Descargar como PDF, PPTX

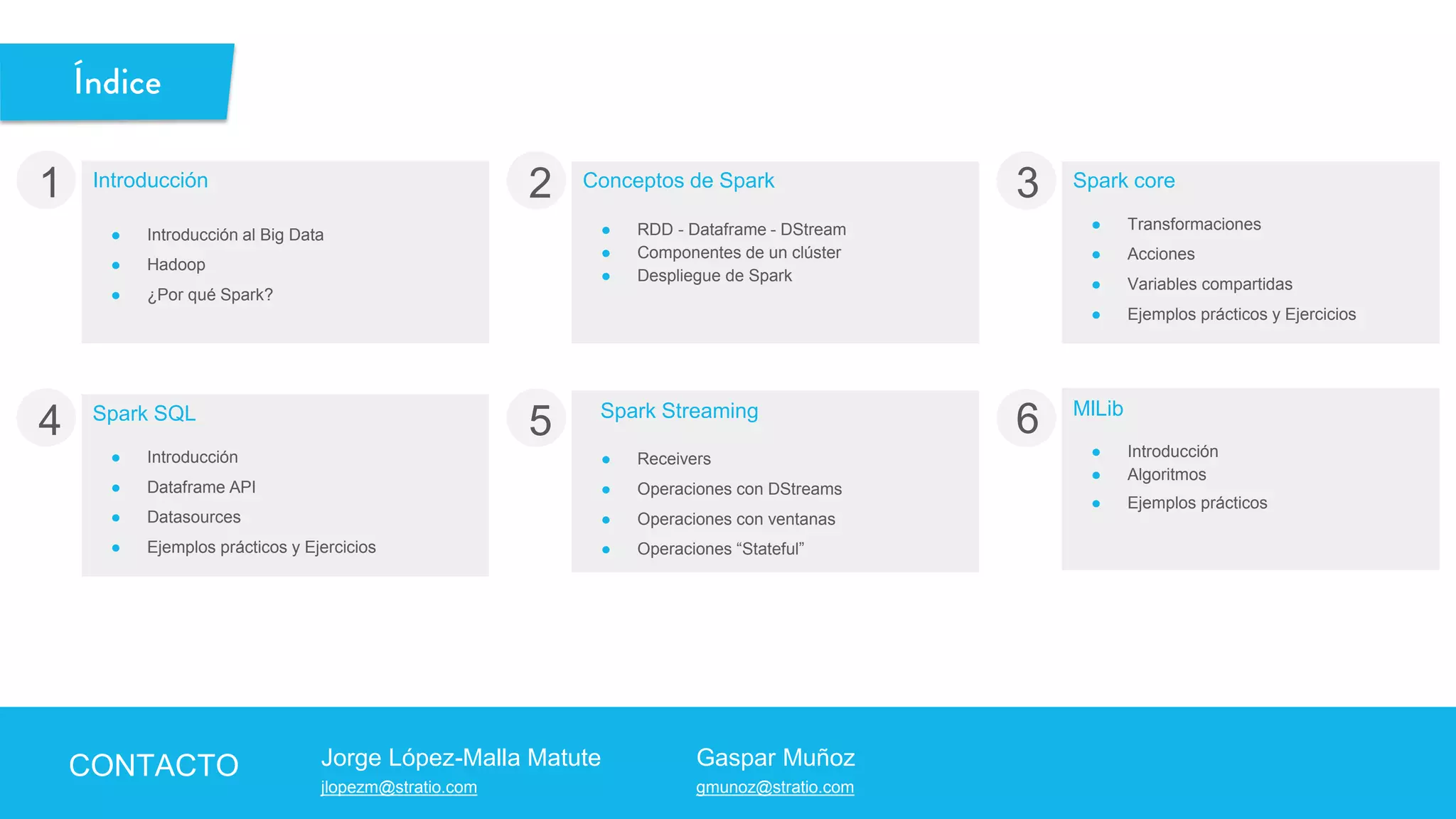








![Definición:
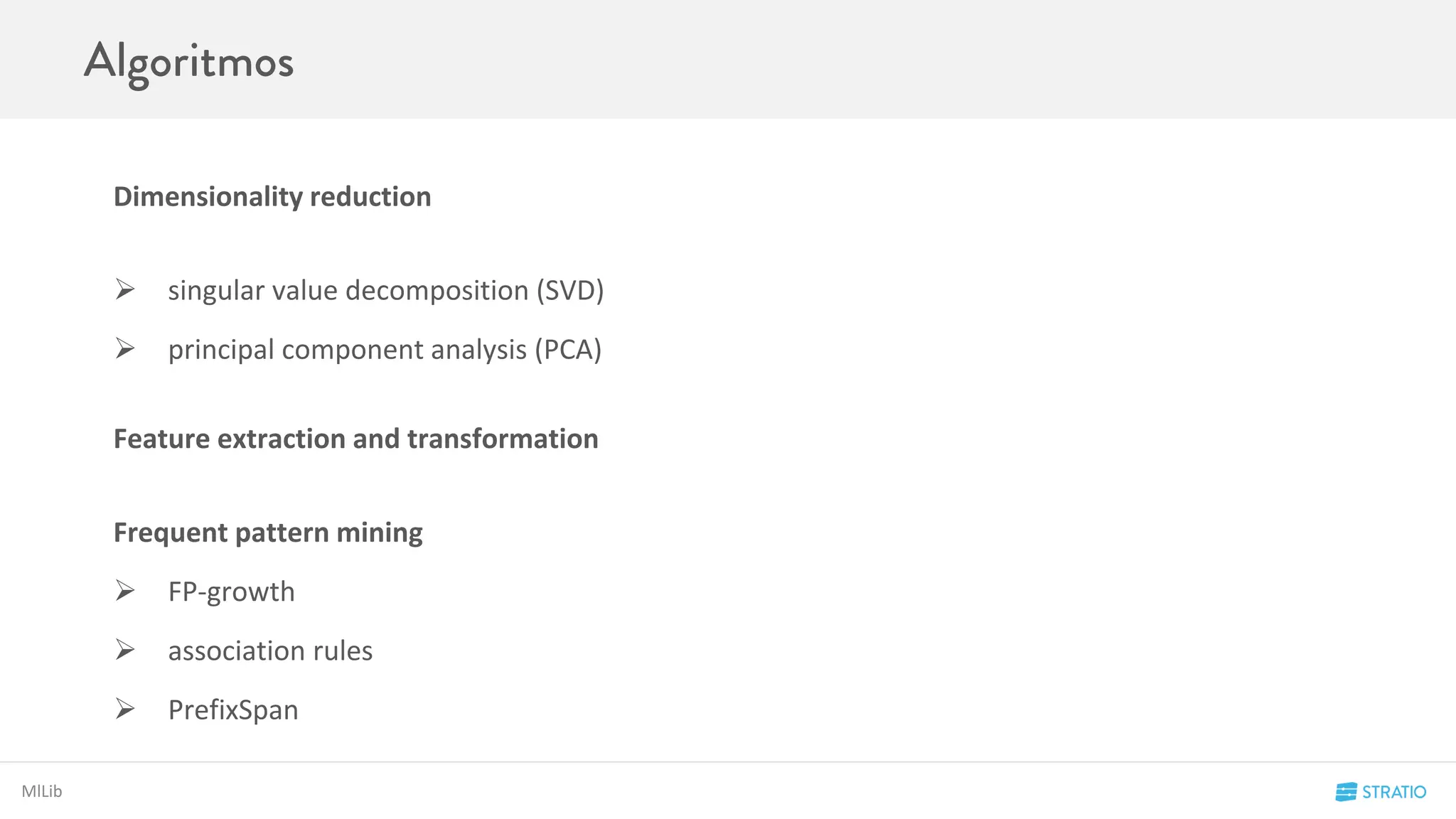
Un RDD en Spark es una colección de colecciones de objetos inmutable y distribuida. Cada RDD está dividido en diferentes particiones, que
pueden ser computadas en los distintos nodos del Cluster de Spark.
Es la Unidad mínima de computación en Spark
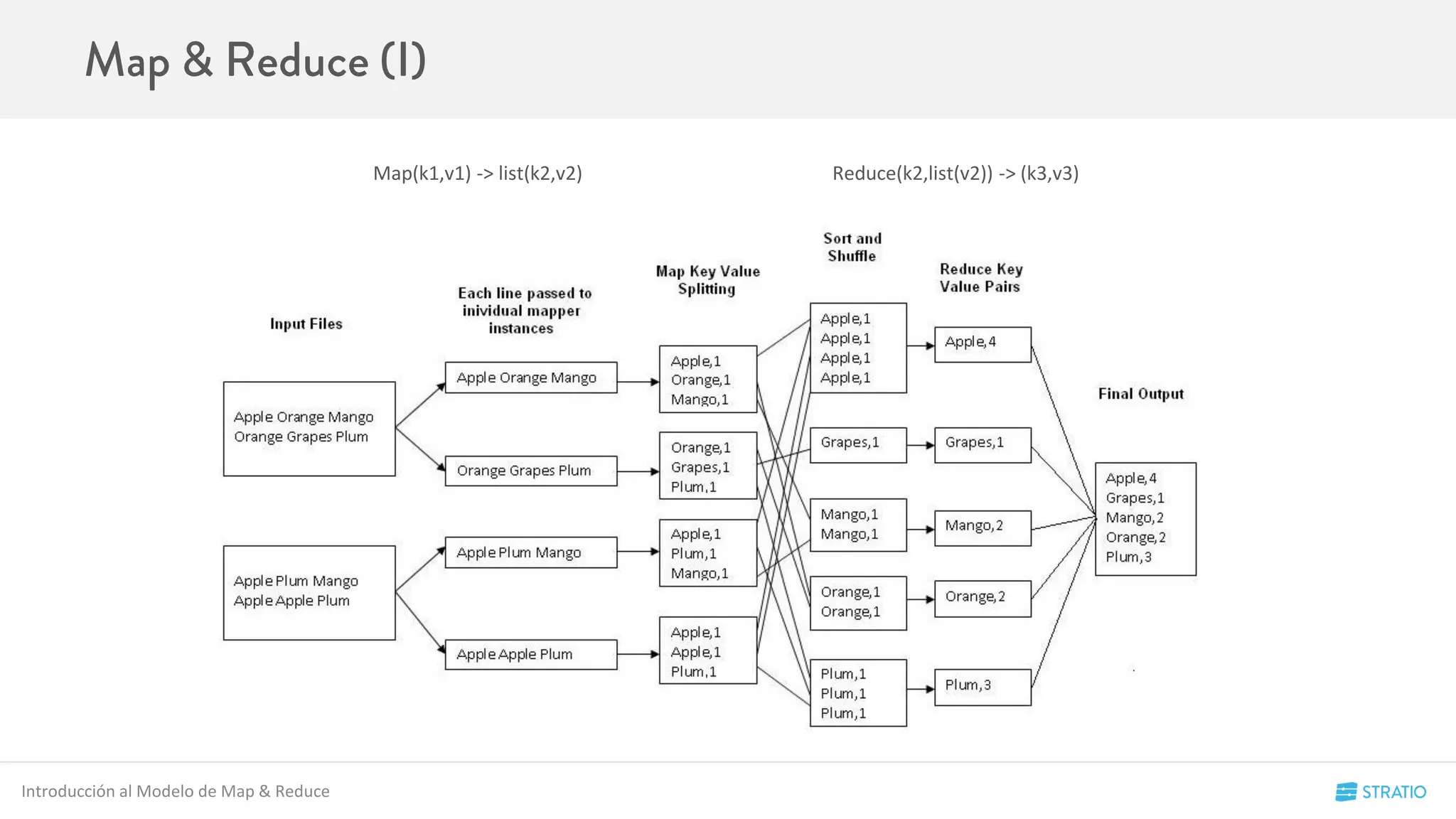
Ej:
El RDD numbers es un rdd de enteros que está distribuido por en un cluster con 3 Workers{W1, W2, W3}
numbers = RDD[1,2,3,4,5,6,7,8,9,10]
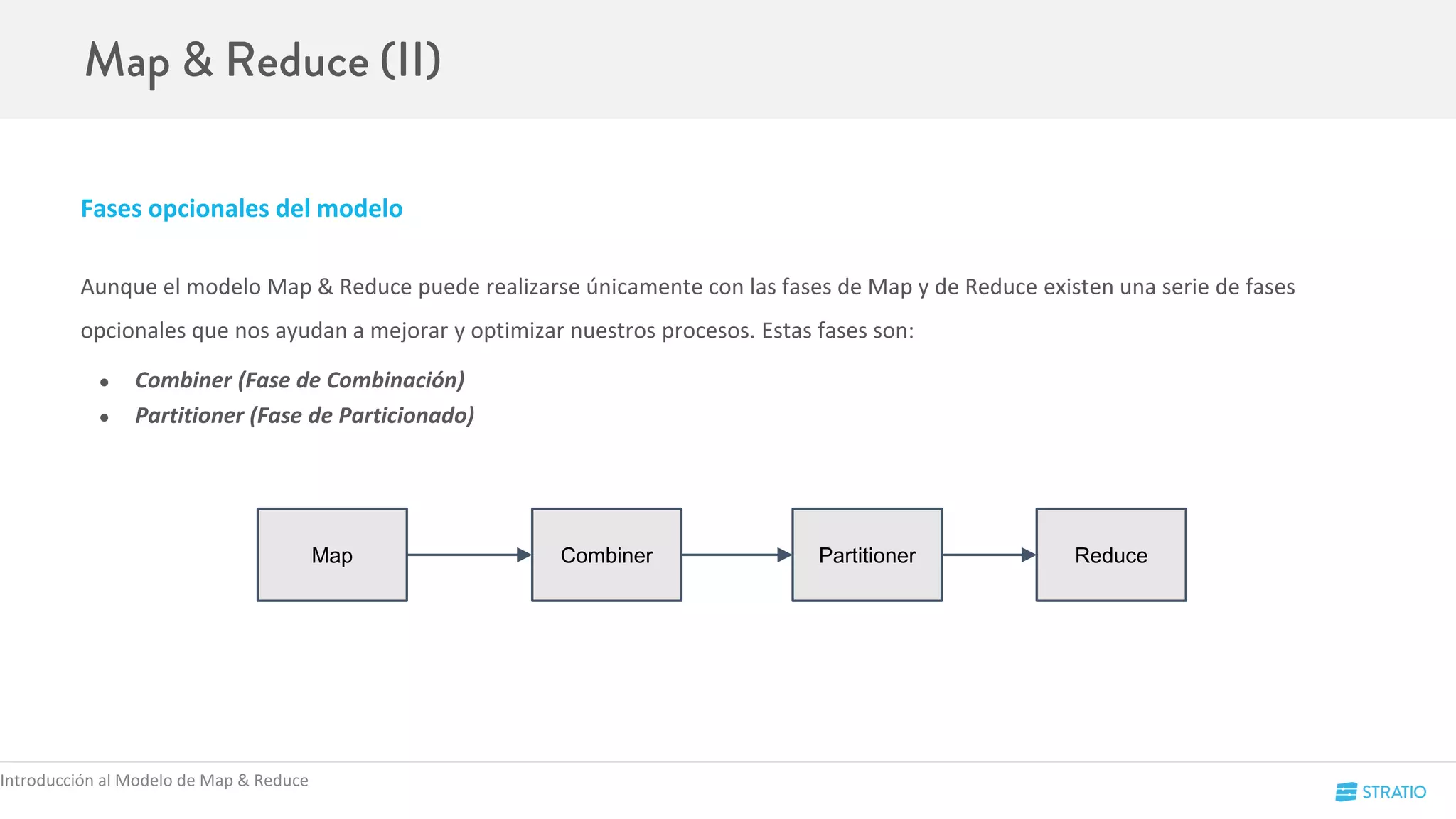
Conceptos de Spark
W1 W2 W2
[1,5,6,9] [2,7,8] [3,4,10]](https://image.slidesharecdn.com/codemotion-madrid15-151127153322-lva1-app6892/75/Spark-Hands-on-17-2048.jpg)

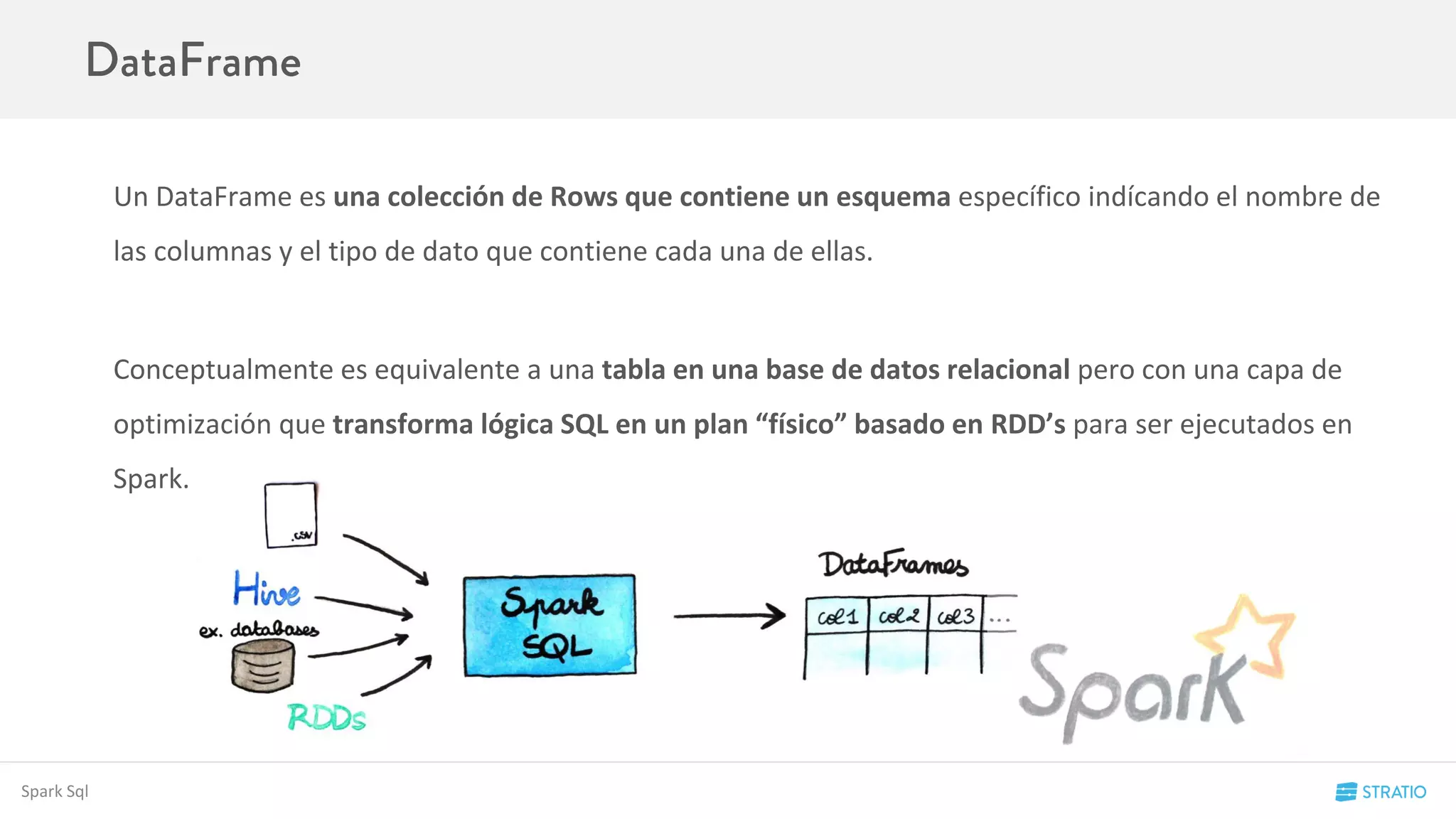
![Definición:
Un DataFrame en Spark es una colección de colecciones de objetos inmutable y distribuida organizada en columnas con nombre.
Conceptualmente es igual que una tabla en una base de datos relacional. Estos datos pueden provenir de muchas fuentes de datos
estructurados como Json, CSV, tablas de Hive u otros RDD existentes
Es la Unidad mínima de computación en Spark SQL
Ej:
El RDD persons es un Dataframe que representa la tabla persona que tiene un campo nombre, texto, y otro campo edad, un entero.
Conceptos de Spark
W1 W2 W3
[Jorge, 31] [Gaspar, 28] [María 23]
persons= Dataframe[(Jorge, 31);
(Gaspar, 28);
(María, 23)]
Nombre -> String; Edad -> Int](https://image.slidesharecdn.com/codemotion-madrid15-151127153322-lva1-app6892/75/Spark-Hands-on-19-2048.jpg)
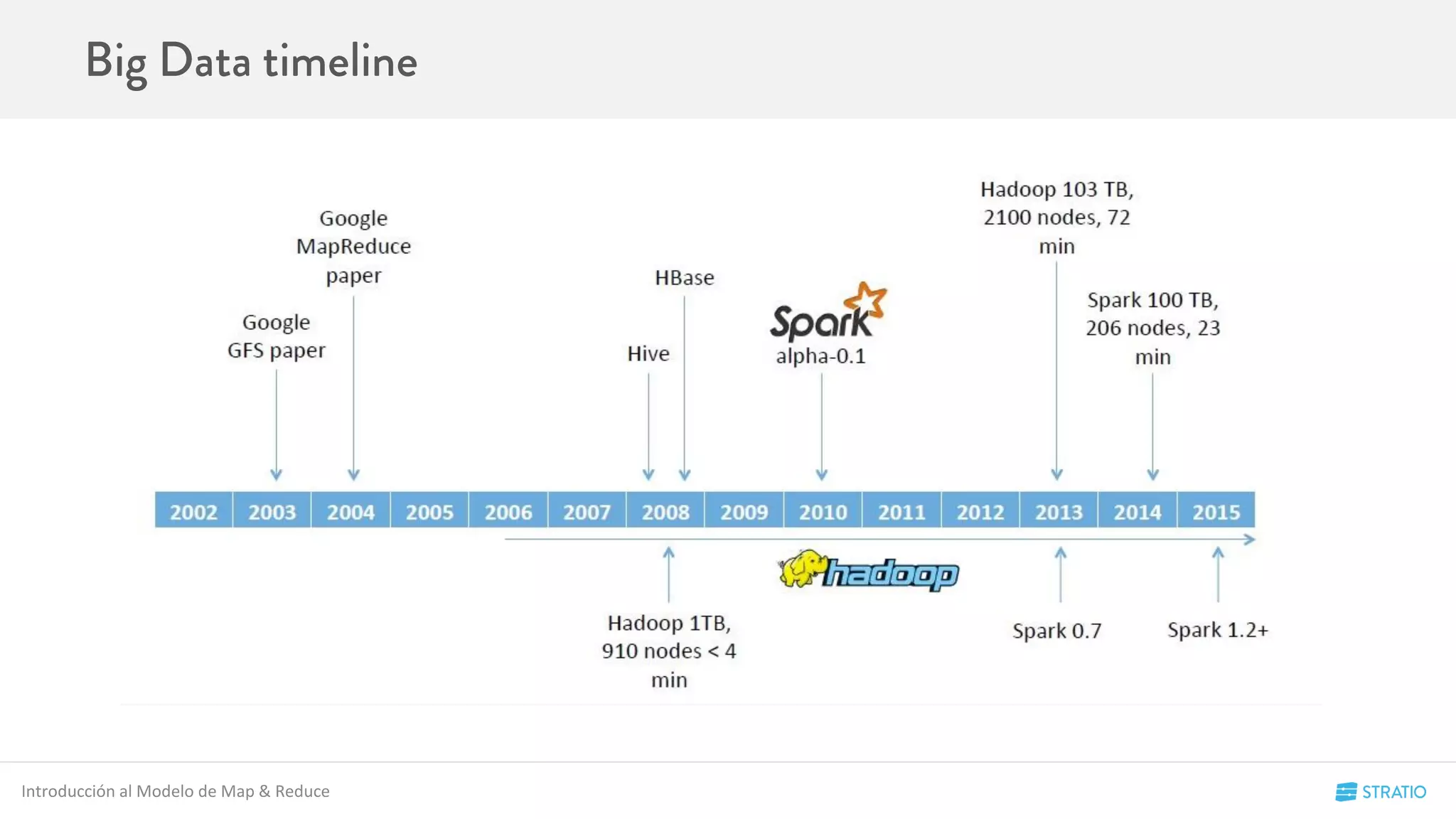
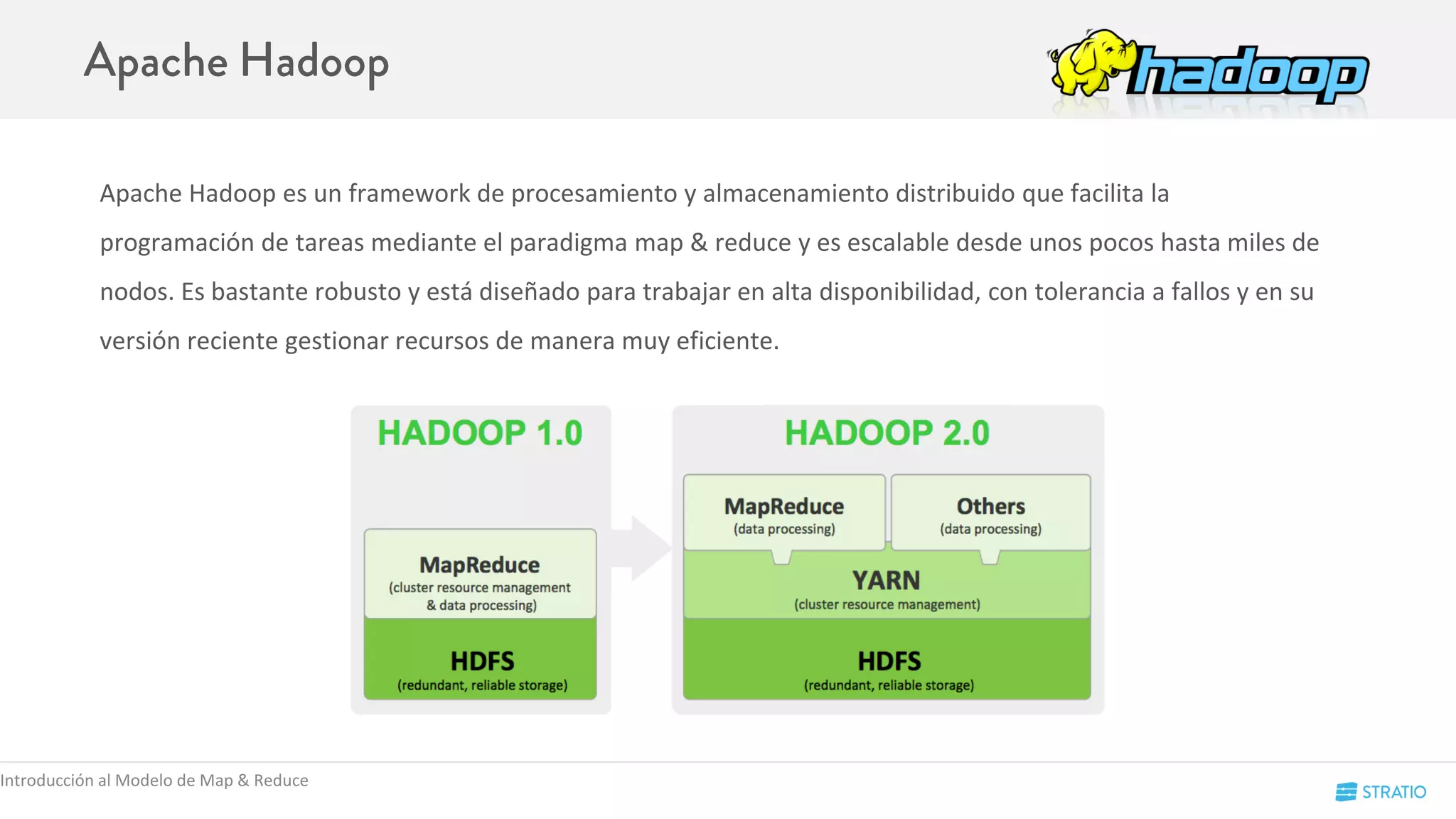
![Spark se puede desplegar de distintas maneras:
● Local: Levanta un cluster embebido de Spark.
○ Se hace creando un SparkContext con master = local[NumeroCores]
○ El SparkMaster se levanta en el propio proceso y no es accesible ni por via web
○ Los Workers, tantos como NúmeroCores, se levantan también en el propio proceso (página de stages accesible vía Web)
● Standalone:
○ El SparkMaster se lanza en una máquina del cluster. Web en el Master
○ Tendrá tantos Workers como máquinas se indiquen en el fichero slaves
○ Se despliega mediante el script start-all.sh de Spark.
Conceptos de Spark](https://image.slidesharecdn.com/codemotion-madrid15-151127153322-lva1-app6892/75/Spark-Hands-on-20-2048.jpg)




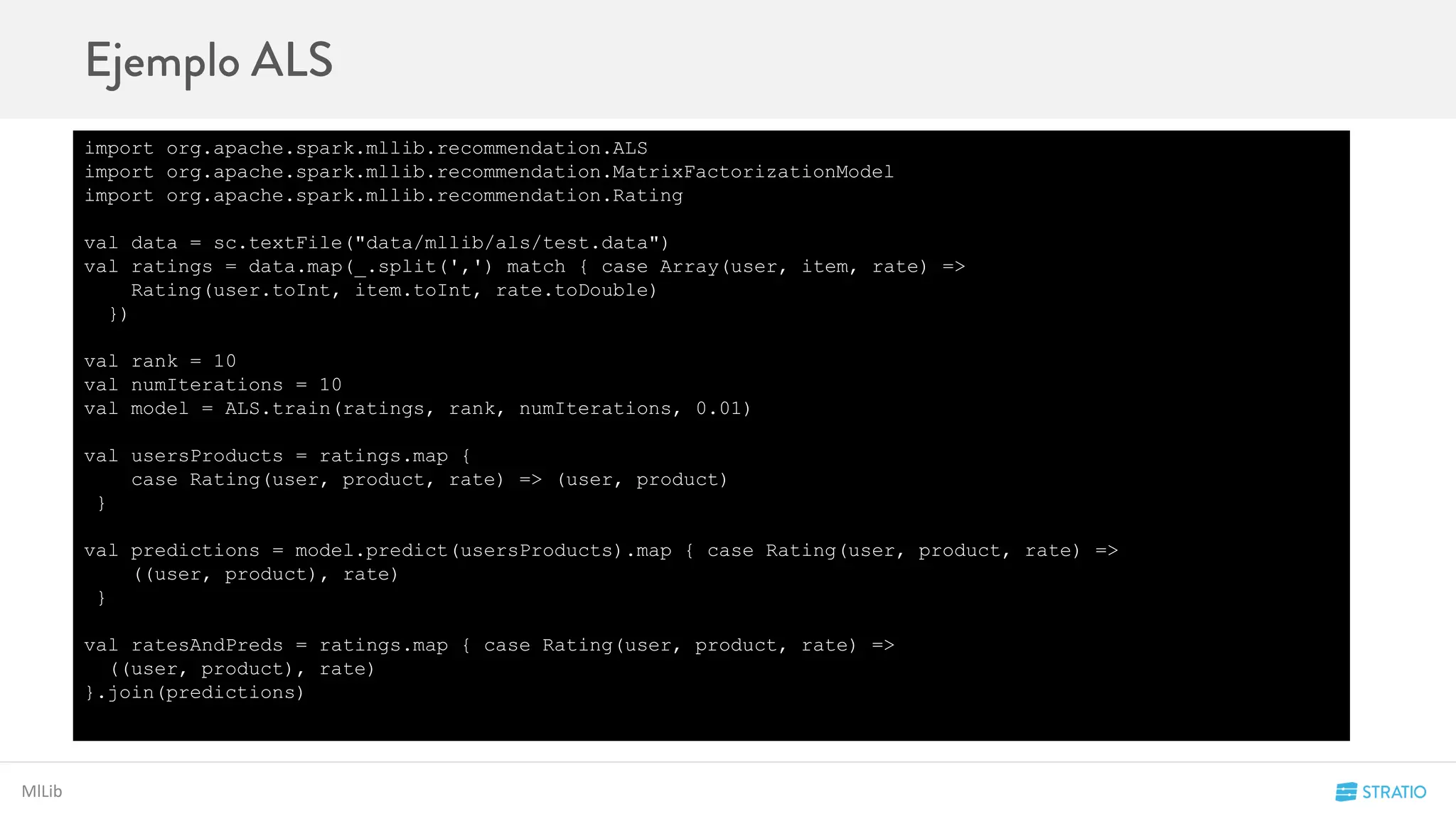
![Spark Core
map
Devuelve el rdd resultante de aplicar una función a cada uno de los elementos del rdd que lo invoca:
map(f: (V) ⇒ U) : RDD[U]
map
scala> val rddUpper = rddCow.map(_.toUpperCase)
rddUpper: org.apache.spark.rdd.RDD[String] = MappedRDD[1] at map
rddCow rddUpper
I've never seen a purple cow
I never hope to see one
But i can tell you, anyhow,
I’d rather see than be one
I'VE NEVER SEEN A PURPLE COW
I NEVER HOPE TO SEE ONE
BUT I CAN TELL YOU, ANYHOW,
I’D RATHER SEE THAN BE ONE](https://image.slidesharecdn.com/codemotion-madrid15-151127153322-lva1-app6892/75/Spark-Hands-on-25-2048.jpg)
![Spark Core
flatMap scala> val rddCowWords = rddCow.flatMap(_.split(" "))
rddCowWords: org.apache.spark.rdd.RDD[String] = FlatMappedRDD[2] at flatMap
scala> rddCow.partitions.size == rddCowWords.partitions.size
res1: Boolean = true
scala> rddCow.count == rddCowWords.count
25/04/15 10:30:28 INFO SparkContext: Starting job: count
25/04/15 10:30:28 INFO DAGScheduler: Got job 2 (count) with 3 output partitions
(allowLocal=false)
…
25/04/15 10:30:20 INFO DAGScheduler: Job 3 finished: count, took 0,11456 s
res2: Boolean = false
flatMap
rddCowWords
I've never seen a purple cow
I never hope to see one
But i can tell you, anyhow,
I’ve
never
seen
a
purple
cow
I
never
hope
to
see
one
But
i
can
tell
you,
anyhow
rddCow](https://image.slidesharecdn.com/codemotion-madrid15-151127153322-lva1-app6892/75/Spark-Hands-on-26-2048.jpg)
![Spark Core
filter scala> val rddEven = rddNumber.filter(number => number%2 == 0)
rddEven : org.apache.spark.rdd.RDD[Int] = FlatMappedRDD[3] at filter
scala> rddNumber.partitions.size == rddEven.partitions.size
res3: Boolean = true
scala> rddNumber.count == rddEven.count
25/11/15 11:30:28 INFO SparkContext: Starting job: count
25/11/15 11:30:28 INFO DAGScheduler: Got job 2 (count) with 3 output partitions (allowLocal=false)
…
25/11/15 11:30:20 INFO DAGScheduler: Job 3 finished: count, took 0,11456 s
res4: Boolean = false
filter
rddEven
1
2
3
rddNumber
2](https://image.slidesharecdn.com/codemotion-madrid15-151127153322-lva1-app6892/75/Spark-Hands-on-27-2048.jpg)
![join:
Spark Core
(Algebra, prof1)
(Calculus, prof2)
(Sw Engineering , prof2)
(Algebra, alumn1)
(Logic, alumn1)
(Algebra, alum3)
(Algebra, alum2)
(Calculus, alum1)
(Calculus, alum2)
(Algebra, alum4)
(Algebra, (prof1,alumn1)
(Algebra, (prof1, alum3)
(Algebra, (prof1, alum2))
(Algebra, (prof1, alum4))
(Calculus, (prof2, alum2))
(Calculus, (prof2, alum1))
rddCourseTeacher
rddCourseStudent
rddCourseTeacherStudent
scala> val rddCourseTeacherAllStudent = rddCourseTeacher.leftOuterJoin(rddCourseStudent)
rddCourseTeacherStudent: org.apache.spark.rdd.RDD[(String,(Int, Int))] =
FlatMappedValuesRDD[1] at join
join](https://image.slidesharecdn.com/codemotion-madrid15-151127153322-lva1-app6892/75/Spark-Hands-on-28-2048.jpg)
![groupByKey:
Agrupa los valores por una clave devolviendo una lista por cada clave
groupByKey() : RDD[(K,Iterable[V])]
Spark Core
(odd, 3)
(odd, 3)
(odd, 5)
(even, 12)
(even, 4)
(even, 4)
groupByKey
(odd, (3, 3, 5))
(even, (4, 4, 12)
rddIsEvenNumber
rddIsEvenNumbers
scala> val rddIsEvenNumbers = rddIsEvenNumber.groupByKey
rddIsEvenNumbers: org.apache.spark.rdd.RDD[(String, Iterable[Int])] = ShuffledRDD[1] at groupByKey](https://image.slidesharecdn.com/codemotion-madrid15-151127153322-lva1-app6892/75/Spark-Hands-on-29-2048.jpg)
![rddVisits
combineByKey:
Spark Core
Shuffle
(February, (5, 1))
(January, (21, 5))
(June, (2,2))
(March, (2,2))
rddMeanVisitsByMonth
scala> val rddMeanVistisByMonth = rddVisits.combineByKey(
(visit: Int) => (visit, 1),
(comb: (Int, Int), visit) => (comb._1 + visit, comb._2 + 1),
(combAcc: (Int, Int), comb: (Int, Int)) => (combAcc._1 + comb._1, combAcc._2 +
comb._2))
rddMeanVistisByMonth: org.apache.spark.rdd.RDD[(String, (Int, Int))] = ShuffledRDD[2]
2
1
3
(March, 4)
(March, 4)
(January, 4)
(January, 4)
(January, 3)
(January, 5)
(June, 2)
(March, 3)
(February, 5)
(June, 1)
(January, 5)
1
1
1
1
1
1
1
2
1
1
2
1
1
2
3
3
3
3](https://image.slidesharecdn.com/codemotion-madrid15-151127153322-lva1-app6892/75/Spark-Hands-on-30-2048.jpg)
![numVisits
count
Cuenta el número de registros de un RDD
countByKey: Map[K, Long]
Spark Core
(January, (3, 5, 7))
(March, (3))
(February, (5))
(June, (1, 2))
(March, (4, 4))
(January, (4, 4))
rddVisitsByMonth
count
scala> val numVisits = rddVisitsByMonth.count
numVisits: Int
6](https://image.slidesharecdn.com/codemotion-madrid15-151127153322-lva1-app6892/75/Spark-Hands-on-32-2048.jpg)
![visits
collect
Recolecta todos los datos de un RDD en forma de lista
countByKey: Map[K, Long]
Spark Core
(January, (3, 5, 7))
(March, (3))
(February, (5))
(June, (1, 2))
(March, (4, 4))
(January, (4, 4))
rddVisitsByMonth
collect
scala> val visits = rddVisitsByMonth.collect
numVisits: Array[(Int, List[Int]]
[(January, (3, 5, 7)),
(March, (3)),
(February, (5)),
(June, (1, 2))
(March, (4, 4))
(January, (4, 4))]](https://image.slidesharecdn.com/codemotion-madrid15-151127153322-lva1-app6892/75/Spark-Hands-on-33-2048.jpg)
![VisitsMap
countByKey
Devuelve los datos al Driver en forma de Map con un contador por clave
countByKey: Map[K, Long]
Spark Core
(January, (3, 5, 7))
(March, (3))
(February, (5))
(June, (1, 2))
(March, (4, 4))
(January, (4, 4))
rddVisitsByMonth
countByKey
scala> val visitsMap = rddVisitsByMonth.countByKey
visitsMap: scala.collection.Map[String,Long]
{(January, 2),
(March, 1),
(June, 1),
(February, 1)}](https://image.slidesharecdn.com/codemotion-madrid15-151127153322-lva1-app6892/75/Spark-Hands-on-34-2048.jpg)





















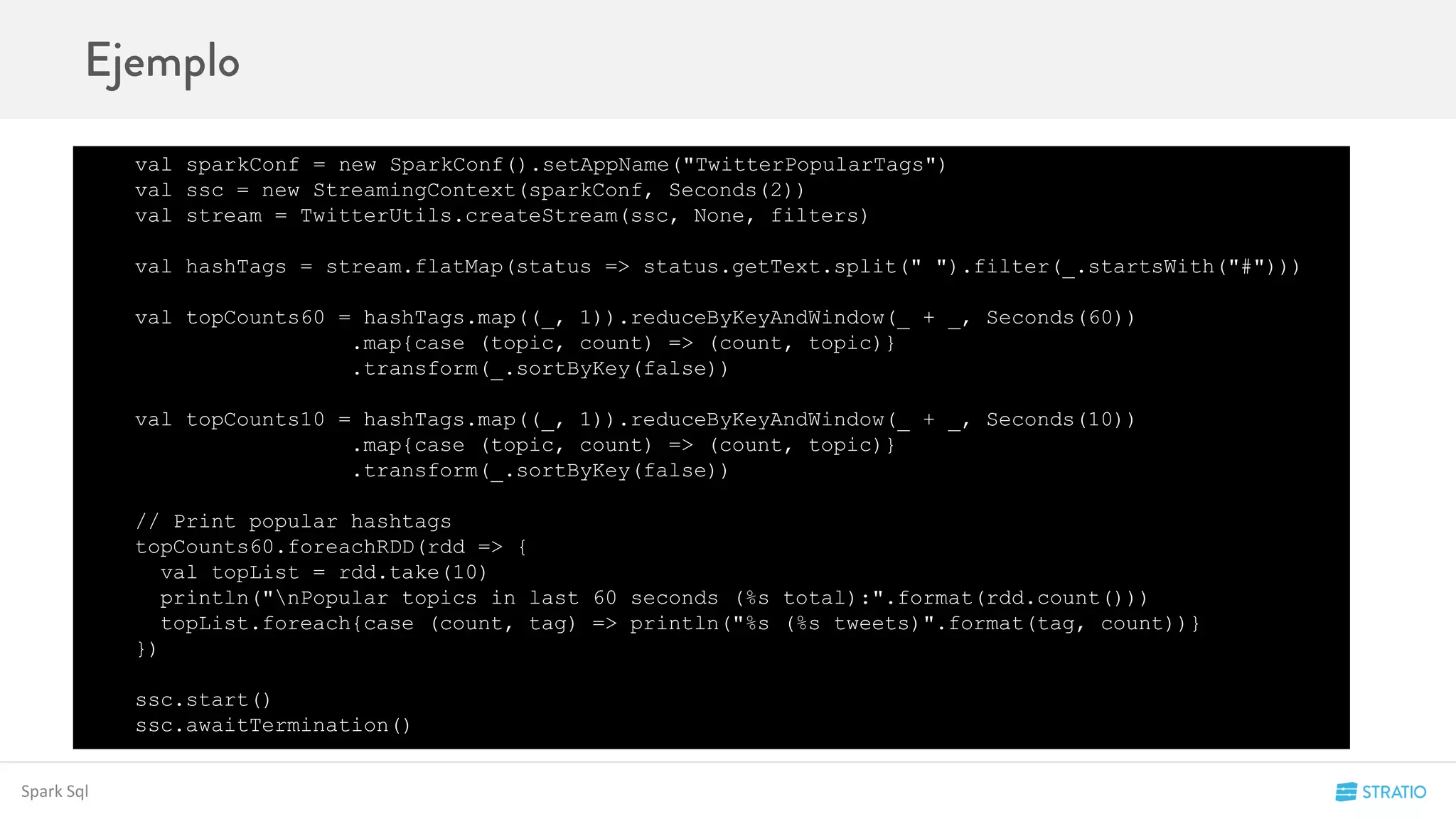
![• map(func),
• flatMap(func),
• filter(func),
• count()
• repartition(numPartitions)
• union(otherStream)
• reduce(func),
• countByValue(),
• reduceByKey(func, [numTasks])
• join(otherStream, [numTasks]),
• transform()
SPARK STREAMING OVERVIEW](https://image.slidesharecdn.com/codemotion-madrid15-151127153322-lva1-app6892/75/Spark-Hands-on-62-2048.jpg)
![• window(windowLength, slideInterval)
• countByWindow(windowLength, slideInterval)
• reduceByWindow(func, windowLength, slideInterval)
• reduceByKeyAndWindow(func, windowLength, slideInterval, [numTasks])
• countByValueAndWindow(windowLength, slideInterval, [numTasks])
SPARK STREAMING OVERVIEW](https://image.slidesharecdn.com/codemotion-madrid15-151127153322-lva1-app6892/75/Spark-Hands-on-63-2048.jpg)
![• print()
• foreachRDD(func)
• saveAsObjectFiles(prefix, [suffix])
• saveAsTextFiles(prefix, [suffix])
• saveAsHadoopFiles(prefix, [suffix])
SPARK STREAMING OVERVIEW](https://image.slidesharecdn.com/codemotion-madrid15-151127153322-lva1-app6892/75/Spark-Hands-on-64-2048.jpg)
 ⇒ RDD[U])
: DStream[U]
def foreachRDD(foreachFunc: (RDD[T], Time) ⇒ Unit): Unit
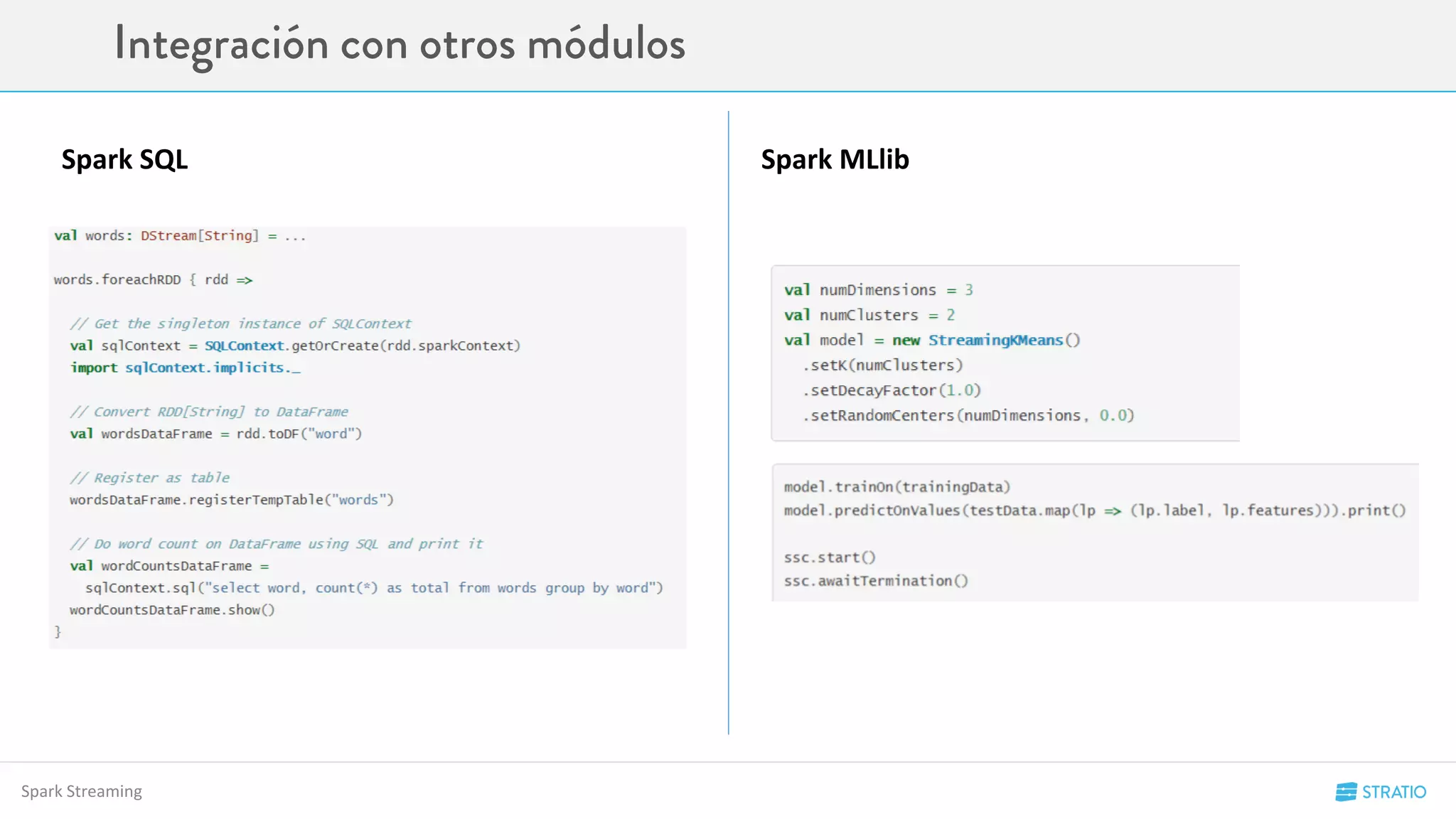
• Mezclar batch con streaming
• Usar DataFrames en Streaming
• Machine Learning en Streaming
• Reusar código existente de Batch
• Enviar datos a sistemas externos (ej. DB)
• Usar datasources de Spark SQL](https://image.slidesharecdn.com/codemotion-madrid15-151127153322-lva1-app6892/75/Spark-Hands-on-65-2048.jpg)


⇒ Option[S])
def reduceByKeyAndWindow(reduceFunc: (V, V) ⇒ V,
windowDuration: Duration)
• Para cada clave K mantiene un Option[S]
• Option a None elimina el estado.
• Es igual que un reduceByKey pero
adicionalmente toma una ventana de tiempo.](https://image.slidesharecdn.com/codemotion-madrid15-151127153322-lva1-app6892/75/Spark-Hands-on-67-2048.jpg)








Este documento presenta una introducción a Spark, incluyendo conceptos clave como RDD, DataFrame y DStream. Explica cómo Spark puede desplegarse localmente, en modo standalone o usando YARN/Mesos, y describe operaciones fundamentales como transformaciones (map, filter), acciones (count) y métodos de agregación (groupByKey, combineByKey).







































![Meetup Fun[ctional] spark with scala](https://cdn.slidesharecdn.com/ss_thumbnails/functionalsparkwithscala-180524102236-thumbnail.jpg?width=640&height=640&fit=bounds)



























