Descargar para leer sin conexión
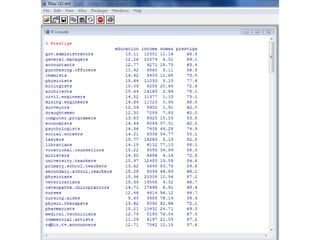



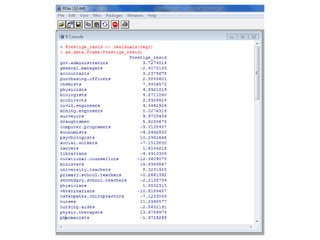



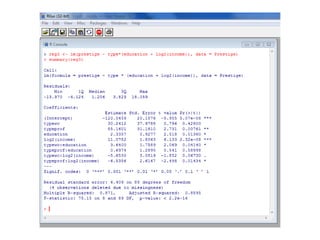



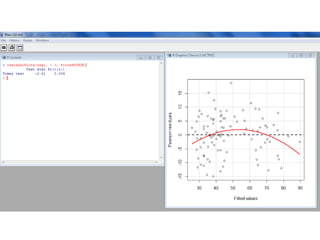








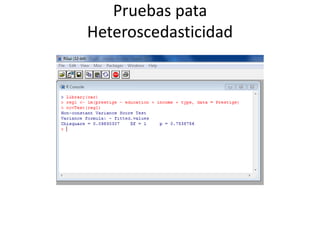

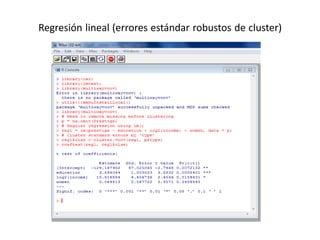


Este documento presenta varios métodos de regresión lineal como regresión lineal estándar, regresión con errores estándar robustos, predicción de valores y residuos, y regresión simulada sin interacciones. También describe diagnósticos como gráficos de residuos, variables de influencia, outliers, y pruebas de supuestos como normalidad y heterocedasticidad. Finalmente, enlista recursos en línea para aprender métodos de regresión en R y Stata.



































































