Pauta i2
•
0 recomendaciones•292 vistas

Este documento presenta tres preguntas de una prueba de bioestadística. La primera pregunta evalúa la hipótesis de que la complejidad del hábitat determina el tamaño relativo del cerebro en mamíferos. Los datos apoyan rechazar la hipótesis nula de independencia entre las variables. La segunda pregunta analiza la relación entre el tamaño del cerebro y el tamaño del cuerpo, concluyendo que existe una relación lineal significativa. La tercera pregunta examina si el período reproductivo determina el estrés

Más contenido relacionado
Similar a Pauta i2
Similar a Pauta i2 (20)
Pauta i2
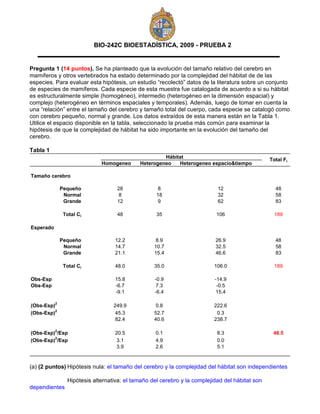
- 1. BIO-242C BIOESTADÍSTICA, 2009 - PRUEBA 2 Pregunta 1 (14 puntos). Se ha planteado que la evolución del tamaño relativo del cerebro en mamíferos y otros vertebrados ha estado determinado por la complejidad del hábitat de de las especies. Para evaluar esta hipótesis, un estudio “recolectó” datos de la literatura sobre un conjunto de especies de mamíferos. Cada especie de esta muestra fue catalogada de acuerdo a si su hábitat es estructuralmente simple (homogéneo), intermedio (heterogéneo en la dimensión espacial) y complejo (heterogéneo en términos espaciales y temporales). Además, luego de tomar en cuenta la una “relación” entre el tamaño del cerebro y tamaño total del cuerpo, cada especie se catalogó como con cerebro pequeño, normal y grande. Los datos extraídos de esta manera están en la Tabla 1. Utilice el espacio disponible en la tabla, seleccionado la prueba más común para examinar la hipótesis de que la complejidad de hábitat ha sido importante en la evolución del tamaño del cerebro. Tabla 1 Hábitat Total Fi Homogeneo Heterogeneo Heterogeneo espacio&tiempo Tamaño cerebro Pequeño 28 8 12 48 Normal 8 18 32 58 Grande 12 9 62 83 Total Ci 48 35 106 189 Esperado Pequeño 12.2 8.9 26.9 48 Normal 14.7 10.7 32.5 58 Grande 21.1 15.4 46.6 83 Total Ci 48.0 35.0 106.0 189 Obs-Esp 15.8 -0.9 -14.9 Obs-Esp -6.7 7.3 -0.5 -9.1 -6.4 15.4 (Obs-Esp)2 249.9 0.8 222.6 (Obs-Esp)2 45.3 52.7 0.3 82.4 40.6 238.7 (Obs-Esp)2/Esp 20.5 0.1 8.3 48.5 (Obs-Esp)2/Esp 3.1 4.9 0.0 3.9 2.6 5.1 (a) (2 puntos) Hipótesis nula: el tamaño del cerebro y la complejidad del hábitat son independientes Hipótesis alternativa: el tamaño del cerebro y la complejidad del hábitat son dependientes
- 2. (b) Cálculos en la tabla (8 puntos) (c) Conclusión estadística (2 puntos): Dado que el valor de Chi-cuadrado observado de 48,5 es mayor que correspondiente valor crítico con 4 grados de libertad (=9,488), existe evidencia para rechazar H0, lo que indica que ambas variables no son independientes. (d) Conclusión biológica (2 puntos): La hipótesis inicial es apoyada por el hecho de que el tamaño del cerebro alcanzado en distintas especies efectivamente no ha sido independiente de la complejidad del hábitat 2
- 3. Pregunta 2 (12 puntos). En la pregunta anterior se indicó que las especies utilizadas en el análisis entre tamaño del cerebro y complejidad del hábitat se clasificaron entre aquellas con cerebro pequeño, normal y grande. Esta clasificación se basó en una asociación entre tamaño del cerebro y tamaño del cuerpo. La figura 1 muestra la distribución de puntos de dicha relación. Ya que se considera que el tamaño del cerebro es una consecuencia del tamaño del cuerpo, complete la figura 1 de modo que esta represente adecuadamente el tipo de análisis que se realizó. En particular, agregue información gráfica (nombre a los ejes, dibuje una curva de ser necesario) y agregue (o cambie) alguna información estadística que sea más relevante al análisis realizado. (a) (4 puntos) Figura 1 50 40 Tamaño cerebro 30 20 P=0,0001 r=0,81 10 2 r =0,65 0 0 5000 10000 15000 20000 25000 Tamaño cuerpo (b) Indique el nombre de la prueba estadística que se habría utilizado para obtener el valor de P mostrado en la gráfica, e indique las hipótesis nula y alternativa asociadas (3 puntos). Análisis de varianza (un factor) H0: la pendiente de la regresión lineal es 0 H1: la pendiente de la regresión lineal es distinta de 0 (c) Luego de haber completado la Fig. 1, cómo utilizaría esta información para definir especies con cerebro pequeño, normal y grande si usted hubiese participado en el estudio de la pregunta 1 (2 puntos). Especies con tamaños de cerebro cercanos o en la línea de regresión corresponderían a especies con cerebros normales. Especies con cerebros sobre la línea tendrían cerebros grandes y especies con cerebros ubicados bajo la línea tendrían cerebros chicos. 3
- 4. (d) Suponga que a un compañero de curso se le ocurrió que la relación entre ambas variables de la Fig. 1 no es lineal. Debido a ello, esta persona verificó una posible relación no lineal entre ambas variables y obtuvo un coeficiente de determinación de 0,87 con un valor de P también de 0,0001. Qué elemento(s) tomaría en cuenta para decidir cuál de las dos relaciones (lineal o no lineal) representa mejor la “verdadera” relación entre el tamaño del cuerpo y tamaño del cerebro. ¿A qué conclusión llegaría? (3 puntos) Dado que ambas regresiones son estadísticamente significativas, le decisión dependerá de qué % de la varianza del tamaño del cerebro es explicada por el tamaño del cuerpo en ambas regresiones (o sea el valor de r2). Dado que el % explicado en la relación no lineal de 0,87 es mayor que el % explicado en la relación lineal (=0,65), el modelo no lineal parece mejor. 4
- 5. Pregunta 3 (14 puntos). Un estudio tuvo como objetivo determinar si el período de apareamiento en el chimpancé pigmeo (Pan paniscus) determina una respuesta fisiológica de estrés. Para ello, se procedió registrar si el nivel de estrés, medido a partir del nivel de cortisol, de un mismo conjunto de estos simios estaba elevado o no en relación a antes y después del período de apareamiento. La Tabla 2 indica si el valor de estrés medido antes, durante y después del apareamiento fue mayor (“1”) o no (“0”) comparado con niveles basales medidos a animales no reproductivos en condiciones estándar. Tabla 2 Período Sujeto Antes Durante Después Totales, Fj Totales, Fj2 1 0 1 0 1 1 2 1 1 1 3 9 3 0 0 0 0 0 4 1 1 0 2 4 5 0 1 1 2 4 6 0 1 0 1 1 7 0 1 1 2 4 8 0 0 1 1 1 9 0 1 0 1 1 10 0 1 0 1 1 11 0 1 0 1 1 12 1 0 0 1 1 13 1 1 0 2 4 14 0 1 1 2 4 Totales, Ci 4 11 5 Totales, Ci2 16 121 25 (a) En base a los datos de esta tabla indique el nombre de la prueba más adecuada para examinar la hipótesis biológica anterior. Justifique brevemente la elección de la prueba. (2 puntos) La prueba adecuada es la prueba de Cochran por tratarse de una variable categórica y porque los mismos individuos fueron estudiados en tres períodos de tiempo (diseño de medidas repetidas) (b) Plantee las hipótesis nula y alternativa (2 puntos) Hipótesis nula: el nivel fisiológico de estrés no cambia con el período reproductivo Hipótesis alternativa: el nivel fisiológico de estrés cambia con el período reproductivo 5
- 6. (c) En base a los datos de la tabla 2, calcule la estadística de la prueba que seleccionó (6 puntos). 4 11 5 2 20 2 (3 1) (16 121 25) (2) (162) 3 3 57,3 Q 7,2 36 36 8 20 20 3 3 (c) Conclusión estadística (2 puntos): Dado que el valor de Chi-cuadrado observado de 7,2 es mayor que correspondiente valor crítico con 2 grados de libertad (=5,99), existe evidencia para rechazar H0. (d) Conclusión biológica (2 puntos): Los resultados apoyan la hipótesis de que el nivel de estrés fisiológico cambia durante el período apareamiento. 6
- 7. Pregunta 4 (14 puntos). Un estudio tuvo como objetivo evaluar si la cantidad de grasa en el cuerpo afecta la masa total cuerpo, tal como se ha documentado en humanos. Sin embargo, y también como se ha reportado en humanos, el sexo de los individuos podría ser una variable importante también. Por lo tanto, luego de someter a un grupo de animales a una dieta rica en calorías durante 30 días, se examinó el peso final de hembras y machos. Los resultados se sometieron a un análisis de covarianza y la Tabla 3 muestra una parte de estos. (a) Complete la tabla con los grados de libertad faltantes, calcule los cuadrados medios, los valores de F, extraiga el valor de F crítico e indique la decisión estadística apropiada (6 puntos). Tabla 3 Fuente Suma Grados Cuadrado Valor de F Valor crítico de F Decisión variación cuadrados libertad medio Sexo 980.5 1 980.5 31.8 4.54 Rechazo H0 Grasa 1382.4 1 1382.4 44.8 4.54 Rechazo H0 AxB 1357.3 1 1357.3 44.0 4.54 Rechazo H0 Error 463.1 15 30.9 Las Figuras 2 y 3 muestran gráficamente las relaciones entre las variables examinadas, de acuerdo a los resultados estadísticos del ANCOVA. (b) Complete las gráficas, agregando el nombre de las variables a los ejes (ambas figuras) y la leyenda a los puntos (solo Fig. 3) (4 puntos) 100 110 Fig. 2 Machos Fig. 3 100 Hembras 80 Peso corporal Peso corporal 90 60 80 40 70 20 60 0 50 22 24 26 28 30 32 34 Machos Hembras Grasa (c) En base a los resultados del ANCOVA (considere además que las pendientes en ambas curvas de la Fig. 3 no difieren) y a la representación gráfica de los resultados, plantee las correspondientes conclusiones biológicas (4 puntos). 7
- 8. Los resultados indican que la cantidad de grasa del cuerpo y el sexo de los individuos interactúan (tienen un efecto no aditivo) sobre el peso total. Esta interacción tiene que ver con que el efecto de la grasa sobre el peso es distinto en machos y hembras, muy probablemente debido a diferencia en los interceptos de la relación entre grasa y peso. 8
- 9. ANEXOS 9
- 10. 10
- 11. ( f i f i) ˆ 2 2 ( f i f i - 0,5) ˆ c 1 2 n 2 n ˆ i1 ˆ fi i fi fi - 0,5 n Gc 2 fi - 0,5 Ln ˆ fi - f i f i ˆ ˆ i1 fi ( f ij f ij) ˆ Cj 2 m n ˆij Fi 2 f j1 i1 ˆ f ij N n ( f ij f ij - 0,5) ˆ 2 f ij G 2 f ij Ln m n 1 1 2 m j1 i1 f ˆ j i ˆ f ij ij fij - 0,5 2 ( b c - 1) Gc 2 fij - 0,5 Ln m n 2 j1 i1 f ˆij bc a 2 Ci a 2 i1 (a 1) Ci i1 a Q b b F2 j j1 Fj j1 a 11