Descargar para leer sin conexión





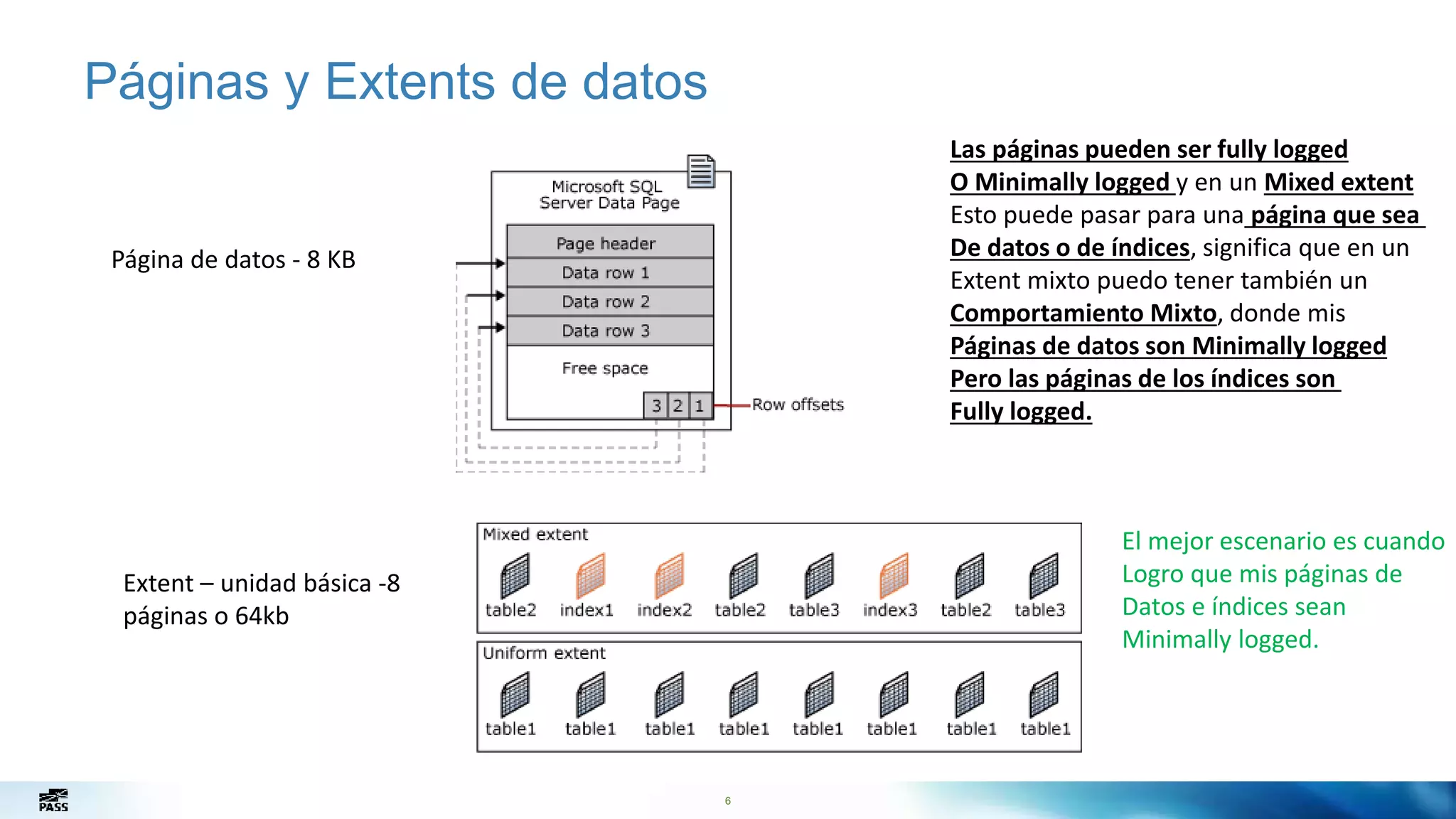













El documento presenta una guía sobre cómo optimizar las cargas de datos en bases de datos utilizando diferentes métodos como SSIS, BCP y Bulk Insert, destacando las operaciones 'minimally logged'. También se enfatiza la importancia de comprender los modelos de recuperación y el uso del traceflag 610 para mejorar el rendimiento de las operaciones de carga. Se concluye con recomendaciones sobre mejores prácticas y consideraciones al elegir el enfoque adecuado para la carga de datos.

















































































