Descargar como PDF, PPTX







































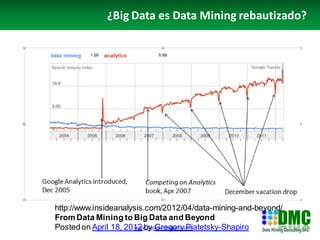



























El documento resume las tendencias recientes en minería de datos. Describe las diferentes "revoluciones" que ha habido en el campo como reglas de asociación, árboles de decisión, redes neuronales, análisis de supervivencia, analytics, uplifting, análisis de redes sociales, servicios de minería de datos y big data. También analiza las fuerzas detrás de estas revoluciones y las características generales de las mismas. Se enfoca luego en el análisis de redes sociales describiendo su importancia, desarrollos




































































































