Descargado 15 veces





















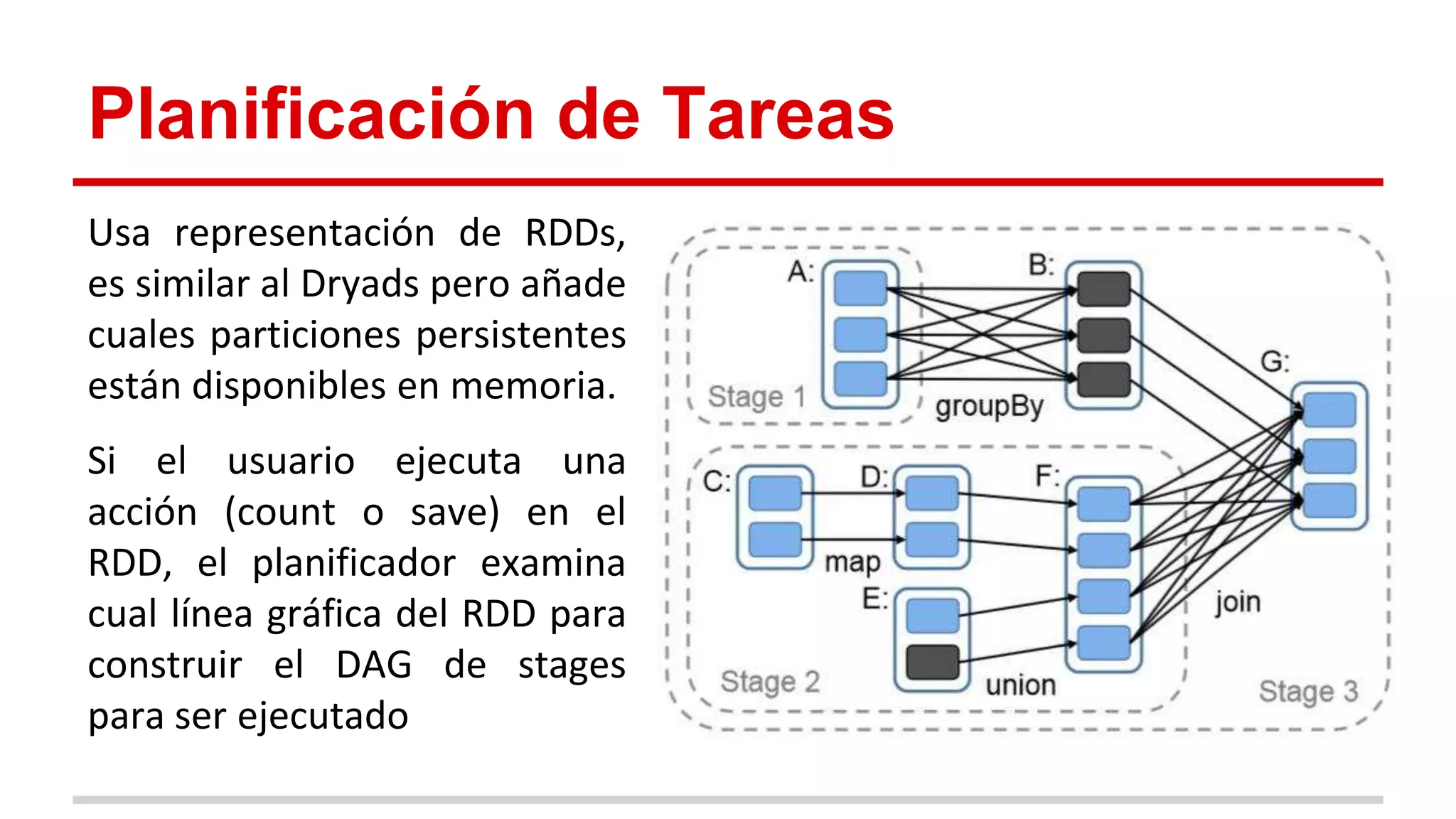


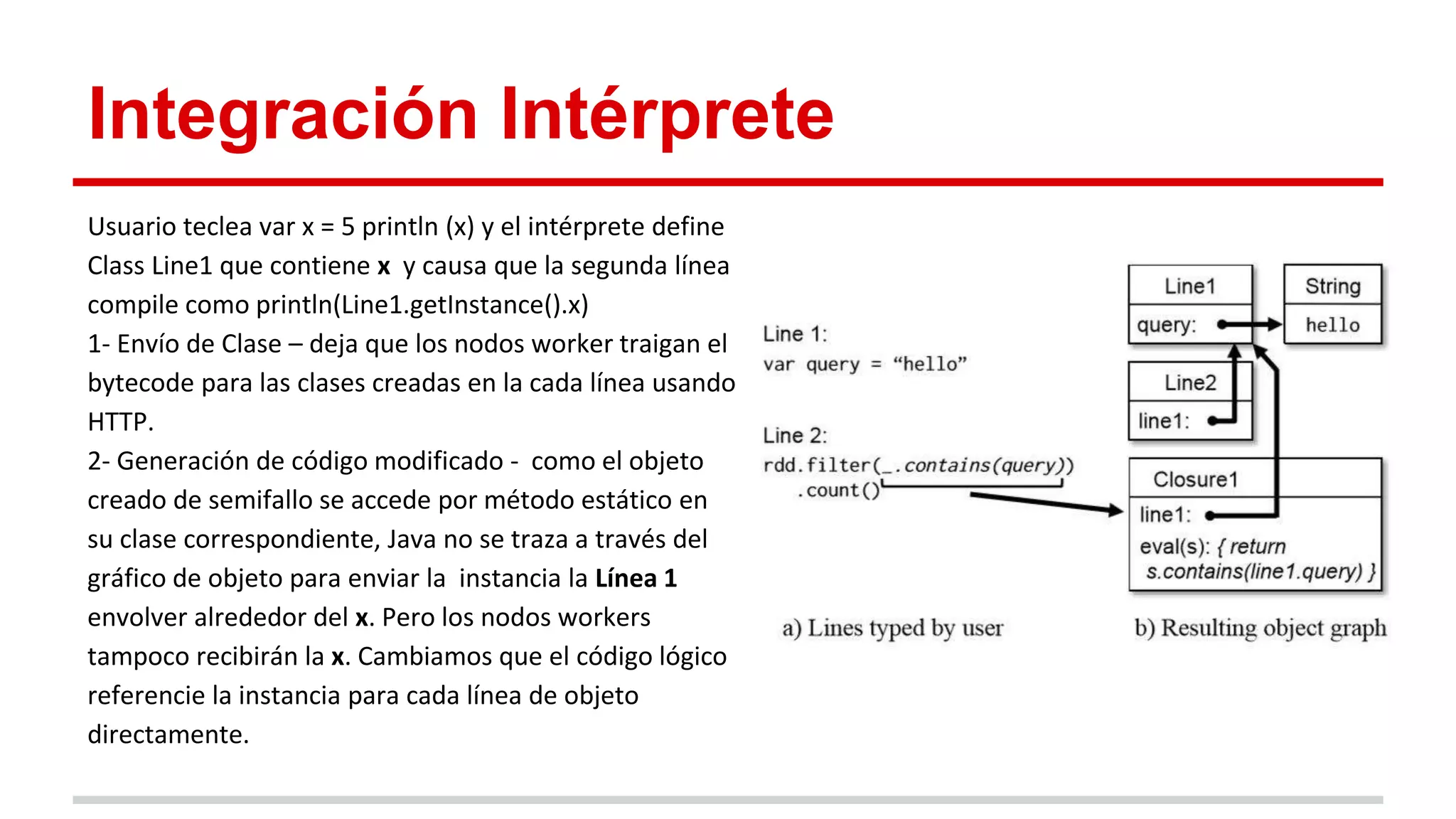






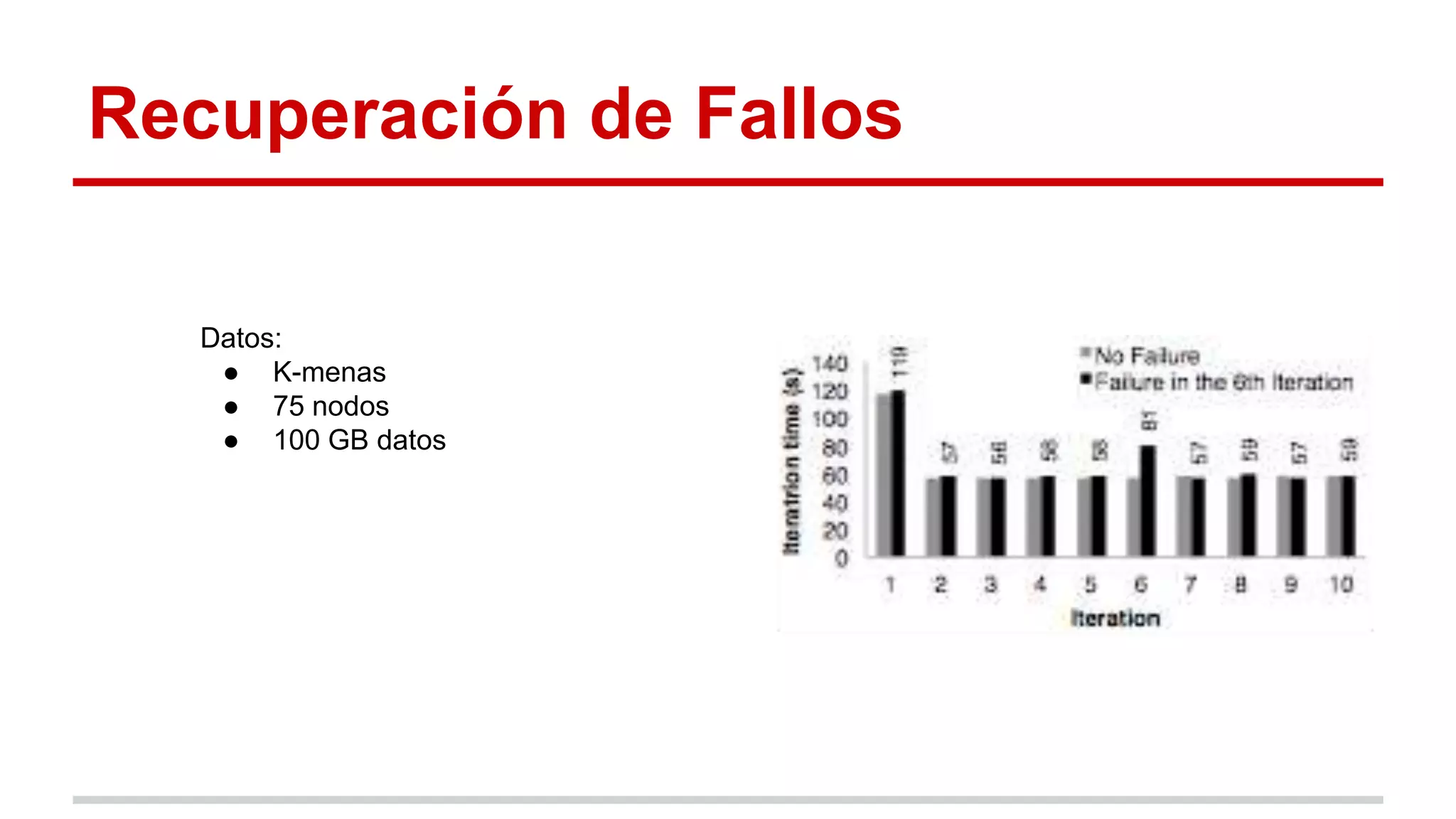
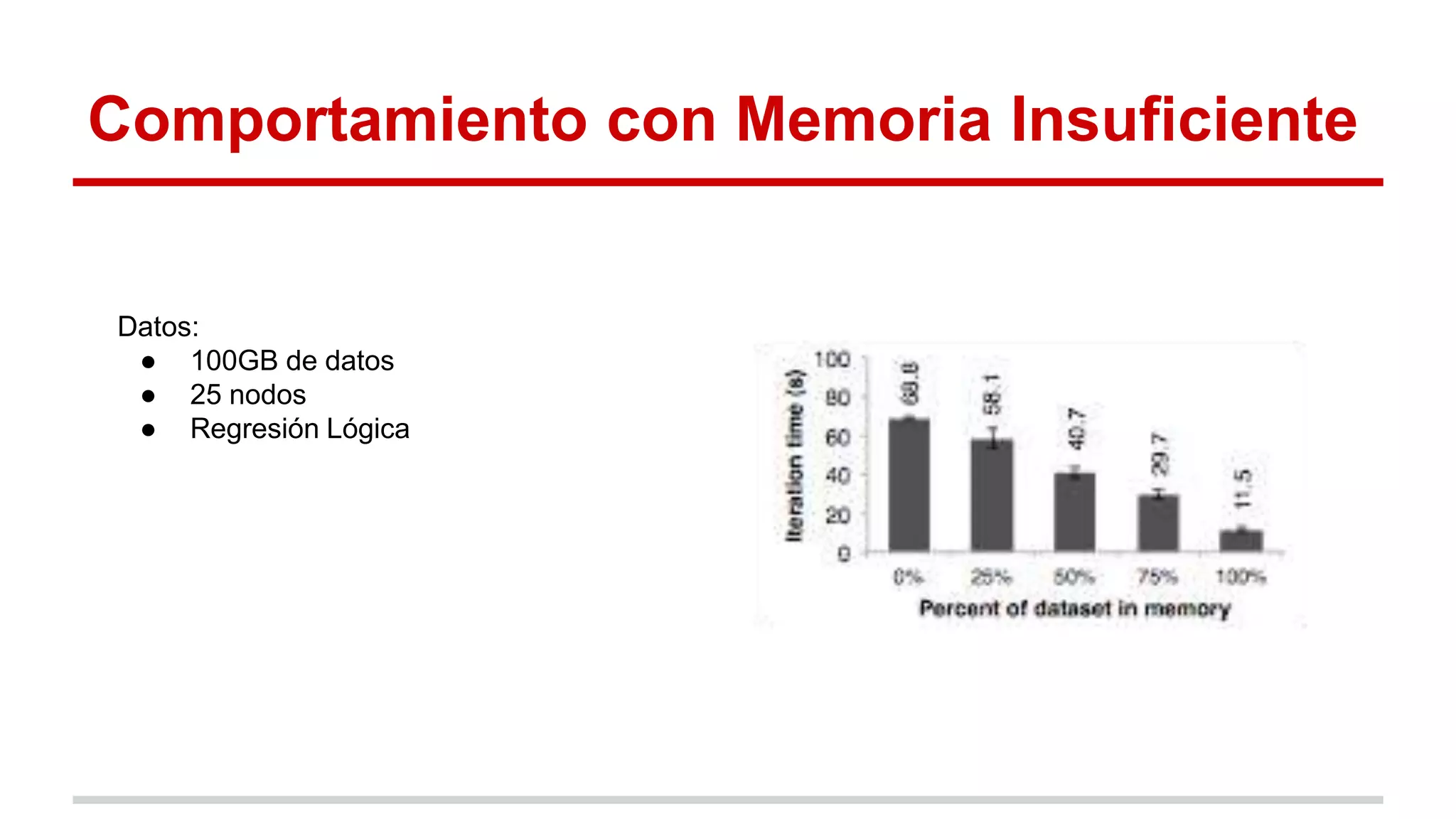
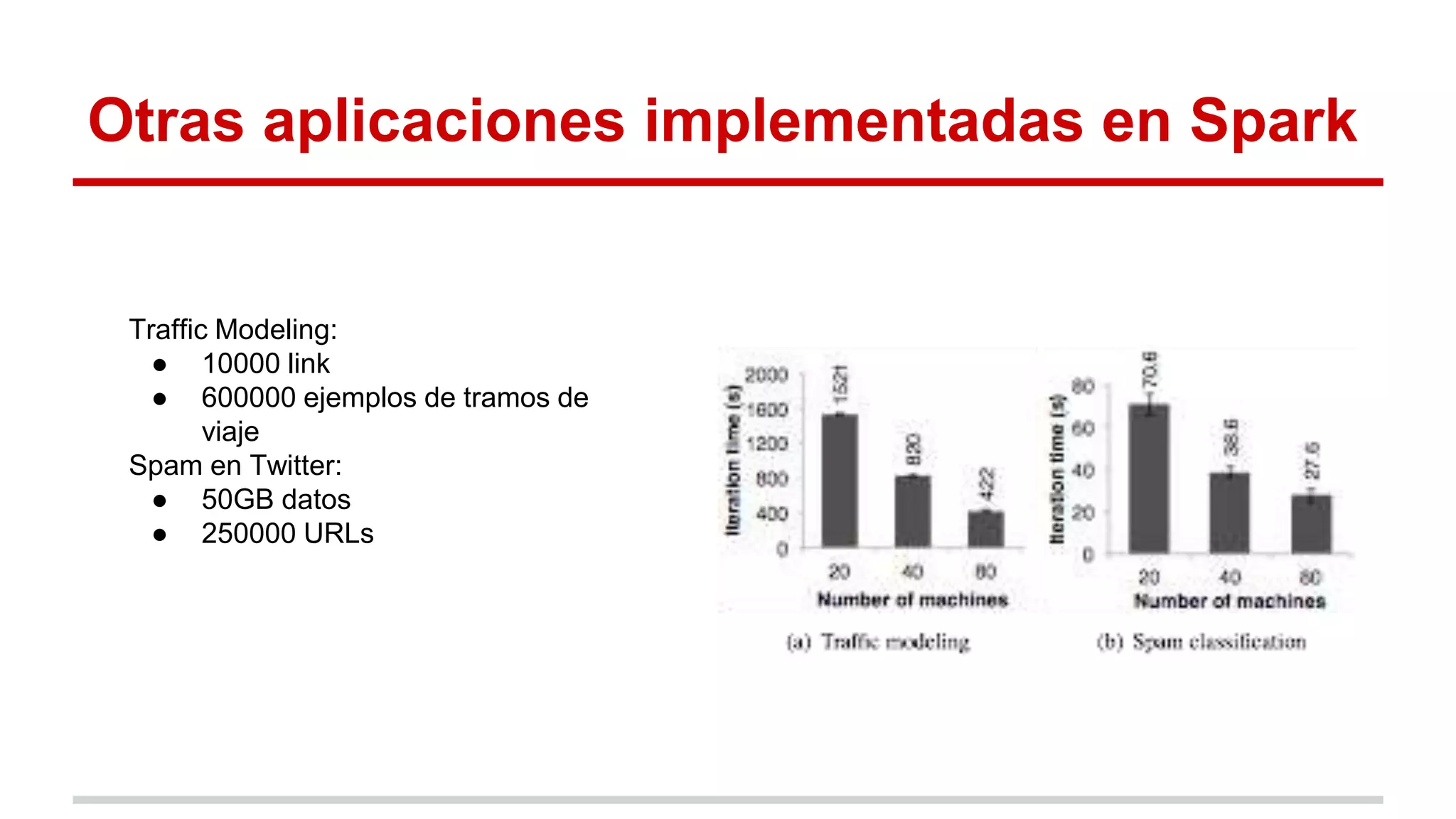
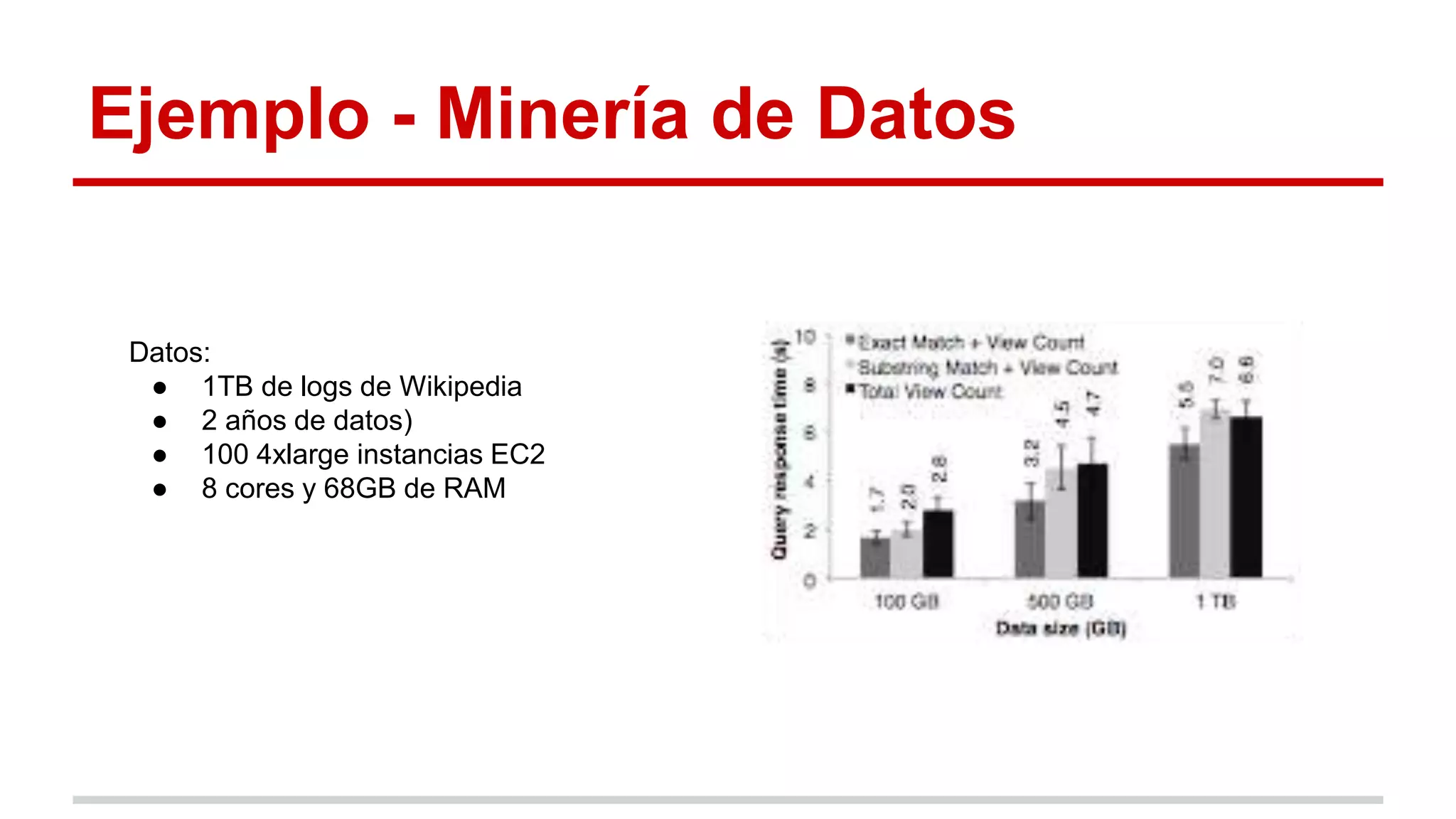














Spark es un framework para computación distribuida que introduce el concepto de Resilient Distributed Datasets (RDDs). Los RDDs permiten compartir datos entre operaciones de forma eficiente mediante transformaciones deterministas sobre datos almacenados de forma estable o sobre otros RDDs. Spark evalúa los RDDs de forma perezosa y proporciona mecanismos para recuperar los datos mediante el linaje de las transformaciones aplicadas cuando hay fallos. Las evaluaciones muestran mejoras de velocidad de hasta 20 veces frente a Hadoop en aplicaciones iterativas de machine learning.
















































































