Descargar como PDF, PPTX









![parallelize( [1, 2, 3 …… x] )
RDD(Resilient Distributed Dataset)
[1, 2, 3 …… x]Regular Array
RDD
[1, 2, 3]
[4, 5, 6]
[6, 7, 8]
[…. x]
[1, 2, 3 …… x]
Partitions](https://image.slidesharecdn.com/bigdatameetup-150731155245-lva1-app6892/85/Data-crunching-con-Spark-12-320.jpg)
![Operaciones sobre RDDs
Transformaciones RDD RDD
Input RDD : [1, 2, 3 ,4 …]
f(x) = x + 1
Output RDD : [2, 3, 4 ,5 …]](https://image.slidesharecdn.com/bigdatameetup-150731155245-lva1-app6892/85/Data-crunching-con-Spark-13-320.jpg)
![Operaciones sobre RDDs
Acciones RDD Valor
Input RDD : [1, 2, 3 ,4]
sum
Output : 10](https://image.slidesharecdn.com/bigdatameetup-150731155245-lva1-app6892/85/Data-crunching-con-Spark-14-320.jpg)
![ResilentDD
Resilient: [1, 2, 3]
[4, 5, 6] [6, 7, 8]
[…. x]
[1, 2, 3]
[4, 5, 6]
[1, 2, 3, 7]
[4, 5, 6, 8]
[…. x]
Driver
Driver](https://image.slidesharecdn.com/bigdatameetup-150731155245-lva1-app6892/85/Data-crunching-con-Spark-15-320.jpg)
![val datosArchivo =
sc.textFile(“/Path/toFile“)
[Linea1,
Linea2,
Linea3…]
[Linea4, Linea5…]
[…. Linea x]
Driver](https://image.slidesharecdn.com/bigdatameetup-150731155245-lva1-app6892/85/Data-crunching-con-Spark-16-320.jpg)
![val palabras = datosArchivo.flatMap{
line =>
line.split(" ")
}
Linea1: Hola Mundo
Linea2: Hello World
[“Hola”, “Mundo”]
[“Hello”, “World”]
split
split
flatten
[“Hello”, “World”, “Hola”, “Mundo”]
[Hello, World,…]
[Hola,…]
[….,Mundo ]Driver](https://image.slidesharecdn.com/bigdatameetup-150731155245-lva1-app6892/85/Data-crunching-con-Spark-17-320.jpg)
![val soloPalabrasValle =
palabras.filter(_.toLowerCase()=="valle")
[Hello, World,…]
[c++…. valle ]
[Valle,…]
Driver](https://image.slidesharecdn.com/bigdatameetup-150731155245-lva1-app6892/85/Data-crunching-con-Spark-18-320.jpg)
![val numeroOcurrenciasValle =
soloPalabrasValle.map(palabra => 1).reduce(_+_)
[valle, valle, Valle ..]
map
[1, 1, 1 ….]
[1, 1, 1…1 ]
reduce
( (1 + 1) + 1 ) + 1)
Total: 10
Driver](https://image.slidesharecdn.com/bigdatameetup-150731155245-lva1-app6892/85/Data-crunching-con-Spark-19-320.jpg)
![{
"Creaci√ón de Proceso": "24 de June de 2015 10:50 A.M.",
"Objeto del Contrato": "Prestacion de servicios profesionales como como medico general, en las condiciones, areas
servicios requeridos",
"Estado del Contrato": "Celebrado",
"Correo Electr√ónico": "contratacion@esesanantoniodepadua.gov.co",
"Fecha de Inicio de Ejecuci√ón del Contrato": "02 de mayo de 2015",
"Grupo": "[F] Servicios",
"Tipo de Contrato": "Prestaci√ón de Servicios",
"Identificaci√ón del Representante Legal": "C√édula de Ciudadanía No. 1.110.479.226 Ibagu√é",
"Departamento y Municipio de Ejecuci√ón": "Huila : La Plata",
"Cuantía Definitiva del Contrato": "$12,000,000 Peso Colombiano",
"documents": [
{
"publication_date": "24-06-2015 11:03 AM",
"url": "/cloud/cloud2/2015/DA/241396015/15-4-3967699/DA_PROCESO_15-4-3967699_241396015_15194469.pdf",
"name": "Documento Adicional",
"description": "ACTA INICIO"
},
{
"publication_date": "24-06-2015 11:02 AM",
"url": "/cloud/cloud2/2015/C/241396015/15-4-3967699/C_PROCESO_15-4-3967699_241396015_15194424.pdf",
"name": "Contrato",
"description": ""
}
],
"Identificaci√ón del Contratista": "C√édula de Ciudadanía No. 1.110.479.226 Ibagu√é",
"Nombre o Raz√ón Social del Contratista": "GERMAN EDUARDO SILVA BONILLA",
"Nombre del Representante Legal del Contratista": "GERMAN EDUARDO SILVA BONILLA",
"Segmento": "[85] Servicios de Salud",
"Plazo de Ejecuci√ón del Contrato": "2 Meses",
"Celebraci√ón de Contrato": "24 de June de 2015 11:04 A.M.",
"Estado del Proceso": "Celebrado",
"Clase": "[851016] Personas de soporte de prestaci√ón de servicios de salud",
"Cuantía a Contratar": "$12,000,000",
"RÎgimen de Contrataci×n": "ESE HOSPITAL",
"Destinaci√ón del Gasto": "No Aplica",
"Tipo de Proceso": "RÎgimen Especial",
"Detalle y Cantidad del Objeto a Contratar": "Prestacion de servicios profesionales como como medico general, en
condiciones, areas y servicios requeridos",
"Fecha de Firma del Contrato": "30 de abril de 2015",
Datos](https://image.slidesharecdn.com/bigdatameetup-150731155245-lva1-app6892/85/Data-crunching-con-Spark-20-320.jpg)






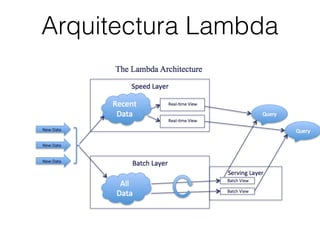
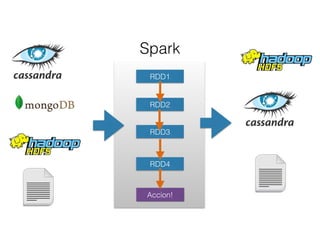
El documento aborda el uso de Spark, un marco de trabajo para procesar grandes volúmenes de datos, comparándolo con Hadoop y destacando su capacidad para realizar análisis en tiempo real y su integración con diversas tecnologías. Se discuten casos de uso, como la exploración de datos masivos y el procesamiento en sistemas de producción, mencionando usuarios importantes como Netflix y IBM. Además, se sugiere que los interesados en Spark deberían aprender sobre programación funcional, DataFrames y técnicas de machine learning.




![Protocolo tutor primaria[1]](https://cdn.slidesharecdn.com/ss_thumbnails/protocolotutorprimaria1-150604151934-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)






























![Meetup Fun[ctional] spark with scala](https://cdn.slidesharecdn.com/ss_thumbnails/functionalsparkwithscala-180524102236-thumbnail.jpg?width=640&height=640&fit=bounds)
![Fun[ctional] spark with scala](https://cdn.slidesharecdn.com/ss_thumbnails/functionalsparkwithscala-160614075814-thumbnail.jpg?width=640&height=640&fit=bounds)




































