Descargado 43 veces








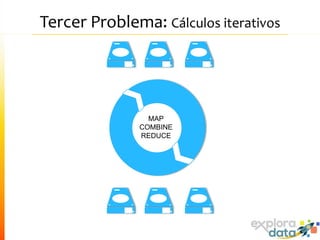




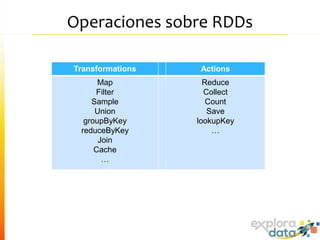





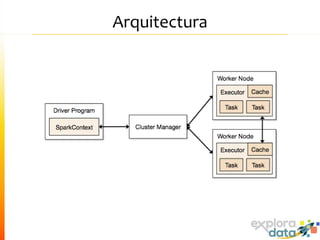





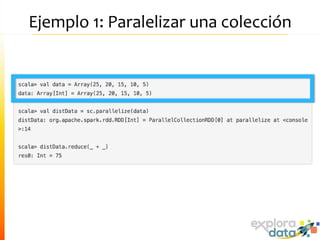
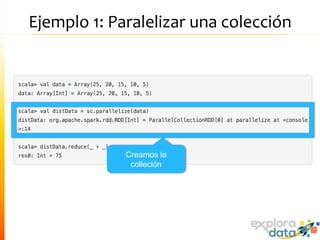


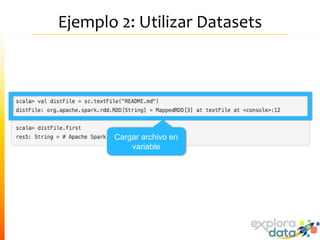





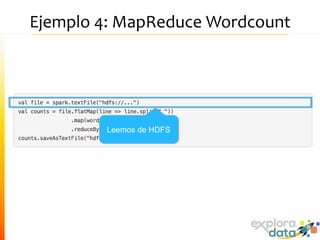



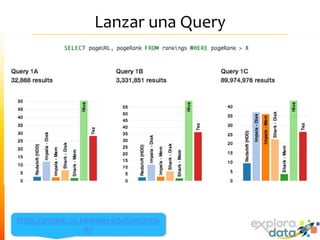


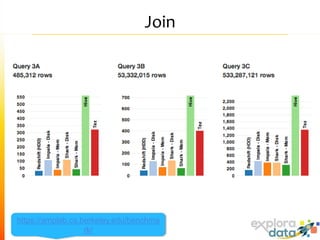







Este documento presenta Spark, un motor de procesamiento de datos en memoria. Explica que Spark mejora el paradigma MapReduce de Hadoop al usar Resilient Distributed Datasets (RDDs) que permiten operaciones iterativas. También describe características como análisis interactivo de datos, soporte para tiempo real, y una gran comunidad de usuarios. Finalmente concluye que Spark es más rápido que Hadoop para ciertos casos y que vale la pena probarlo si se usa Hadoop.




















































