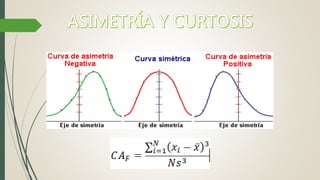
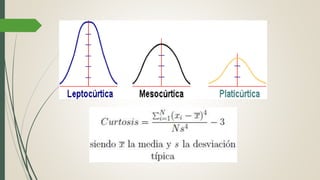
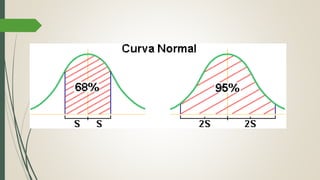
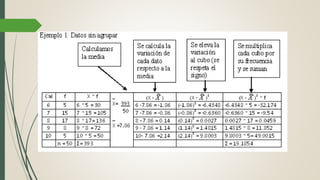
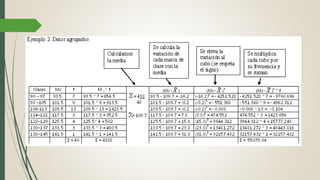
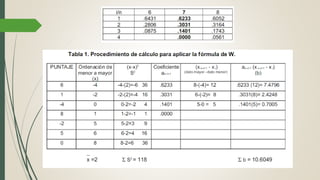
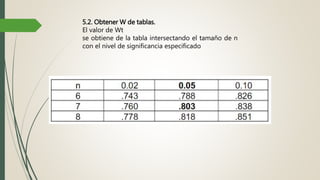
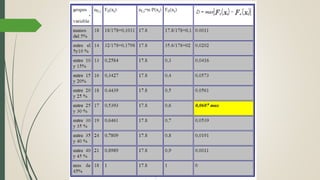
Este documento describe cómo realizar una prueba de Shapiro-Wilk para determinar si los datos de una muestra siguen una distribución normal. Explica los pasos para establecer las hipótesis, seleccionar la prueba estadística apropiada, especificar el nivel de significación, obtener el estadístico de prueba y tomar una decisión estadística sobre si rechazar o no la hipótesis nula de normalidad. Finalmente, aplica este procedimiento a un ejemplo de datos reales y concluye que la distribución de