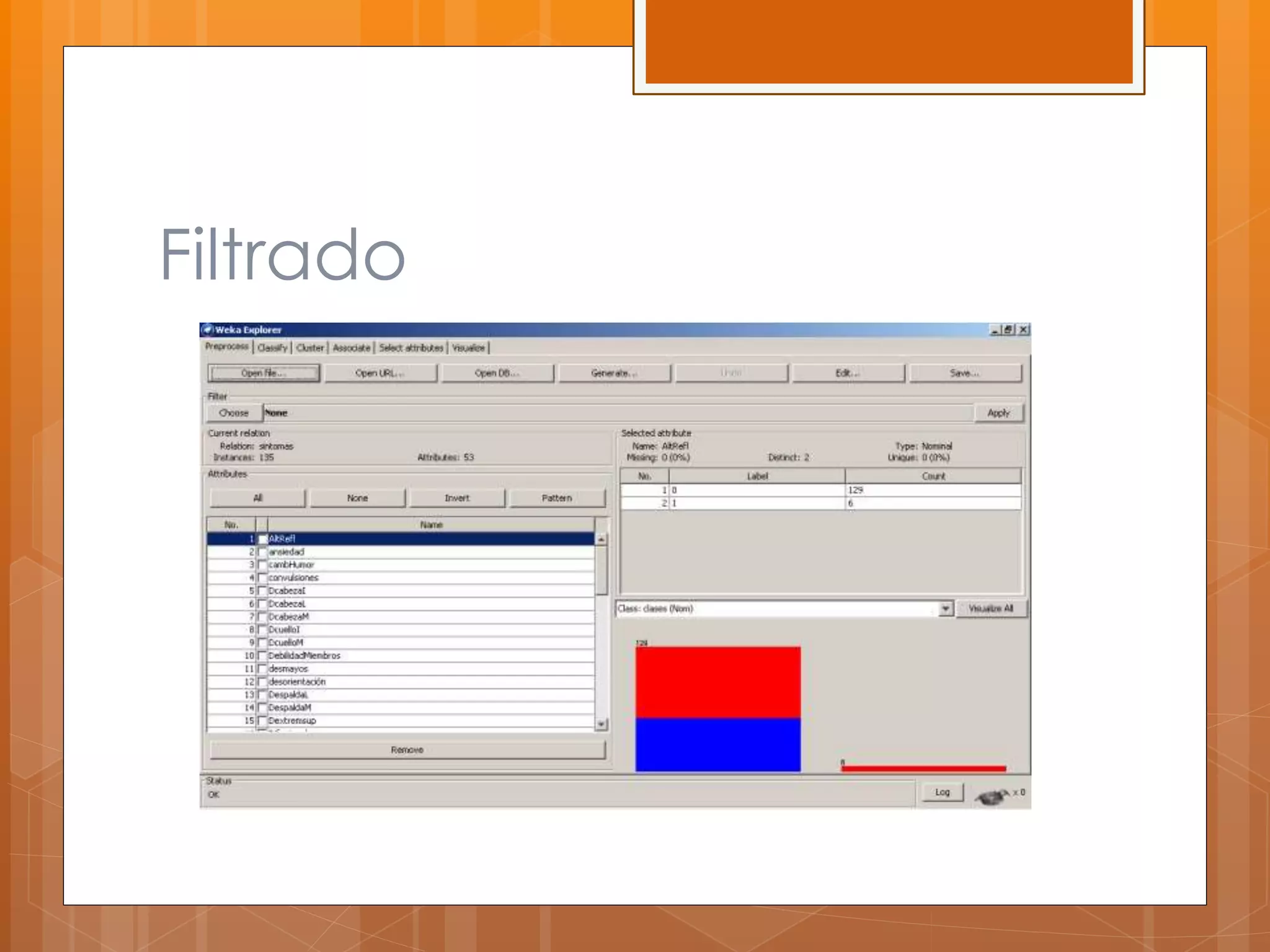
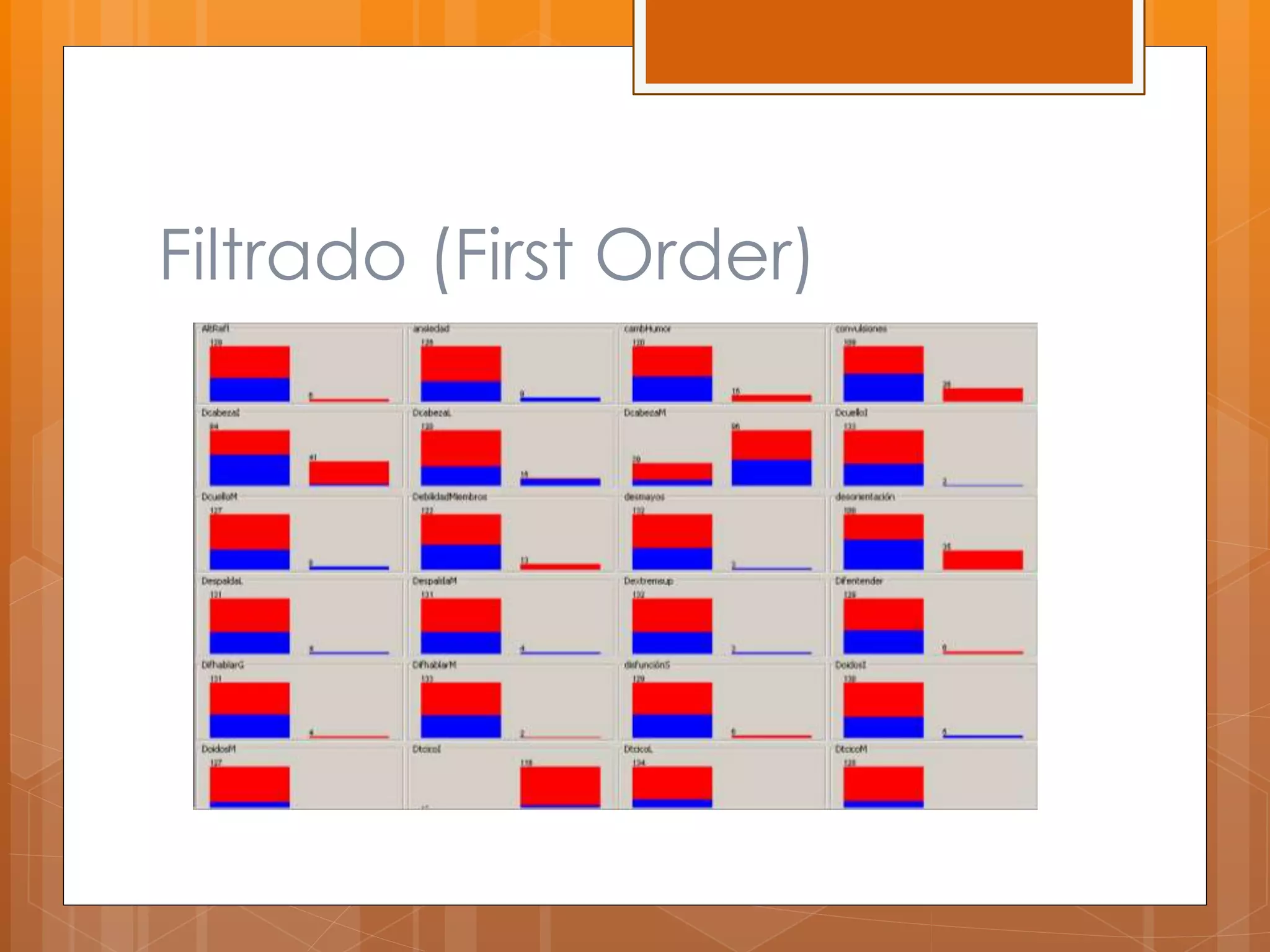
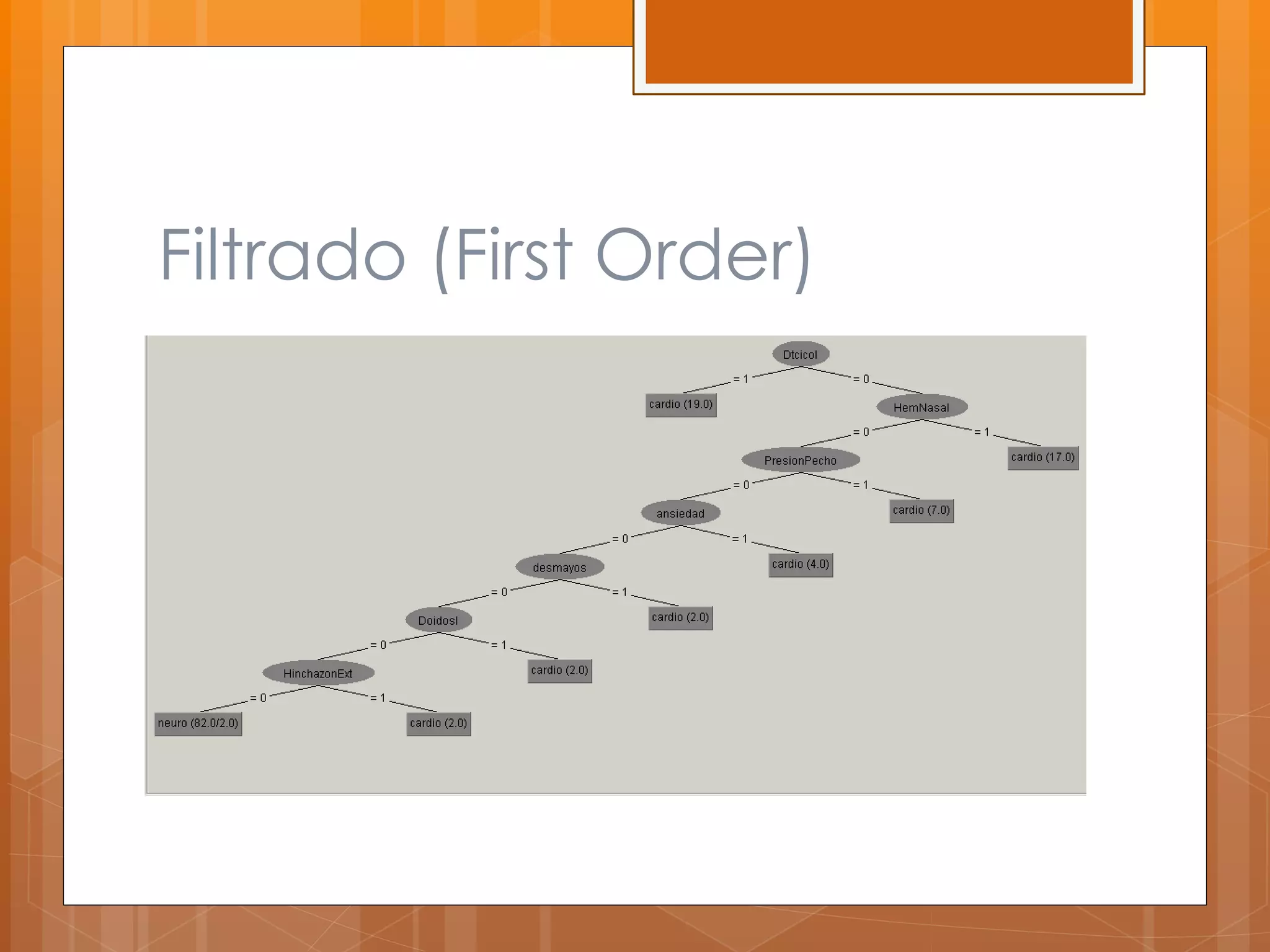
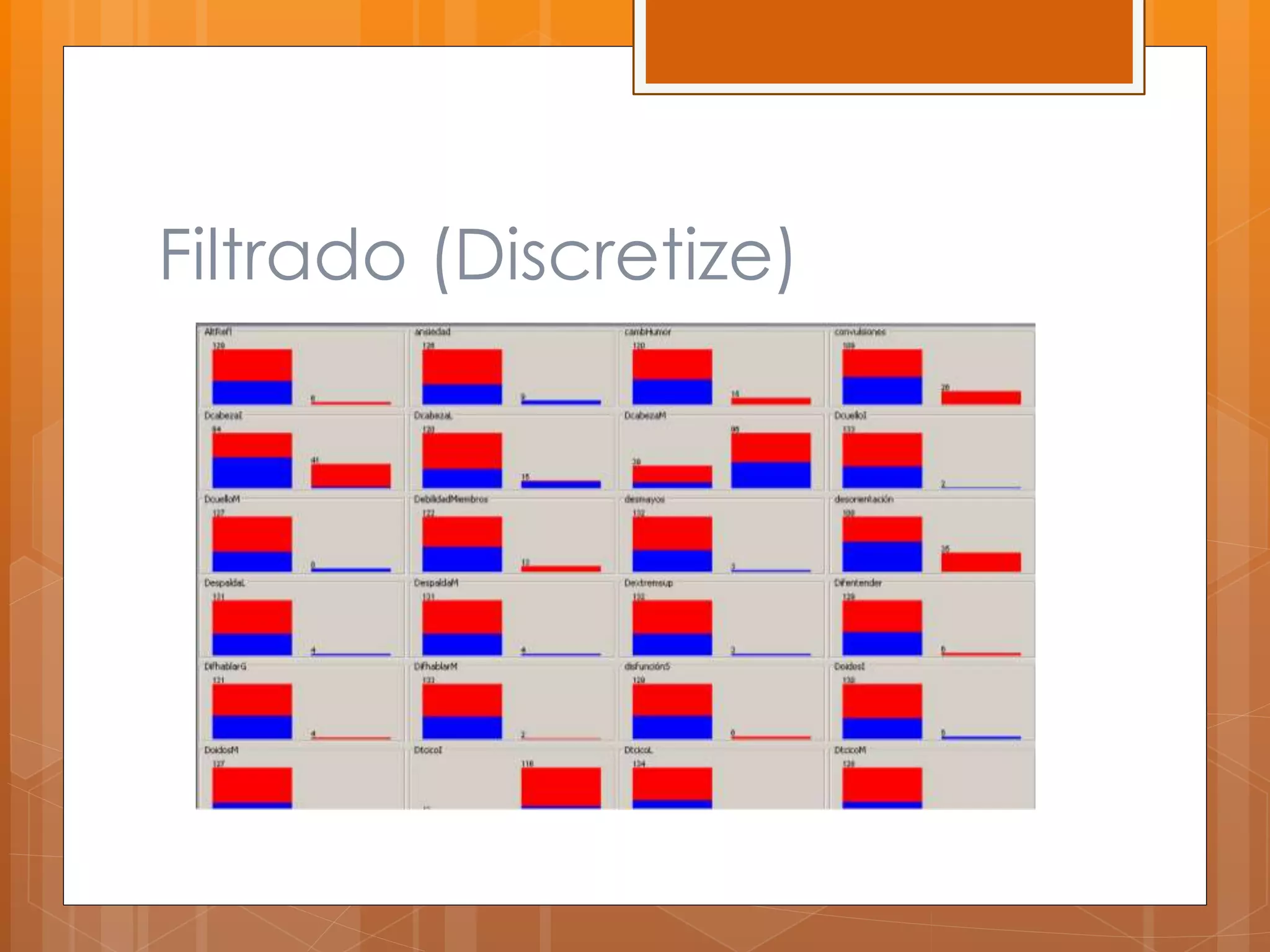
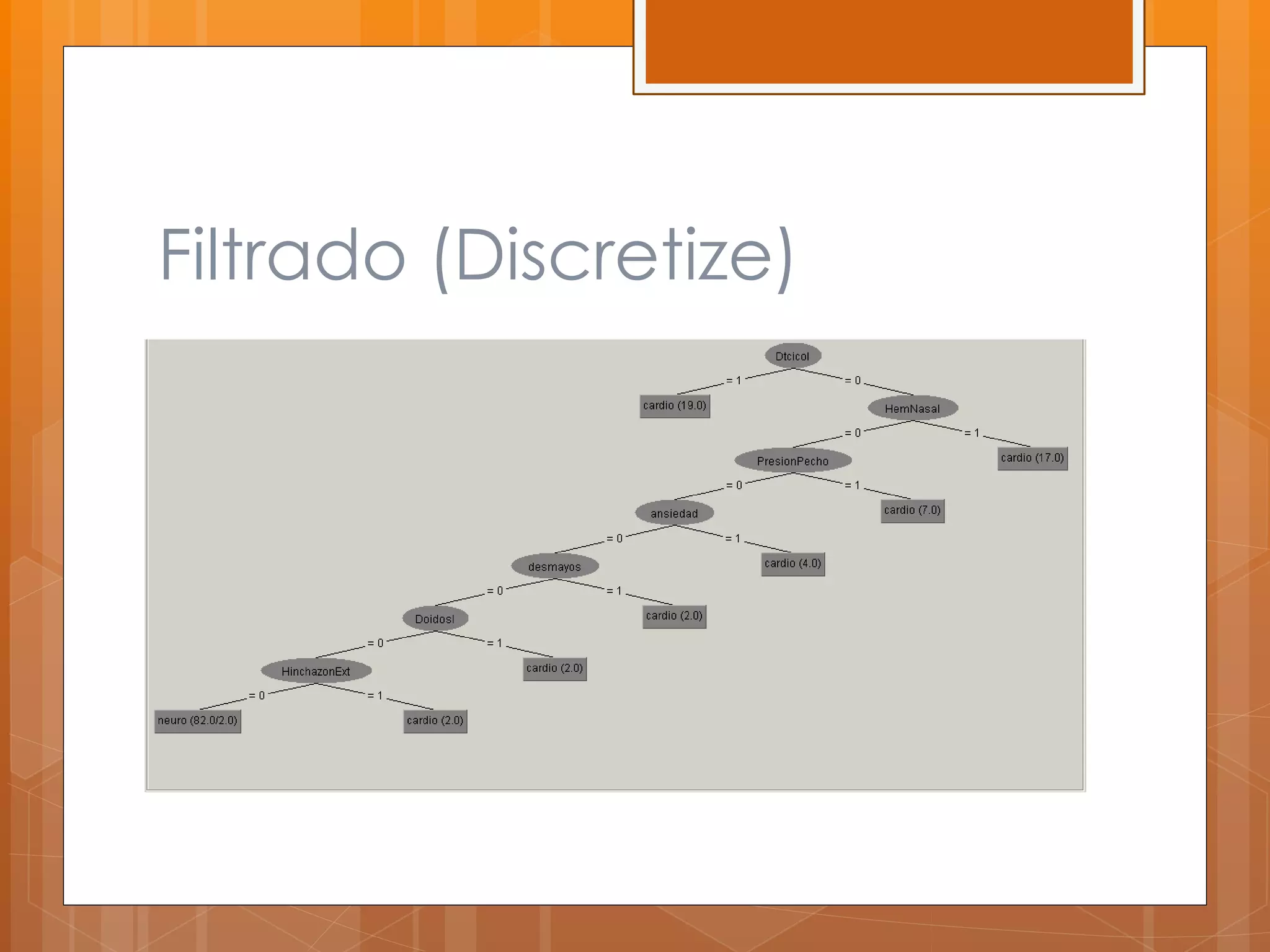
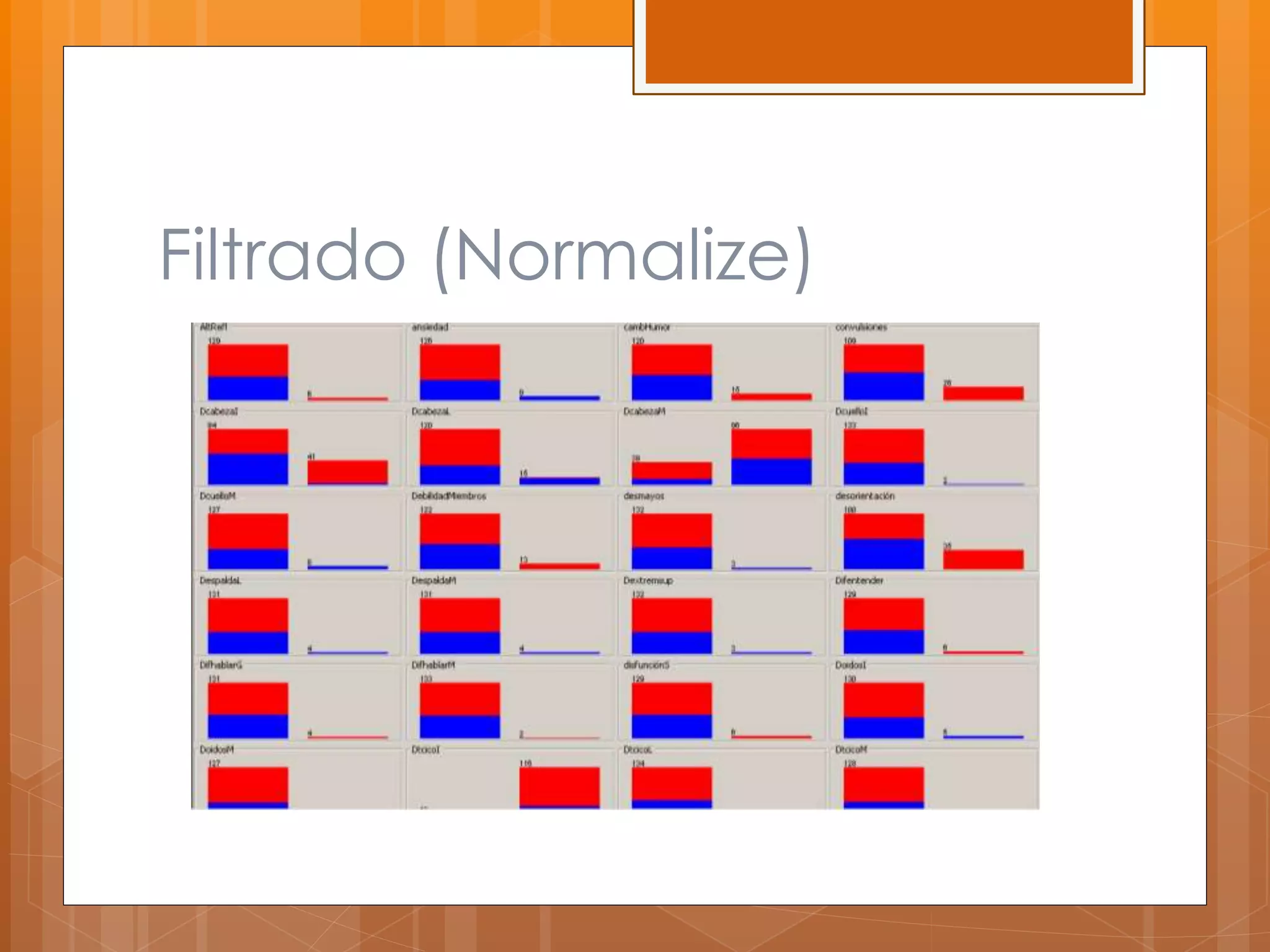
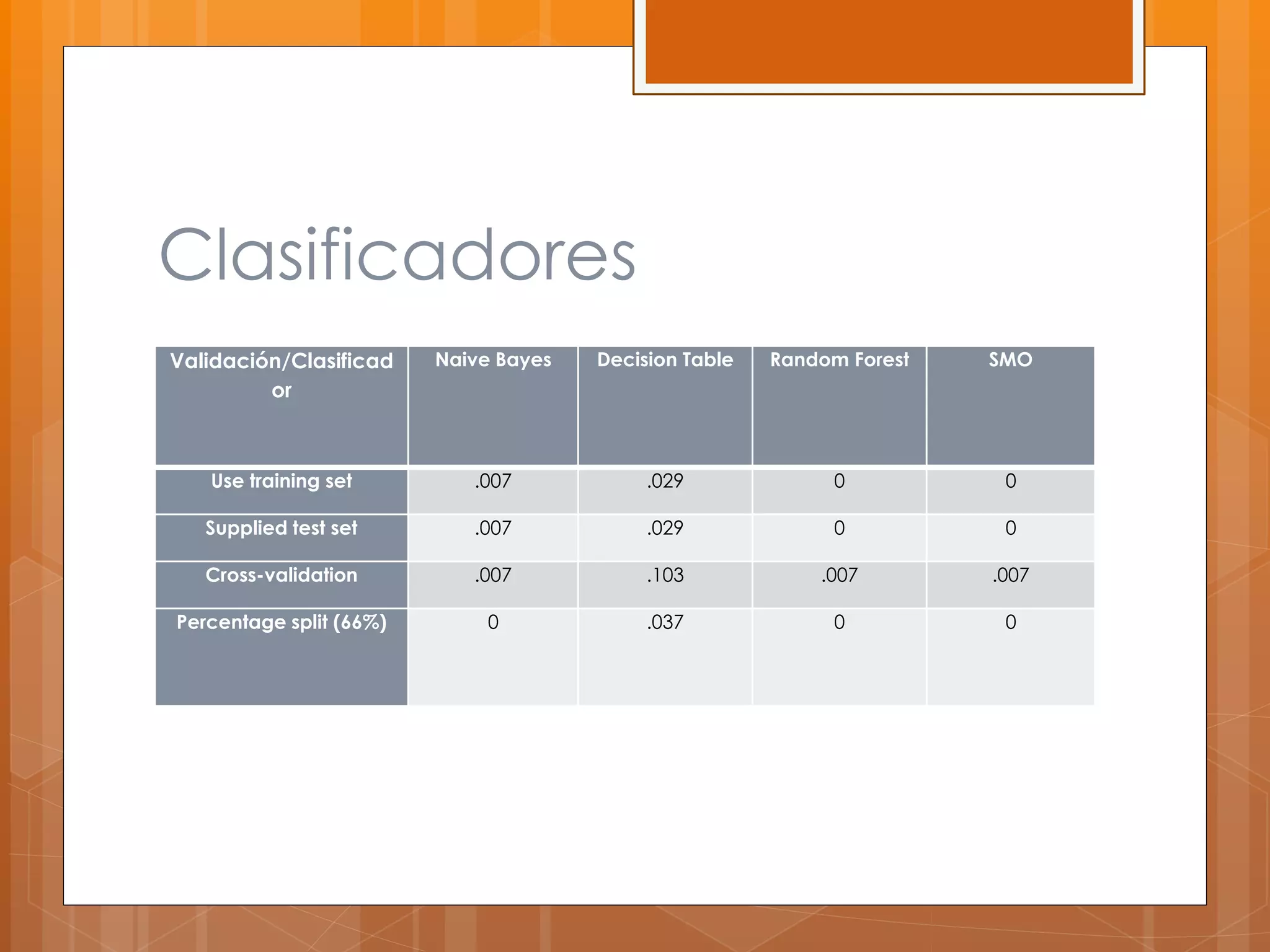
Este documento describe el desarrollo de un sistema para canalizar pacientes de emergencias a cardiología o neurología basado en el reconocimiento de patrones de sus síntomas. Se recolectaron datos de 97 pacientes con 100 atributos de síntomas, los cuales fueron limpiados y procesados para entrenar clasificadores que asignan pacientes a una de las dos especialidades médicas. Los resultados preliminares mostraron un margen de error de 0.059, pero se necesitan datos de pacientes reales para validar la efectividad del sistema.