Descargado 31 veces




 {
def onStart() {
//Store()
}
def onStop() {
}
}
ssc.receiverStream(new MyReceiver(storageLevel(sparkStorageLevel)))
class MyActor extends Actor with ActorHelper{
def receive {
case anything: String => store(anything)
}
}
SPARK SDK](https://image.slidesharecdn.com/meetuprealtimeaggregations-sparkstreamingsparksql-160413150025/75/Meetup-Real-Time-Aggregations-Spark-Streaming-Spark-Sql-10-2048.jpg)
![REAL TIME AGGREGATION ENGINE: SPARK STREAMING + SPARK SQL
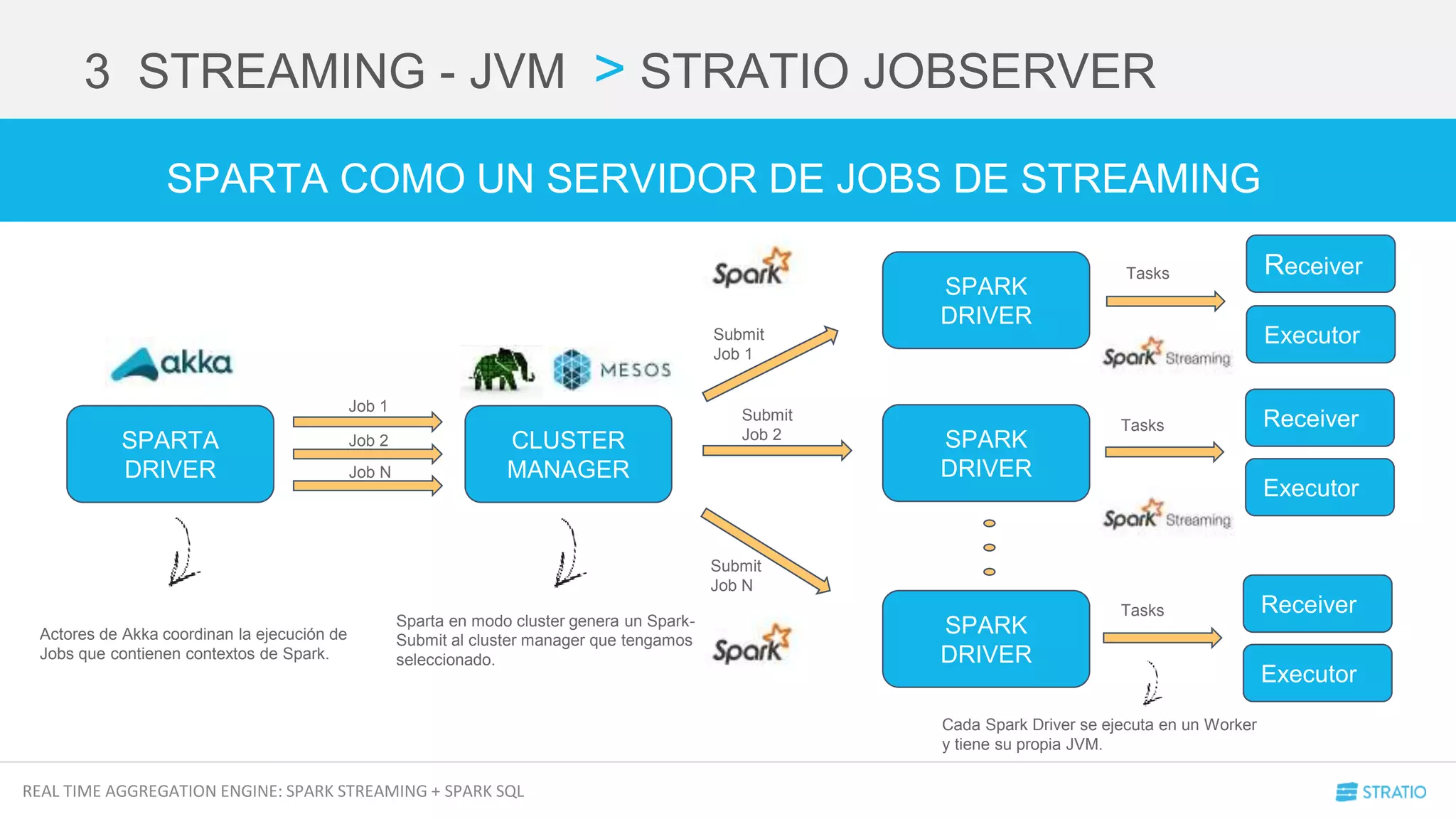
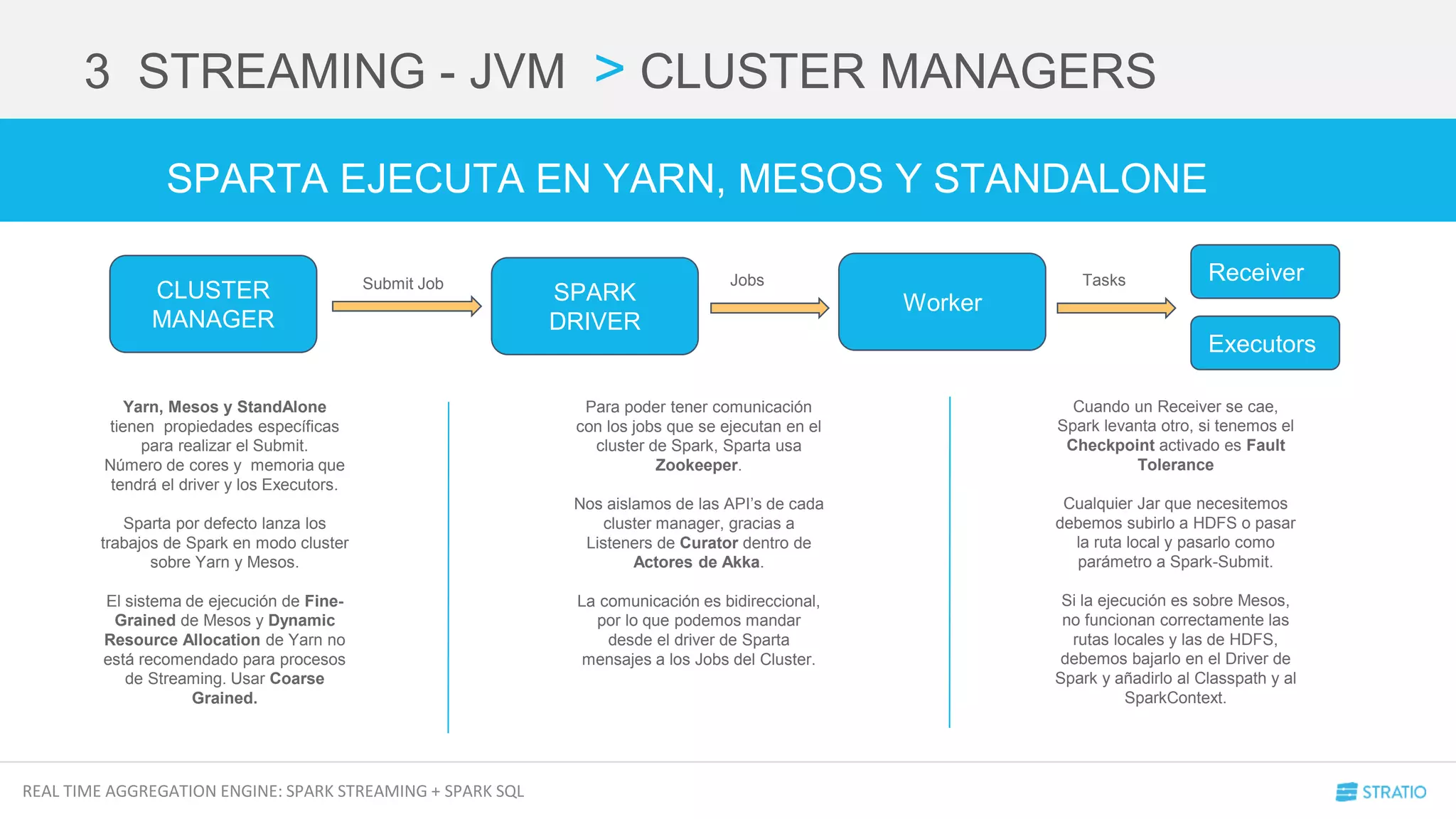
2 INPUTS > WEBSOCKET RECEIVER
abstract class Input(properties: Map[String, Any]) extends Parameterizable(properties) {
def setUp(ssc: StreamingContext, storageLevel: String): DStream[Row]
}
SPARTA INPUT SDK
FÁCIL VERDAD??
VEAMOS EL WEBSOCKET RECEIVER](https://image.slidesharecdn.com/meetuprealtimeaggregations-sparkstreamingsparksql-160413150025/75/Meetup-Real-Time-Aggregations-Spark-Streaming-Spark-Sql-11-2048.jpg)




![REAL TIME AGGREGATION ENGINE: SPARK STREAMING + SPARK SQL
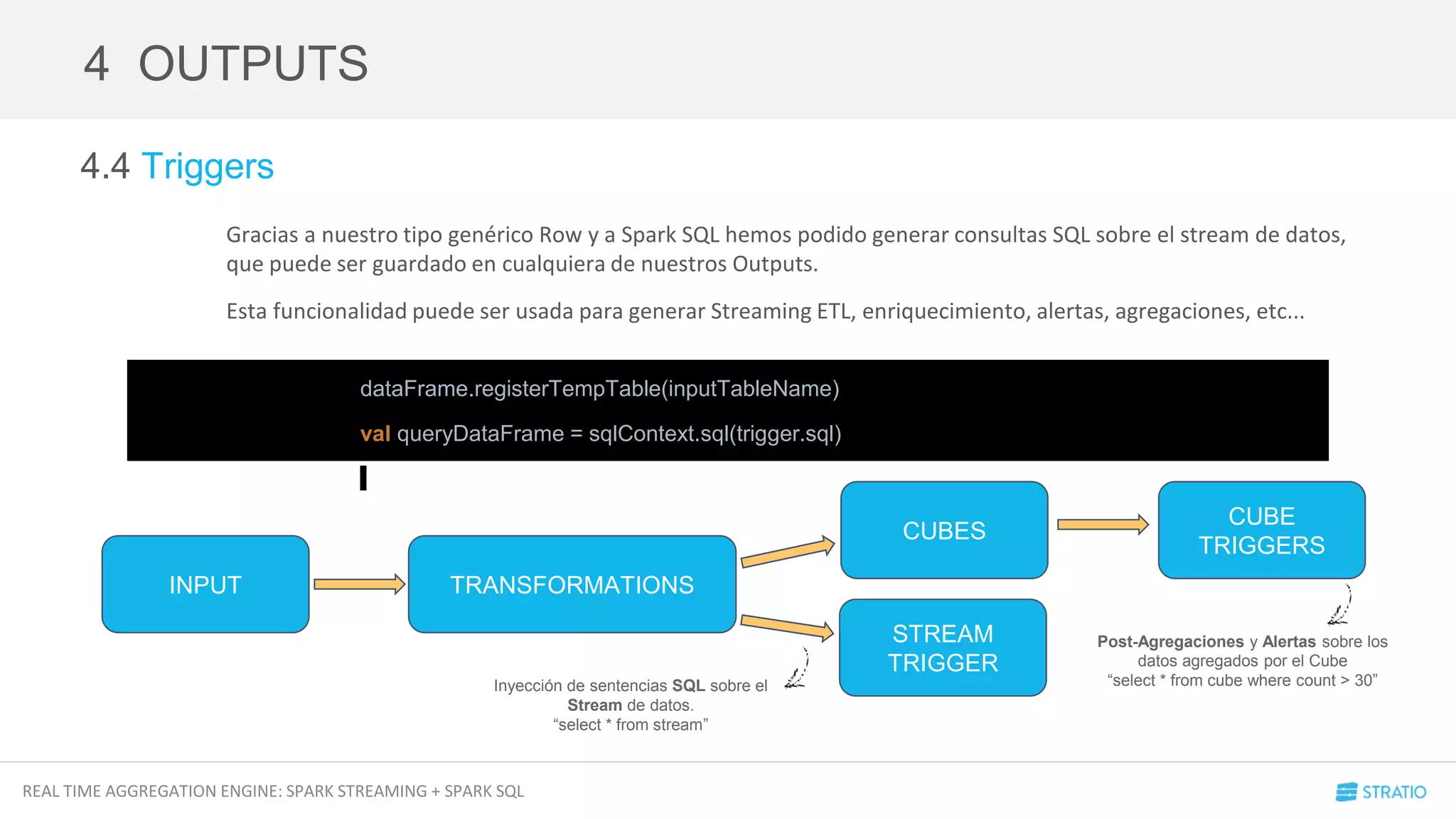
4.1 Transformaciones
Cuando trabajamos con DStream[T] podemos aplicar transformaciones como .map o .flatMap para modificar el
contenido del DStream y pasar del tipo T a una Clase de Scala.
Imaginad que nuestro String es un JSON, podemos hacer cosas como esta:
Todo esto es aplicable también a los RDD[T] de Spark.
4 OUTPUTS
val parsedDStream: DStream[Row] = originalDStream.map(data =>
Row(JSON.parseFull(data).get.asInstanceOf[Map[String, Any]].values))
val originalDStream: DStream[String]
val parsedDStream: DStream[Int] = originalDStream.map(data => Row(data))](https://image.slidesharecdn.com/meetuprealtimeaggregations-sparkstreamingsparksql-160413150025/75/Meetup-Real-Time-Aggregations-Spark-Streaming-Spark-Sql-21-2048.jpg)
![REAL TIME AGGREGATION ENGINE: SPARK STREAMING + SPARK SQL
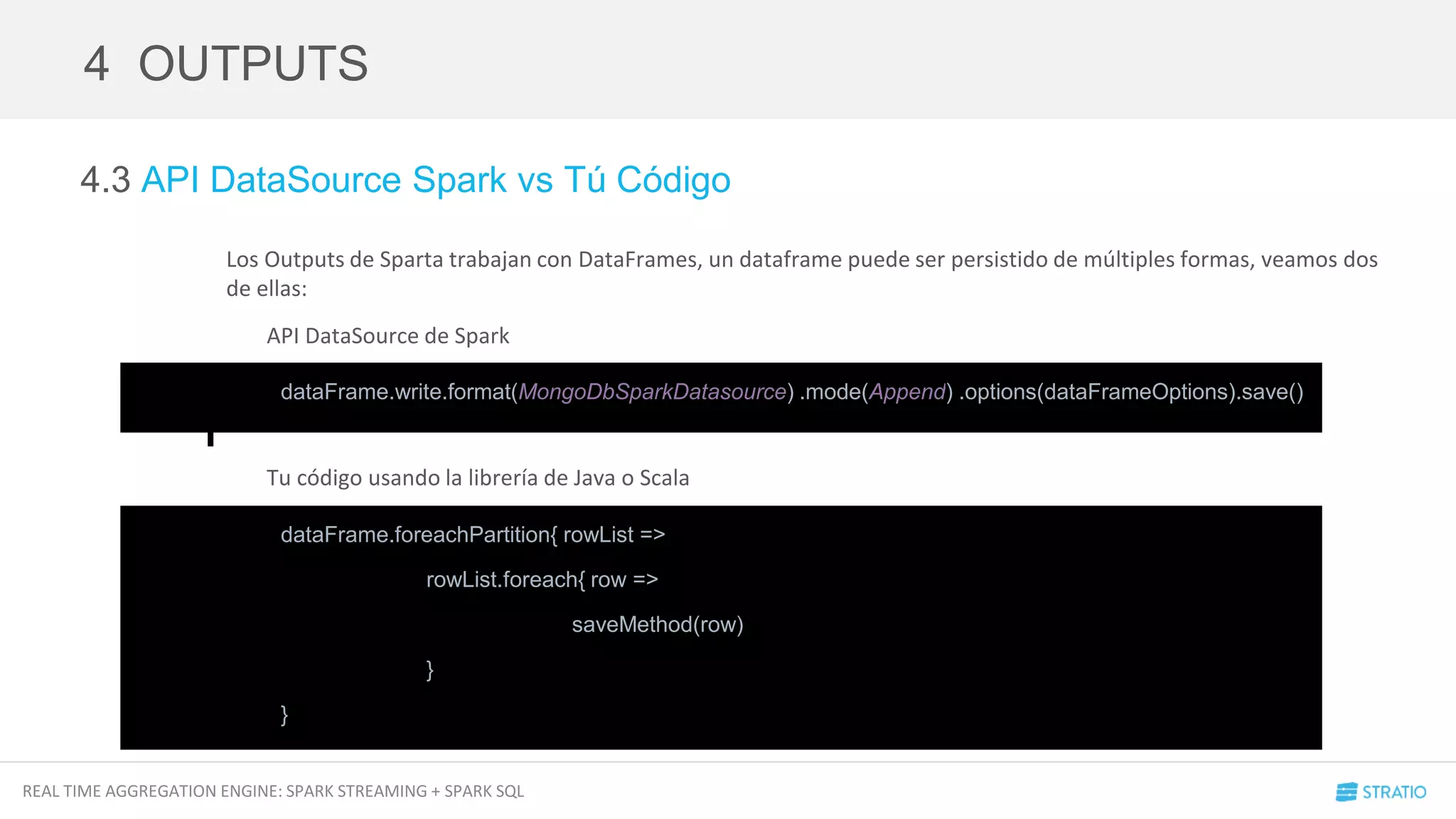
4.2 DataFrames
En Sparta hemos decidido generar un tipo de dato genérico para todas las entradas y salidas de cada uno de los
componentes del SDK.
Nuestro tipo genérico es la clase Row de Spark, de esta forma podemos generar DataFrames aplicando un Schema
en cualquier momento. Un DataFrame puede ser guardado por cualquiera de nuestros outputs con la función
upsert.
4 OUTPUTS
val schema: StructType
val output: Output
val parsedDStream: DStream[Row]
parsedDStream.foreachRDD(rdd =>
val parsedDataFrame = SQLContext.getOrCreate(rdd.context).createDataFrame(rdd, schema)
output.upsert(parsedDataFrame, dataFrameOptions)
)](https://image.slidesharecdn.com/meetuprealtimeaggregations-sparkstreamingsparksql-160413150025/75/Meetup-Real-Time-Aggregations-Spark-Streaming-Spark-Sql-22-2048.jpg)
![REAL TIME AGGREGATION ENGINE: SPARK STREAMING + SPARK SQL
4 OUTPUTS > DATAFRAMES
abstract class Output(
keyName: String,
version: Option[Int],
properties: Map[String, JSerializable],
schemas: Seq[TableSchema]
) extends Parameterizable(properties) with Logging {
def setup(options: Map[String, String] = Map.empty[String, String]): Unit = {}
def upsert(dataFrame: DataFrame, options: Map[String, String]): Unit
}
SPARTA OUTPUT SDK](https://image.slidesharecdn.com/meetuprealtimeaggregations-sparkstreamingsparksql-160413150025/75/Meetup-Real-Time-Aggregations-Spark-Streaming-Spark-Sql-23-2048.jpg)

![REAL TIME AGGREGATION ENGINE: SPARK STREAMING + SPARK SQL
5.1 Stateful
Cuando trabajamos con DStreams podemos pasar de tener un DStream a tener una secuencia de DStreams:
● Secuencia de elementos que determinan la configuración de una operación de Streaming con ventana de
tiempo y ventana de procesado.
● Podemos hacer un map sobre nuestra lista y por cada elemento podemos hacer transformaciones sobre el
DStream según los parámetros de nuestra clase.
● El resultado es una lista de DStreams para trabajar con ellos en conjunto… foreachRDD, DataFrames, Save,
Joins, etc...
5 OP. AVANZADAS DE STREAMING
val elements: Seq[MyConfigurationClass]
val originalDStream: DStream[Row]
val listOfDStream: Seq[DStream[Row]] = elements.map(element =>
originalDStream.window(element.window, element.slidingWindow))](https://image.slidesharecdn.com/meetuprealtimeaggregations-sparkstreamingsparksql-160413150025/75/Meetup-Real-Time-Aggregations-Spark-Streaming-Spark-Sql-27-2048.jpg)
 => Option[S]
): DStream[(K, S)] = ssc.withScope {
updateStateByKey(updateFunc, defaultPartitioner())
}
Queremos ir más allá …](https://image.slidesharecdn.com/meetuprealtimeaggregations-sparkstreamingsparksql-160413150025/75/Meetup-Real-Time-Aggregations-Spark-Streaming-Spark-Sql-28-2048.jpg)
]) => Iterator[(K, S)],
partitioner: Partitioner,
rememberPartitioner: Boolean
): DStream[(K, S)] = ssc.withScope {
new StateDStream(self, ssc.sc.clean(updateFunc), partitioner, rememberPartitioner,
None)
}
val stateRDD = prevStateRDD.mapPartitions(finalFunc, preservePartitioning)
Esta función es la que realiza la
modificación del estado según la Key](https://image.slidesharecdn.com/meetuprealtimeaggregations-sparkstreamingsparksql-160413150025/75/Meetup-Real-Time-Aggregations-Spark-Streaming-Spark-Sql-29-2048.jpg)
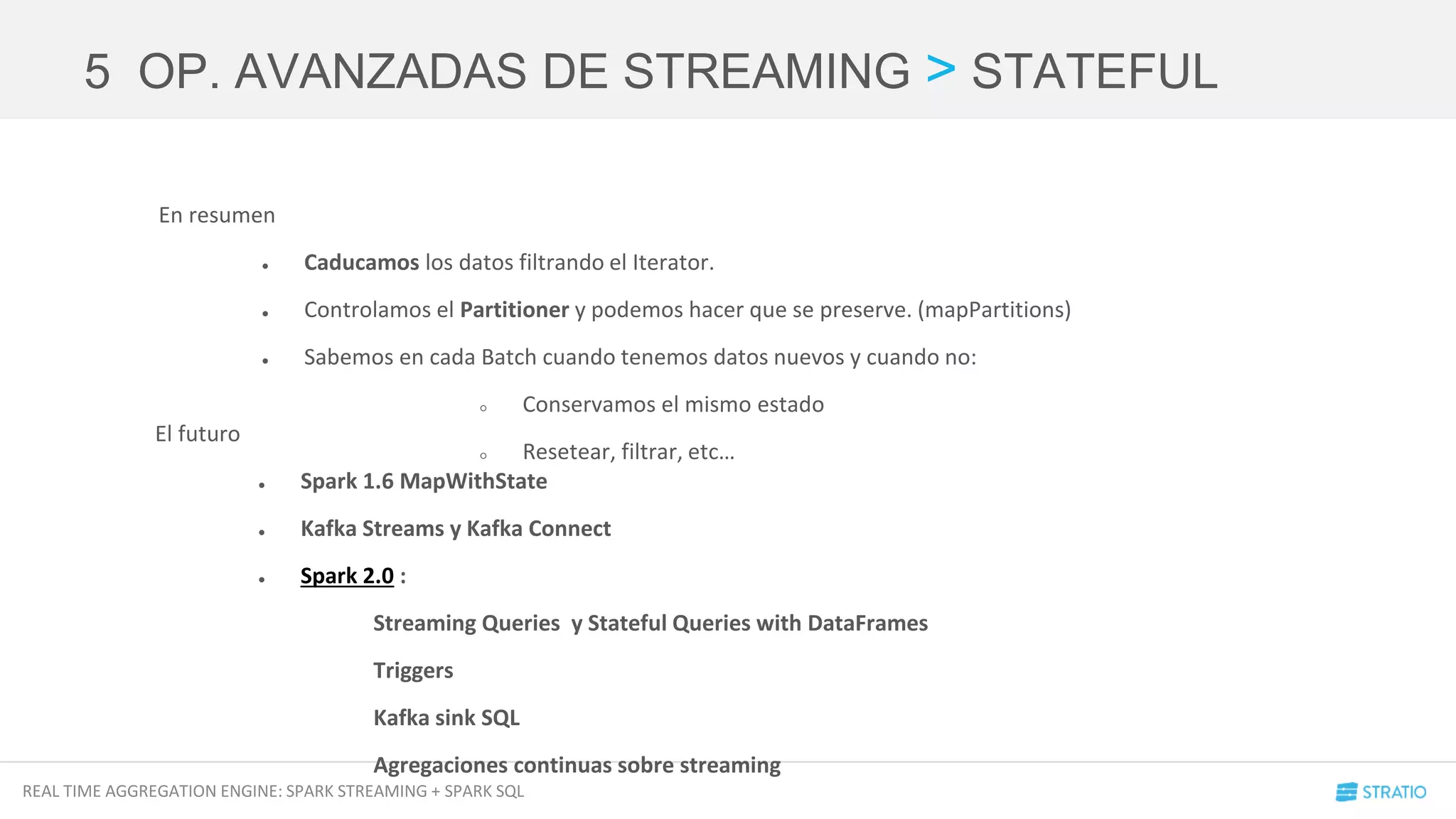
![REAL TIME AGGREGATION ENGINE: SPARK STREAMING + SPARK SQL
Cube de SPARTA
5 OP. AVANZADAS DE STREAMING > STATEFUL
protected def updateAssociativeState(dimensionsValues: DStream[(DimensionValuesTime,
AggregationsValues)])
: DStream[(DimensionValuesTime, MeasuresValues)] = {
val newUpdateFunc = expiringDataConfig match {
case None => updateFuncAssociativeWithoutTime
case Some(_) => updateFuncAssociativeWithTime
}
val valuesCheckpointed = dimensionsValues.updateStateByKey(
newUpdateFunc,
new HashPartitioner(dimensionsValues.context.sparkContext.defaultParallelism),
rememberPartitioner
)
filterUpdatedMeasures(valuesCheckpointed)
En base a la configuración ejecutamos una
función de agregación determinada
El DStream resultante es asignado a una variable que
puede es la entrada de otra función](https://image.slidesharecdn.com/meetuprealtimeaggregations-sparkstreamingsparksql-160413150025/75/Meetup-Real-Time-Aggregations-Spark-Streaming-Spark-Sql-31-2048.jpg)
![REAL TIME AGGREGATION ENGINE: SPARK STREAMING + SPARK SQL
5 OP. AVANZADAS DE STREAMING > STATEFUL
private def updateFuncAssociativeWithTime =
(iterator: Iterator[(DimensionValuesTime, Seq[AggregationsValues], Option[Measures])]) => {
iterator.filter {
case (DimensionValuesTime(_, _, Some(timeConfig)), _, _) =>
timeConfig.eventTime >= dateFromGranularity
case (DimensionValuesTime(_, _, None), _, _) =>
throw new IllegalArgumentException("Time configuration expected")
}.flatMap { case (dimensionsKey, values, state) =>
updateAssociativeFunction(values, state).map(result => (dimensionsKey, result))
}
}
Cube de SPARTA
Si filtramos en el Iterator estamos
caducando información
Dentro de esta función realizamos el cálculo y
actualizamos los estados de las keys](https://image.slidesharecdn.com/meetuprealtimeaggregations-sparkstreamingsparksql-160413150025/75/Meetup-Real-Time-Aggregations-Spark-Streaming-Spark-Sql-32-2048.jpg)


El documento presenta Stratio Sparta, un motor de agregación en tiempo real que combina Spark Streaming y Spark SQL. Describe la arquitectura, tecnologías utilizadas como Scala y Akka, así como las funcionalidades para receptores de datos, transformaciones, y operaciones avanzadas de streaming. Además, aborda problemas, recomendaciones y optimizaciones para el rendimiento en el manejo de datos en tiempo real.





![Fun[ctional] spark with scala](https://cdn.slidesharecdn.com/ss_thumbnails/functionalsparkwithscala-160614075814-thumbnail.jpg?width=640&height=640&fit=bounds)





![[Strata] Sparkta](https://cdn.slidesharecdn.com/ss_thumbnails/stratasparktav3-150507092440-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)























































