Descargar para leer sin conexión























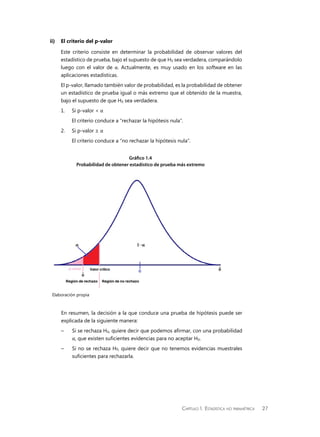







Este manual presenta técnicas estadísticas no paramétricas aplicadas a los negocios. Explica conceptos básicos como pruebas de hipótesis y tipos de variables. Luego, detalla pruebas no paramétricas para un caso de muestra, dos muestras relacionadas e independientes, y k muestras. Finalmente, presenta medidas no paramétricas de correlación. El objetivo es proveer herramientas estadísticas alternativas cuando los datos no cumplen supuestos paramétricos.







































