



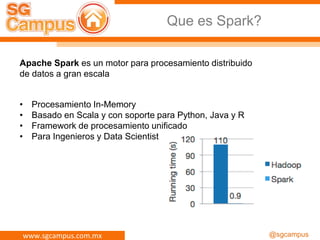

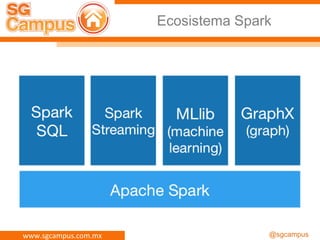




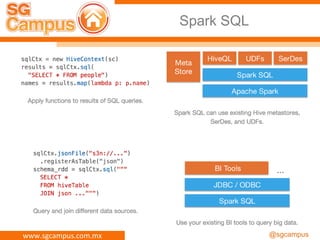
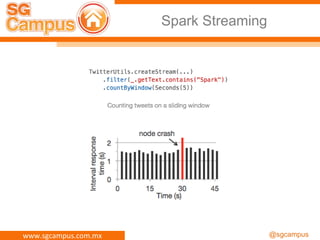

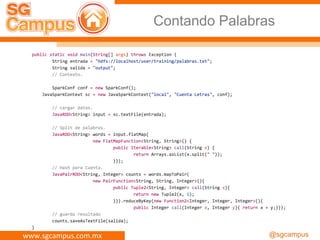


El documento presenta información sobre Apache Spark y Big Data, destacando su capacidad para el procesamiento distribuido de datos a gran escala y sus componentes principales como RDD y task scheduler. También se menciona la importancia de HDFS como sistema de archivos para almacenar grandes volúmenes de datos, junto con ejemplos y guías para su instalación y uso. Además, se aborda la naturaleza de 'Big Data' y sus características clave como la variedad.



































































