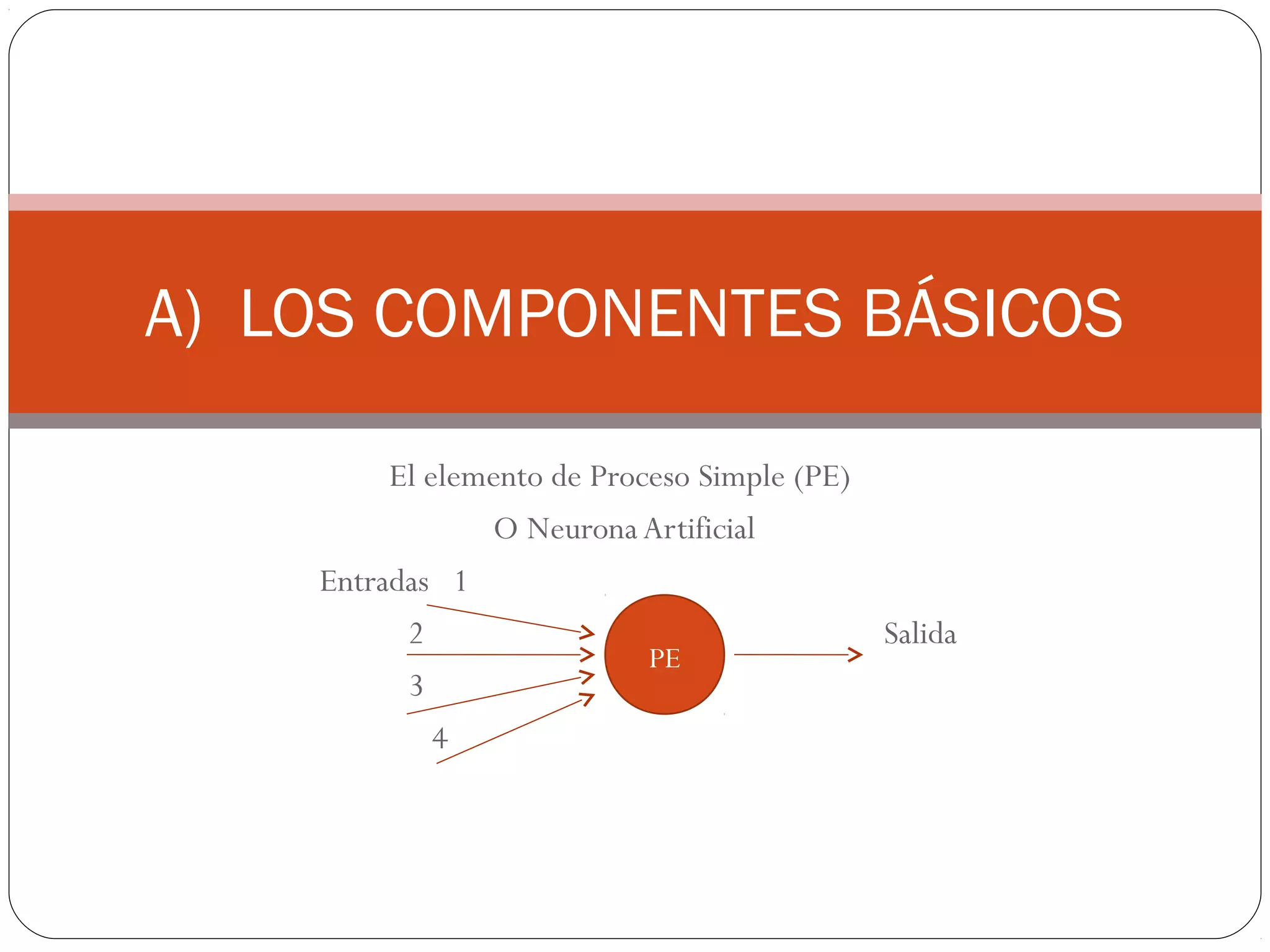
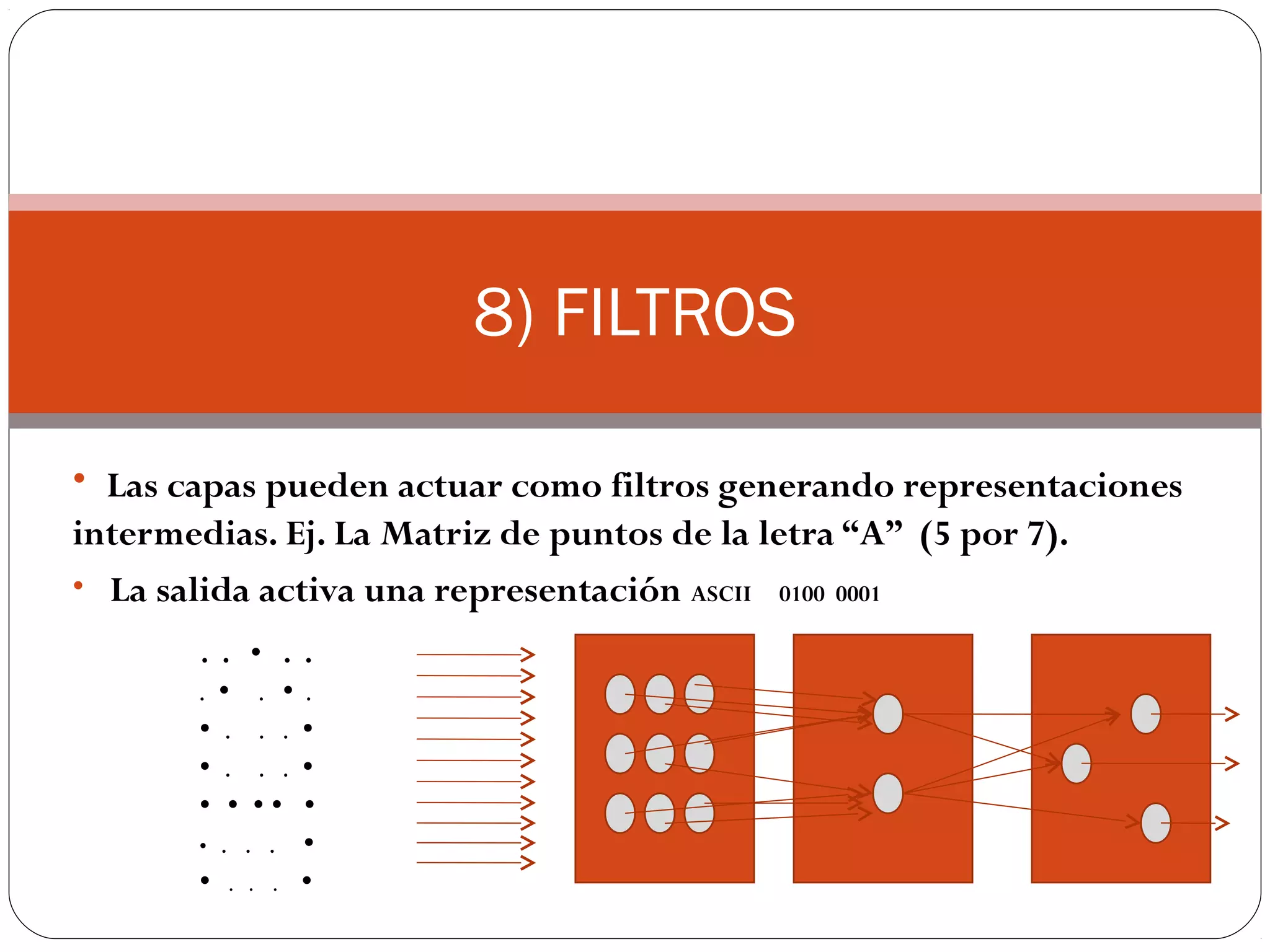
Este documento describe las redes neuronales artificiales, incluyendo su estructura, tipos de entrenamiento y aplicaciones. Explica que una neurona artificial proporciona una salida basada en una función de activación que combina las entradas ponderadas por pesos sinápticos. También describe redes multicapa y diferentes algoritmos de entrenamiento como backpropagation. Finalmente, presenta un ejemplo de cómo usar redes neuronales para la identificación de sistemas.