Descargado 20 veces






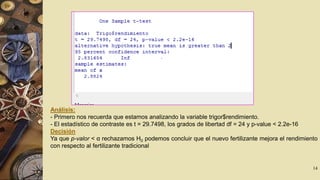

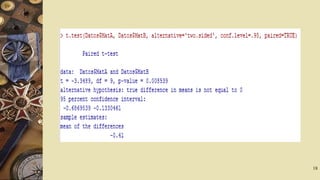

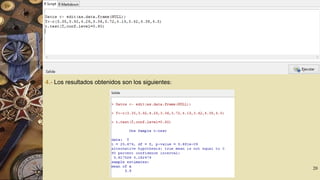
![El intervalo de confianza pedido es [3.6175; 4.1825]. Note que la salida entrega
además la media con valor 3,9 y por defecto, el test de hipótesis H0 : µ=0 en
contra de la hipótesis alternativa H1 : µ≠0 . Se rechaza la hipótesis nula ya que
el valor de la prueba es p-value = 5.681e-09.
21](https://image.slidesharecdn.com/r-commander-140115150622-phpapp02/85/R-commander-21-320.jpg)

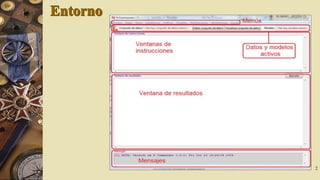
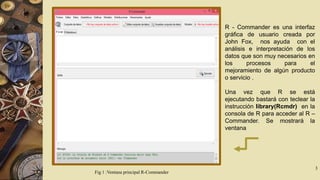
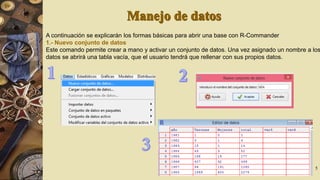
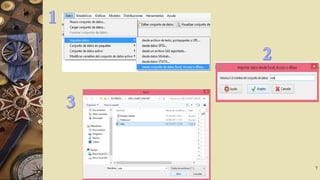
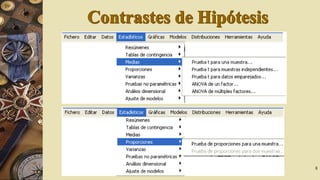
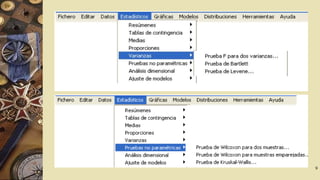
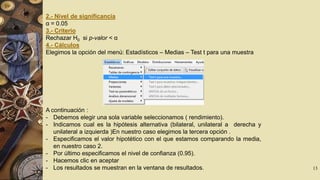
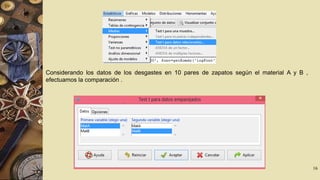
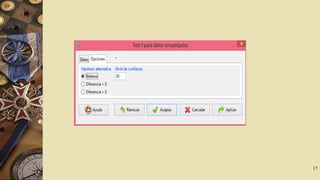
El documento describe el software R Commander, una interfaz gráfica de usuario creada por John Fox para facilitar el análisis e interpretación de datos en R. R Commander proporciona menús y herramientas para la gestión y análisis de datos, incluyendo opciones para abrir y guardar archivos, importar datos de otros programas, realizar estadísticas, gráficos y modelos, y ejecutar pruebas de hipótesis. El documento incluye ejemplos del uso de R Commander para cargar datos, calcular estadísticas descriptivas



























