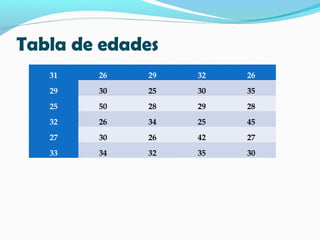
Este documento presenta los resultados de un estudio sobre las edades de 30 alumnos de una universidad. Incluye tablas con las frecuencias de edades y cálculos de medidas estadísticas centrales como la media, moda y mediana. También calcula medidas de dispersión como la desviación estándar, varianza y coeficiente de varianza. Finalmente, representa los datos en un diagrama de barras para visualizar la distribución de frecuencias por rango de edades.