Estructura primaria de las proteínas (1)
•Descargar como DOCX, PDF•
0 recomendaciones•799 vistas


Recomendados
Recomendados
Más contenido relacionado
La actualidad más candente
La actualidad más candente (20)
Similar a Estructura primaria de las proteínas (1)
Similar a Estructura primaria de las proteínas (1) (20)
Estructura primaria de las proteínas (1)
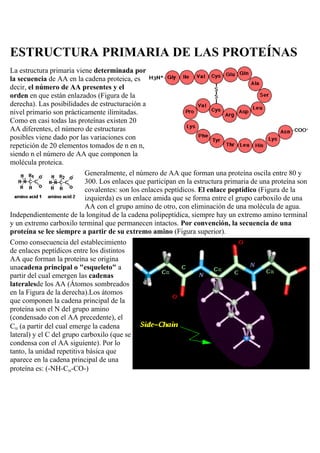
- 1. ESTRUCTURA PRIMARIA DE LAS PROTEÍNAS La estructura primaria viene determinada por la secuencia de AA en la cadena proteica, es decir, el número de AA presentes y el orden en que están enlazados (Figura de la derecha). Las posibilidades de estructuración a nivel primario son prácticamente ilimitadas. Como en casi todas las proteínas existen 20 AA diferentes, el número de estructuras posibles viene dado por las variaciones con repetición de 20 elementos tomados de n en n, siendo n el número de AA que componen la molécula proteica. Generalmente, el número de AA que forman una proteína oscila entre 80 y 300. Los enlaces que participan en la estructura primaria de una proteína son covalentes: son los enlaces peptídicos. El enlace peptídico (Figura de la izquierda) es un enlace amida que se forma entre el grupo carboxilo de una AA con el grupo amino de otro, con eliminación de una molécula de agua. Independientemente de la longitud de la cadena polipeptídica, siempre hay un extremo amino terminal y un extremo carboxilo terminal que permanecen intactos. Por convención, la secuencia de una proteína se lee siempre a partir de su extremo amino (Figura superior). Como consecuencia del establecimiento de enlaces peptídicos entre los distintos AA que forman la proteína se origina unacadena principal o "esqueleto" a partir del cual emergen las cadenas lateralesde los AA (Átomos sombreados en la Figura de la derecha).Los átomos que componen la cadena principal de la proteína son el N del grupo amino (condensado con el AA precedente), el C (a partir del cual emerge la cadena lateral) y el C del grupo carboxilo (que se condensa con el AA siguiente). Por lo tanto, la unidad repetitiva básica que aparece en la cadena principal de una proteína es: (-NH-C -CO-)
- 2. Como la estructura primaria es la que determina los niveles superiores de organización, el conocimiento de la secuencia de AA es del mayor interés para el estudio de la estructura y función de una proteína. Clásicamente, la secuenciación de una proteína se realiza mediante métodos químicos. El método más utilizado es el de Edman, que utiliza el fenilisotiocianato para marcar la proteína (representado en la Figura de la izquierda como un triángulo) e iniciar una serie de reacciones cíclicas que permiten identificar cada AA de la secuencia empezando por el extremo amino. Hoy en día esta serie de reacciones las realiza de forma automática un aparato llamado secuenciador de AA. Los avances de la Biología Molecular permiten conocer la secuencia de un gen mucho antes de que se haya podido purificar la proteína que codifica. El análisis de la secuencia del DNA permite secuenciar una proteína sin que se haya purificado previamente, ya que cada grupo de tres bases de la secuencia del DNA especifica un aminoácido. El Código Genético establece para cada grupo de tres nucleótidos (codón) el AA que codifica. En la Tabla de la derecha, la letra sobre fondo rosáceo corresponde a la primera base del codón, la letra sobre fondo morado a la segunda, y la letra sobre fondo amarillo a la tercera. El Código Genético es de validez universal, ya que es el mismo para todos los seres vivos. Pincha en el icono pdf para ver un artículo de Nature sobre el código genético ( ). U C A G U Phe Ser Tyr Cys U Phe Ser Tyr Cys C Leu Ser STOP STOP A Leu Ser STOP Trp G C Leu Pro His Arg U Leu Pro His Arg C Leu Pro Gln Arg A Leu Pro Gln Arg G A Ile Thr Asn Ser U Ile Thr Asn Ser C Ile Thr Lys Arg A Met Thr Lys Arg G G Val Ala Asp Gly U Val Ala Asp Gly C Val Ala Glu Gly A Val Ala Glu Gly G U C A G
- 3. La comparación de la estructura primaria de una misma proteína en especies diversas tiene un enorme interés desde los puntos de vista funcional y filogenético. Cuanto más alejadas estén las especies analizadas en el árbol filogenético, más diferencias se podrán observar en la estructura primaria de proteínas análogas. Así, si comparamos las secuencias del citocromo c de diversas especies, y determinamos cuántos AA son distintos entre cada pareja, se puede construir una matriz como la de la Figura inferior, a partir de la cual se podrá establecer el árbol filogenético que nos indica para el caso de la proteína citocromo c, cómo ha ido evolucionando a medida que aparecen nuevas especies. Número de AA distintos en las moléculas de citocromo c de cada pareja estudiada Árbol filogenético del citocromo c
- 4. Sin embargo, a menudo se encuentra que el mismo aminoácido aparece siempre en idéntica posición en todas las especies estudiadas. Estos AA reciben el nombre de AA invariantes o AA conservados, y suelen ser indispensables para la función y estructura correcta de la proteína. Cualquier mutación en estas posiciones es letal para el organismo, y por tanto hay una fortísima selección en contra. En la Figura inferior se muestra la comparación de las secuencias de los primeros 50AA de la proteína Troponina C. Los AA conservados están sombreados en negro.