Descargado 430 veces




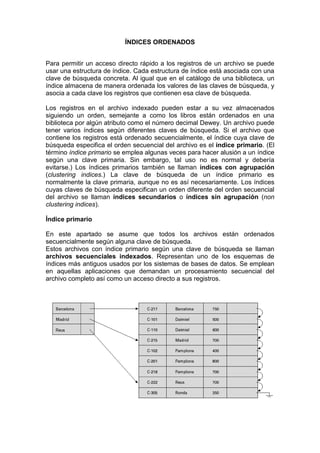











Este documento describe las técnicas de indexación y asociación para realizar consultas en bases de datos mediante SQL. Explica conceptos básicos como índices ordenados y asociativos, y tipos de acceso. Luego detalla índices ordenados, primarios, densos y dispersos, así como actualizaciones de índices y estructuras como índices multinivel y de árbol B+.


















































































