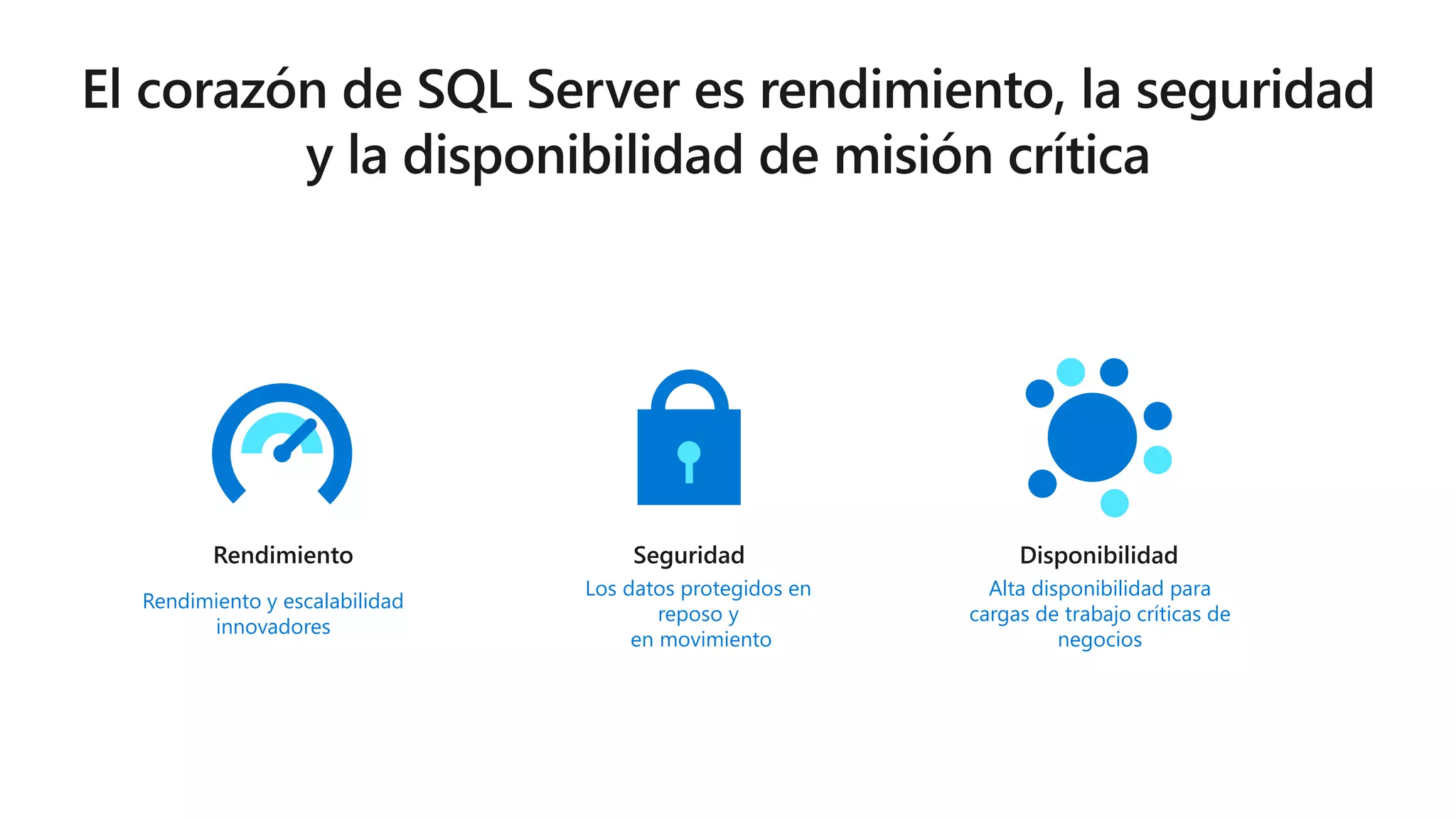
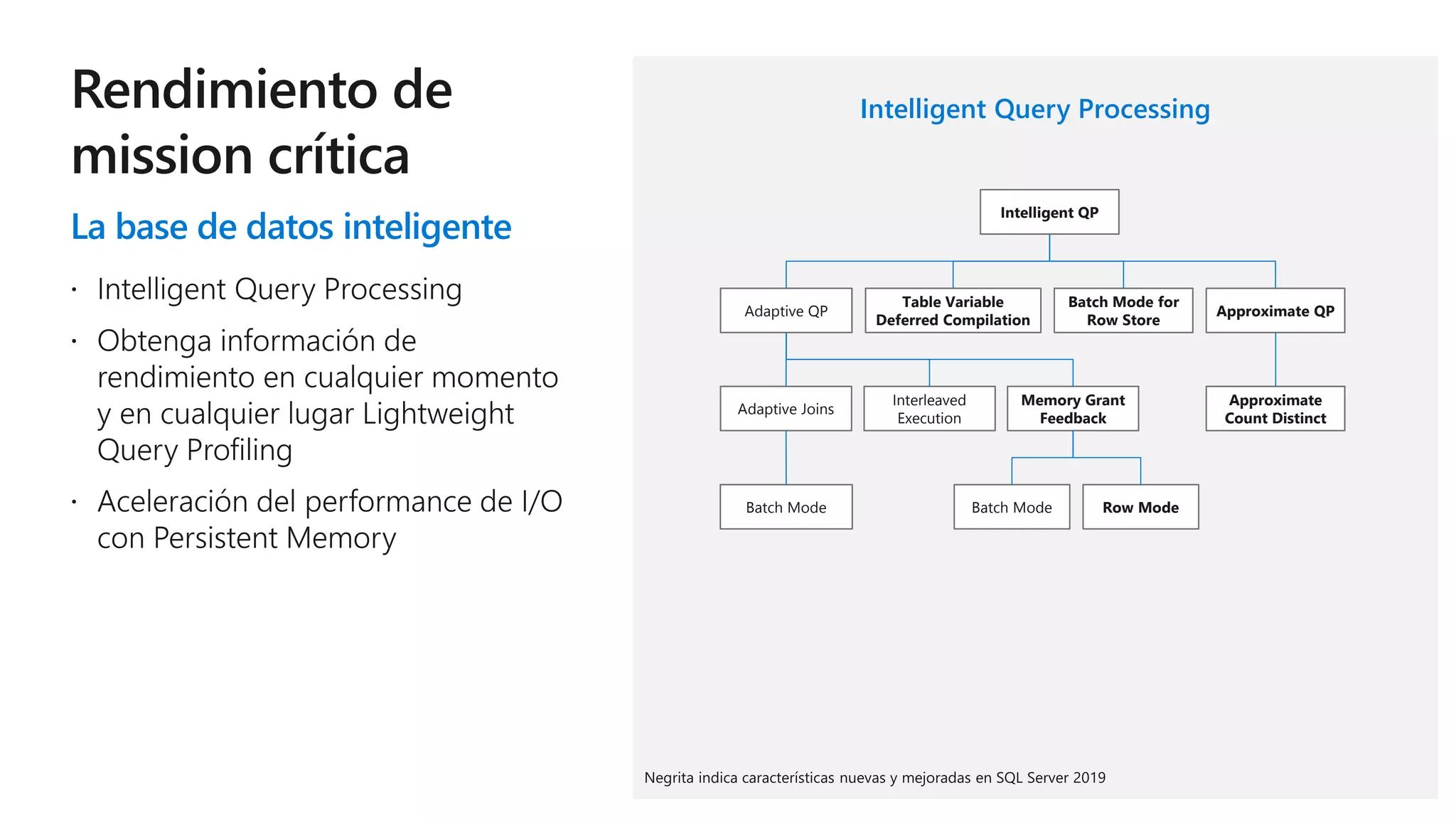
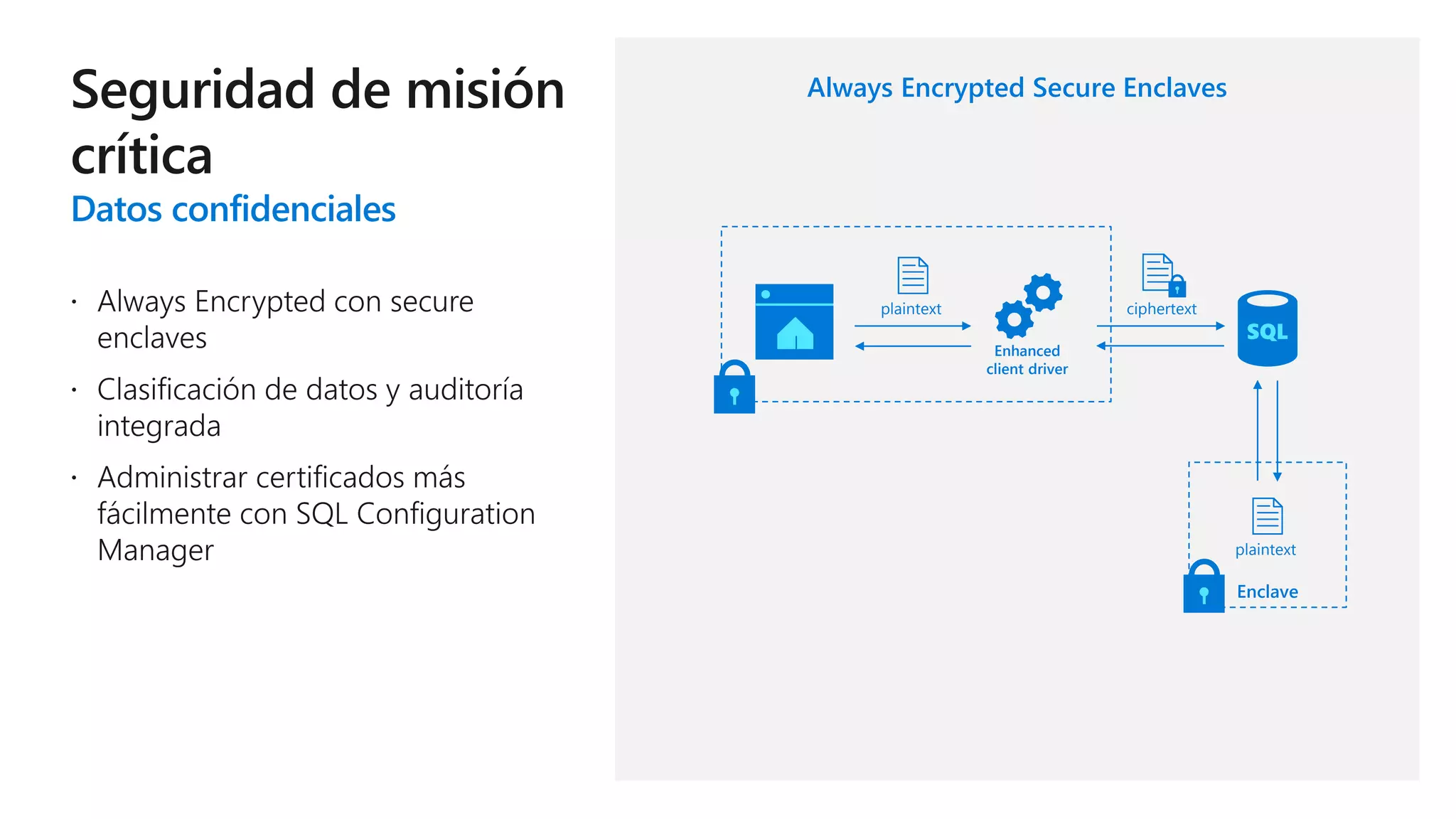
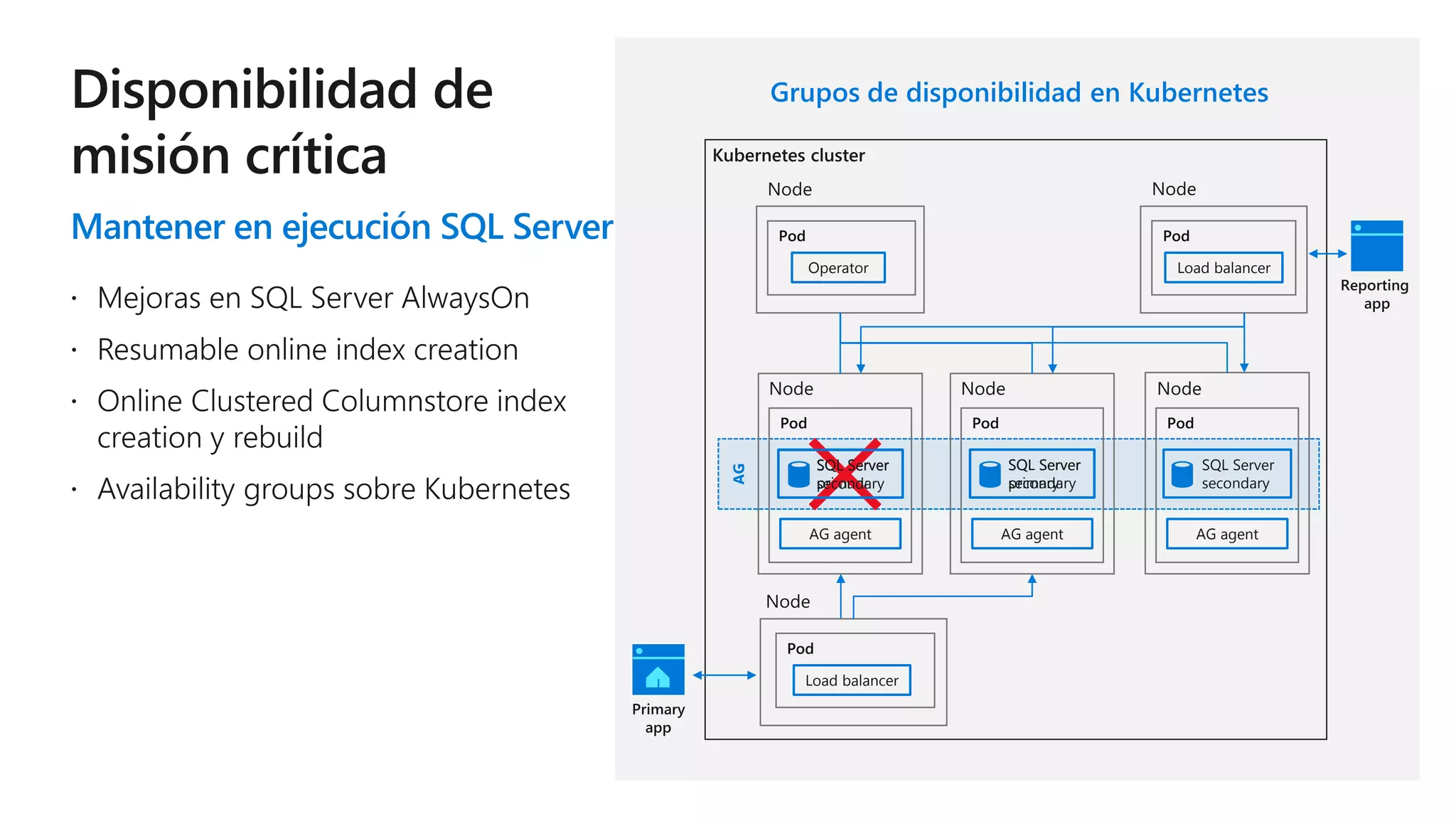
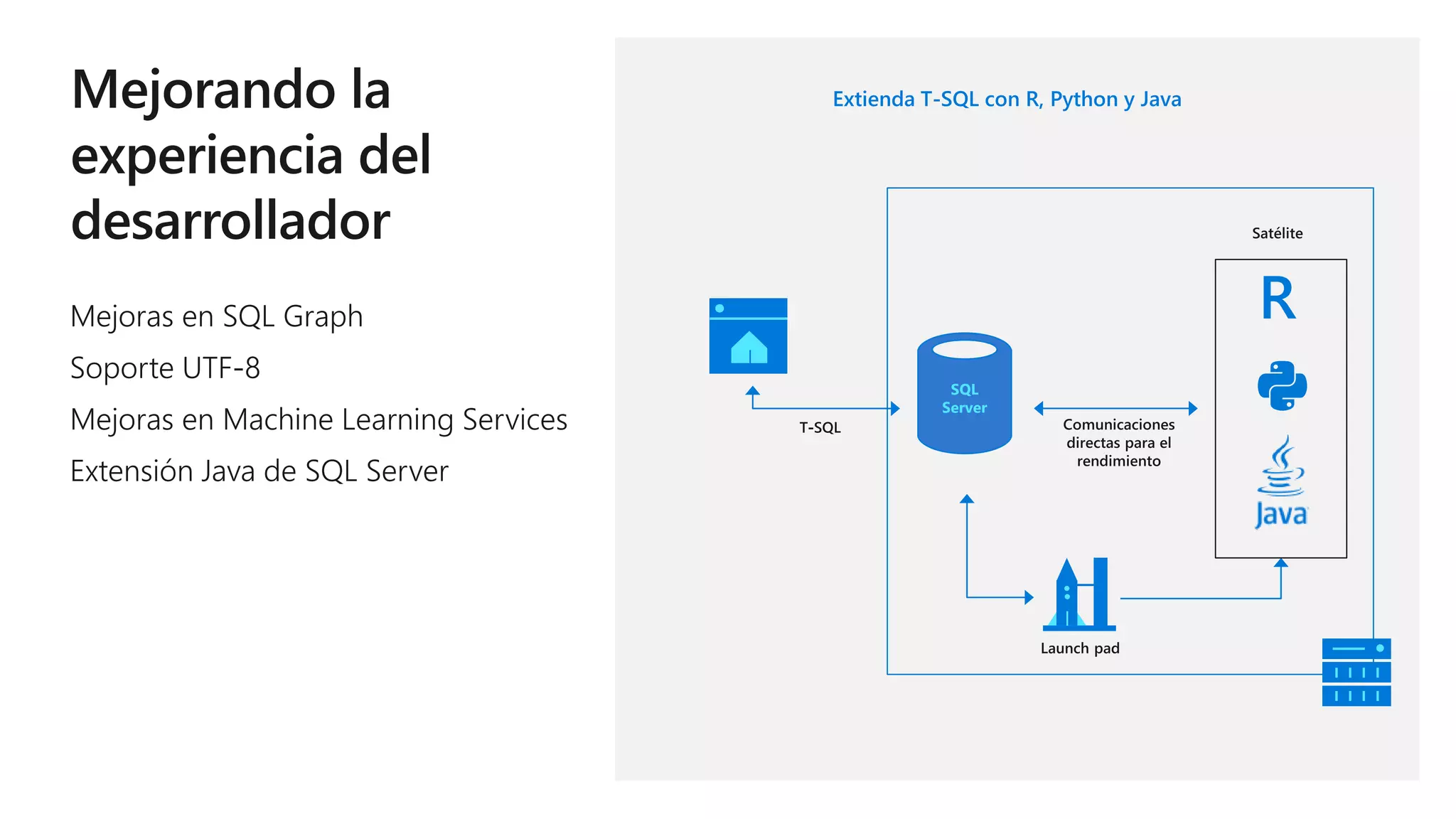
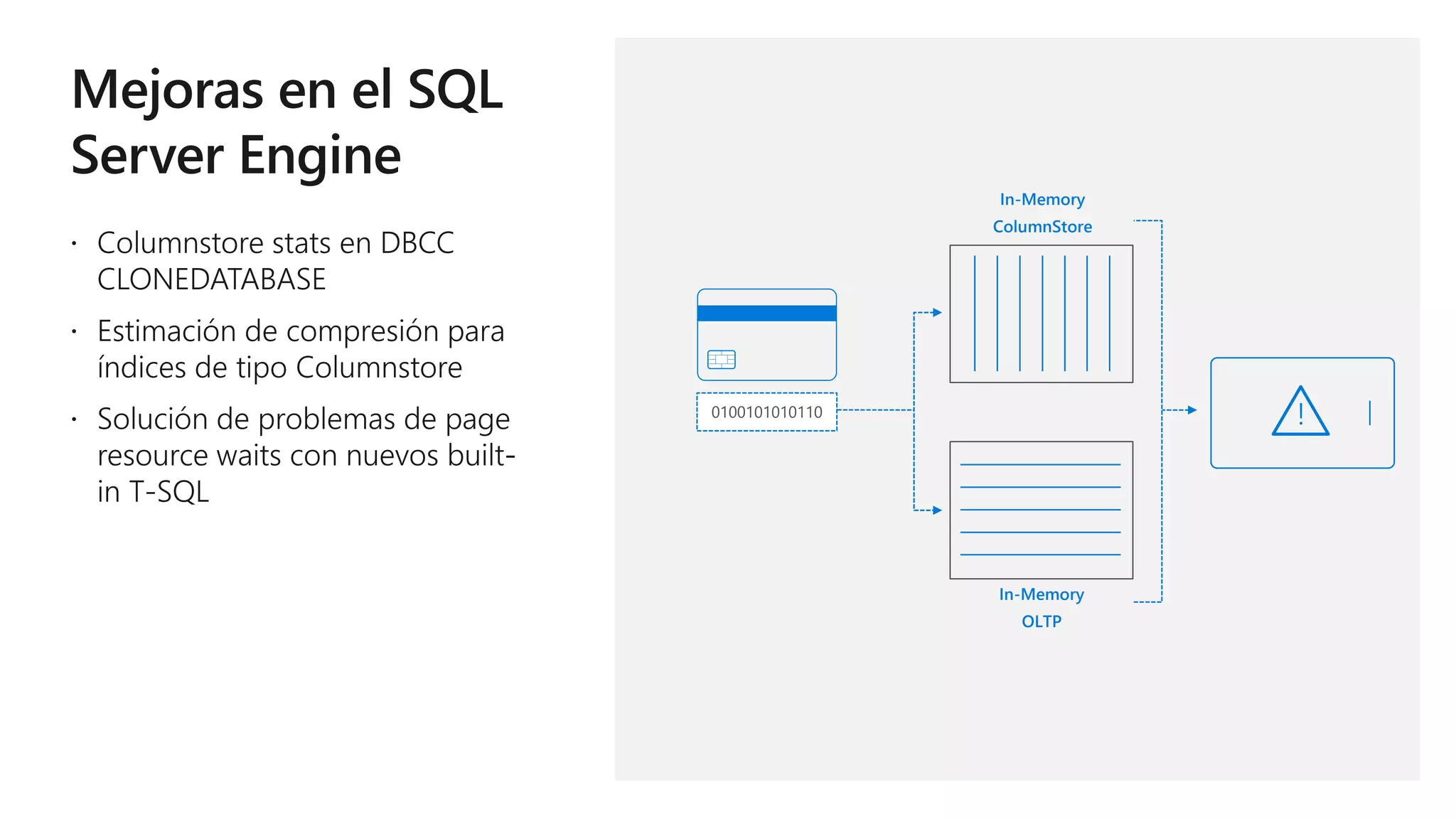
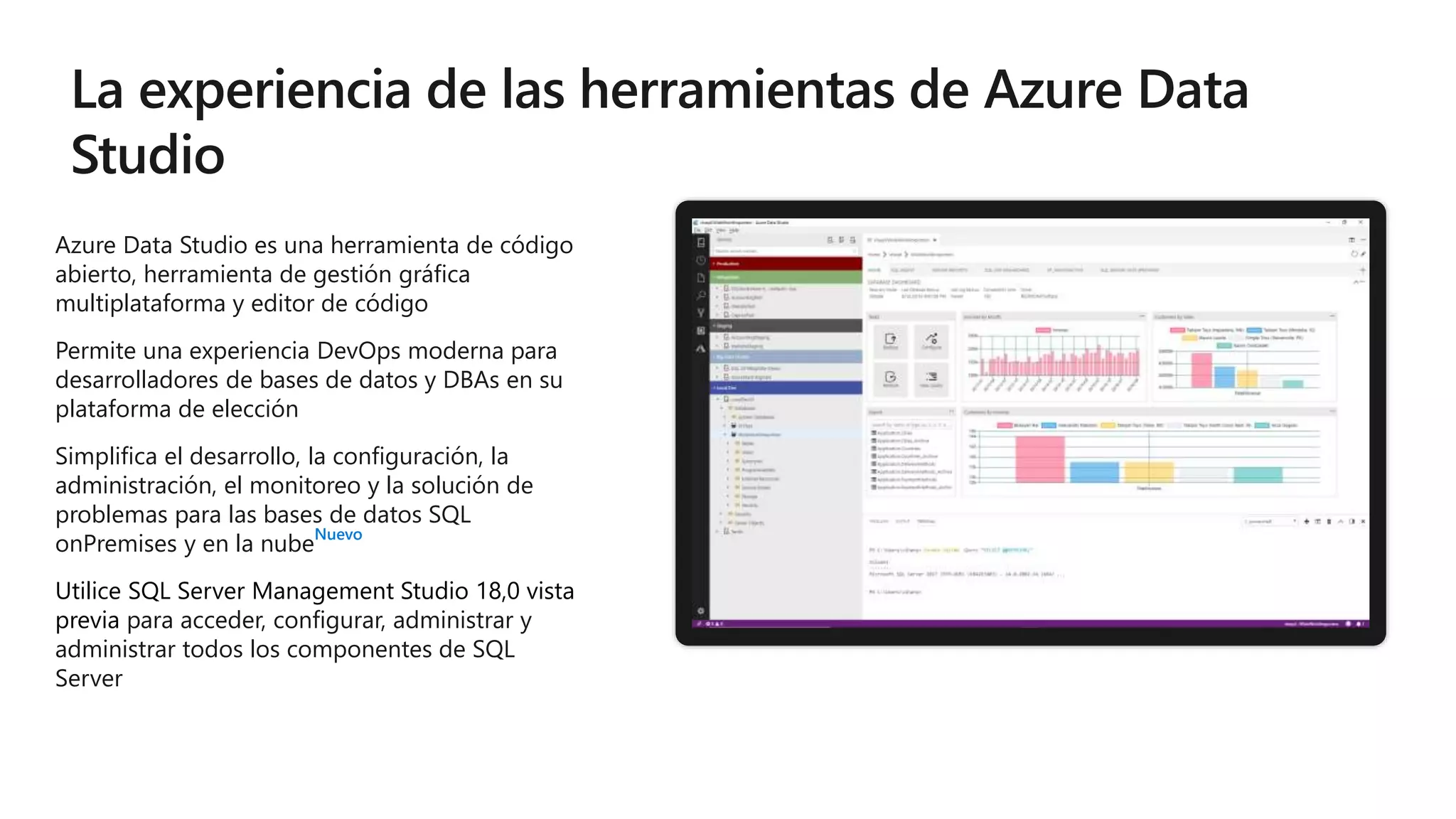

Este documento describe las capacidades y ventajas de SQL Server, incluyendo su rendimiento líder en la industria, seguridad mejorada, capacidades de inteligencia artificial y aprendizaje automático, y soporte para una variedad de cargas de trabajo y escenarios en la nube y localmente. SQL Server ofrece acceso unificado a todos los datos, administración simplificada y herramientas para crear aplicaciones inteligentes.



































































