Este documento presenta un libro de texto sobre estadística para negocios y economía en su 11a edición. El libro cubre una variedad de temas estadísticos incluyendo estadística descriptiva, probabilidad, distribuciones de probabilidad, inferencia estadística y métodos avanzados como regresión y análisis de series de tiempo. El libro es escrito por tres autores y traducido al español para su uso en América Latina.












































































































![80 Capítulo 2 Estadística descriptiva: presentaciones tabulares y gráficas
A B C D E F G
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
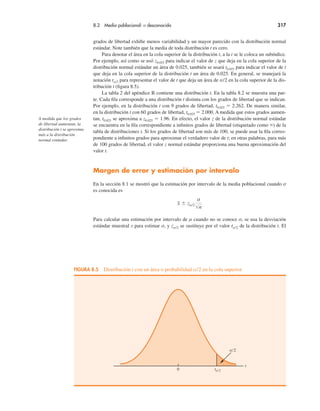
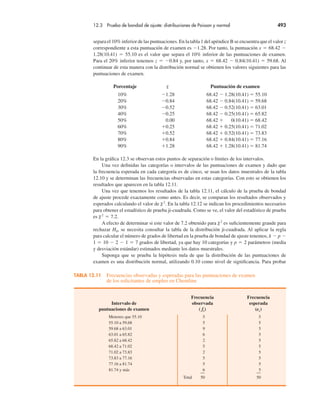
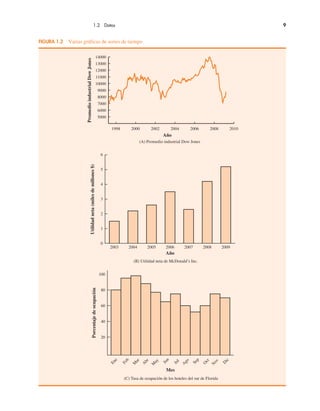
FIGURA 2.14 Lista de campo inicial e informe de campo de PivotTable para los datos
del restaurante
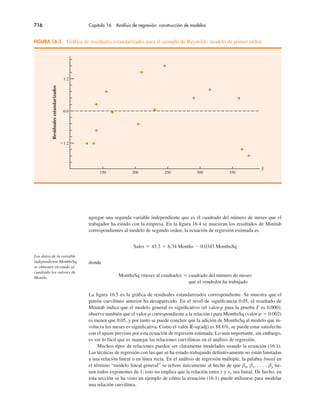
Si se desea utilizar el informe de tabla dinámica para elaborar una tabulación cruzada, se
requiere realizar tres tareas: mostrar la lista de campos de la tabla dinámica inicial y el infor-
me de tabla dinámica; establecer la lista de campos de la tabla dinámica, y finalizar el informe
de tabla dinámica. Estas tareas se describen enseguida.
Mostrar la lista de campos de la tabla dinámica inicial y el informe de tabla dinámica.
Se requieren tres pasos para mostrar la lista de campos inicial y el informe de tabla dinámica.
Paso 1. Haga clic en la ficha Insert en la cinta de opciones.
Paso 2. En el grupo Tables, haga clic en el icono sobre la palabra PivotTable.
Paso 3. Cuando el cuadro de diálogo Create PivotTable aparezca:
Elija Select a Table or Range.
Introduzca A1:C301 en el cuadro Table/Range.
Elija New Worksheet como la ubicación para PivotTable Report.
Haga clic en OK.
La lista de campo inicial de tabla dinámica y el informe de tabla dinámica se muestran en la
figura 2.14.
Configuración de la lista de campos inicial de tabla dinámica. Excel considera cada una de
las tres columnas de la figura 2.13 [etiquetadas como Restaurant, Quality Rating y Meal Price
($)] como un campo. Los campos se eligen para representar filas, columnas o valores en el
cuerpo del informe de tabla dinámica. Los pasos siguientes muestran cómo utilizar la lista de
campos de tabla dinámica de Excel para asignar el campo Quality Rating a las filas, el campo
Meal Price ($) a las columnas y el campo Restaurant al cuerpo del informe de la tabla dinámica.
Paso 1. En PivotTable Field List, vaya a Choose Fields to add to report.
Arrastre el campo Quality Rating a la sección Row Labels.
Arrastre el campo Meal Price ($) a la sección Column Labels.
Arrastre el campo Restaurant a la sección Values.](https://image.slidesharecdn.com/andersonsweeneyestadisticaparanegoci-220509164515-9735decd/85/Anderson_Sweeney_ESTADISTICA_PARA_NEGOCI-pdf-114-320.jpg)




![Chapter 3 [(H2F)] 85
Estadística descriptiva:
medidas numéricas
CONTENIDO
ESTADÍSTICA EN LA PRÁCTICA:
SMALL FRY DESIGN
3.1 MEDIDAS DE POSICIÓN
O LOCALIZACIÓN
Media
Mediana
Moda
Percentiles
Cuartiles
3.2 MEDIDAS DE VARIABILIDAD
Rango
Rango intercuartílico
Varianza
Desviación estándar
Coeficiente de variación
3.3 MEDIDAS DE LA FORMA DE
LA DISTRIBUCIÓN, POSICIÓN
RELATIVA Y DETECCIÓN DE
OBSERVACIONES ATÍPICAS
Forma de la distribución
Valor z
Teorema de Chebyshev
Regla empírica
Detección de observaciones
atípicas
3.4 ANÁLISIS EXPLORATORIO
DE DATOS
Resumen de cinco números
Diagrama de caja
3.5 MEDIDAS DE ASOCIACIÓN
ENTRE DOS VARIABLES
Covarianza
Interpretación de la covarianza
Coeficiente de correlación
Interpretación del coeficiente
de correlación
3.6 MEDIA PONDERADA
Y TRABAJO CON DATOS
AGRUPADOS
Media ponderada
Datos agrupados
CAPÍTULO 3](https://image.slidesharecdn.com/andersonsweeneyestadisticaparanegoci-220509164515-9735decd/85/Anderson_Sweeney_ESTADISTICA_PARA_NEGOCI-pdf-119-320.jpg)












![3.2 Medidas de variabilidad 99
En las tablas 3.2 y 3.3 se aprecian la suma de las desviaciones sobre la media y la suma de
las desviaciones cuadradas sobre la media. Para cualquier conjunto de datos, la suma de las des-
viaciones sobre la media siempre será igual a cero. Note que en esas tablas, !(xi ! x) " 0. Las
desviaciones positivas y negativas se cancelan entre sí, ocasionando que la suma de las desvia-
ciones sobre la media sea igual a cero.
Desviación estándar
La desviación estándar se define como la raíz cuadrada positiva de la varianza. Siguiendo la
notación que se adoptó para las varianzas muestral y poblacional, se usa s para denotar la des-
viación estándar muestral y σ para denotar la desviación estándar poblacional. La desviación
estándar se deriva de la varianza de la manera siguiente.
Recuerde que la varianza muestral para los tamaños de grupo de la muestra de cinco grupos de
estudiantes es s2
" 64. Por tanto, la desviación estándar muestral es s " "64 " 8. Para los
datos sobre los sueldos iniciales, la desviación estándar muestral es s " "27440.91 " 165.65.
¿Qué se gana al convertir la varianza en la desviación estándar correspondiente? Recuerde
que las unidades asociadas con la varianza están elevadas al cuadrado. Por ejemplo, la varianza
muestral para los datos sobre los sueldos iniciales de los licenciados en administración de em-
presas recién egresados es s2
" 27440.91 (dólares)2
. Debido a que la desviación estándar es la
raíz cuadrada de la varianza, las unidades de esta última, los dólares al cuadrado, se convierten
en dólares en la desviación estándar. Por consiguiente, la desviación estándar de los datos de
los sueldos iniciales es $165.65. En otras palabras, ésta se mide en las mismas unidades que los
datos originales; por esta razón la desviación estándar se compara más fácilmente con la media
y con otros estadísticos que se miden en las mismas unidades que los datos originales.
Coeficiente de variación
En algunas situaciones nos interesa la estadística descriptiva que indique qué tan grande es la
desviación estándar con respecto a la media. Esta medida se llama coeficiente de variación, y
se expresa por lo general como un porcentaje.
Para los datos de los tamaños de grupo, se encontró una media muestral de 44 y una des-
viación estándar muestral de 8. El coeficiente de variación es [(8/44) % 100]% " 18.2%. Ex-
presado con palabras, el coeficiente de variación indica que la desviación estándar muestral es
18.2% del valor de la media muestral. Para los datos de los sueldos iniciales con una media
muestral de 3540 y una desviación estándar muestral de 165.65, el coeficiente de variación,
[(165.65/3540) % 100]% " 4.7%, señala que la desviación estándar muestral es sólo 4.7% del
valor de la media muestral. En general, el coeficiente de variación es un estadístico útil para
comparar la variabilidad de las variables que tienen tanto desviaciones estándar como medias
distintas.
DESVIACIÓN ESTÁNDAR
Desviación estándar muestral " s " "s2
(3.6)
Desviación estándar poblacional " σ " "σ2
(3.7)
La desviación estándar
muestral s es el estimador
de la desviación estándar
poblacional σ.
COEFICIENTE DE VARIACIÓN
desviación estándar
media
% 100 % (3.8)
La desviación estándar es
más fácil de interpretar que
la varianza debido a que
se mide en las mismas
unidades que los datos.
El coeficiente de variación
es una medida relativa de
la variabilidad; mide la
desviación estándar con
respecto a la media.](https://image.slidesharecdn.com/andersonsweeneyestadisticaparanegoci-220509164515-9735decd/85/Anderson_Sweeney_ESTADISTICA_PARA_NEGOCI-pdf-133-320.jpg)























































































![Chapter 3 [(H2F)] 193
Distribuciones de probabilidad
discreta
CONTENIDO
ESTADÍSTICA EN LA PRÁCTICA:
CITIBANK
5.1 VARIABLES ALEATORIAS
Variables aleatorias discretas
Variables aleatorias continuas
5.2 DISTRIBUCIONES DE
PROBABILIDAD DISCRETA
5.3 VALOR ESPERADO
Y VARIANZA
Valor esperado
Varianza
5.4 DISTRIBUCIÓN DE
PROBABILIDAD BINOMIAL
Un experimento binomial
El problema de Martin Clothing
Store
Uso de tablas de probabilidades
binomiales
Valor esperado y varianza
de la distribución binomial
5.5 DISTRIBUCIÓN DE
PROBABILIDAD
DE POISSON
Un ejemplo con intervalos
de tiempo
Un ejemplo con intervalos
de longitud o de distancia
5.6 DISTRIBUCIÓN
DE PROBABILIDAD
HIPERGEOMÉTRICA
CAPÍTULO 5](https://image.slidesharecdn.com/andersonsweeneyestadisticaparanegoci-220509164515-9735decd/85/Anderson_Sweeney_ESTADISTICA_PARA_NEGOCI-pdf-227-320.jpg)






























![224 Capítulo 5 Distribuciones de probabilidad discreta
49. El blackjack o veintiuno, como se le llama con frecuencia, es un juego de apuestas popular
en los casinos de Las Vegas. A un jugador se le reparten dos cartas. Las figuras (jotas, reinas
y reyes) y los dieces tienen un valor de 10. Los ases tienen un valor de 1 u 11. Una baraja de
52 cartas contiene 16 con un valor de puntos de 10 (jotas, reinas, reyes y dieces) y cuatro ases.
a) ¿Cuál es la probabilidad de que las dos cartas repartidas sean ases o cartas de 10 puntos?
b) ¿Cuál es la probabilidad de que ambas sean ases?
c) ¿Cuál es la probabilidad de que las dos tengan un valor de 10?
d) Un blackjack es una carta de 10 puntos y un as que dan un valor de 21. Use las respuestas
de los incisos a), b) y c) para determinar la probabilidad de que a un jugador le repartan
un blackjack. [Pista. El inciso d) no es un problema hipergeométrico. Elabore una rela-
ción lógica propia de cómo las probabilidades hipergeométricas de los incisos a), b) y c)
pueden combinarse para responder esta pregunta.]
50. Axline Computers fabrica computadoras personales en dos plantas, una en Texas y la otra en
Hawaii. La planta de Texas cuenta con 40 empleados y la de Hawaii con 20. A una muestra
aleatoria de 10 empleados se le pedirá que llene un cuestionario de beneficios.
a) ¿Cuál es la probabilidad de que ninguno de los empleados de la muestra trabaje en la plan-
ta de Hawaii?
b) ¿Cuál es la probabilidad de que uno de estos empleados trabaje en la planta de Hawaii?
c) ¿Cuál es la probabilidad de que dos o más sujetos de la muestra labore en la planta de
Hawaii?
d) ¿Cuál es la probabilidad de que nueve de los empleados trabajen en la planta de Texas?
51. La encuesta de restaurantes de ZAGAT proporciona las calificaciones de los platillos, la de-
coración y el servicio de algunos restaurantes de Estados Unidos. Para 15 establecimientos
ubicados en Boston, el precio medio de una cena, incluyendo una bebida y la propina, es de
$48.60. Usted está de viaje de negocios en Boston y cenará en tres de estos restaurantes. Su
empresa le rembolsará un máximo de $50 por cena. Los socios de negocios familiarizados con
estos establecimientos le han dicho que el costo de la cena en un tercio de los restaurantes de
la encuesta rebasa los $50. Suponga que selecciona al azar tres de estos negocios para comer.
a) ¿Cuál es la probabilidad de que ninguna de las cenas rebase el costo que cubre su empresa?
b) ¿Cuál es la probabilidad de que una de las cenas supere el costo que cubre su empresa?
c) ¿Cuál es la probabilidad de que dos de las cenas rebasen tal costo?
d) ¿Cuál es la probabilidad de que tres de las cenas rebasen dicho costo?
52. El Troubled Asset Relief Program (TARP), aprobado por el Congreso de Estados Unidos en
octubre de 2008, aportó $700000 millones como apoyo financiero para que la economía del
país saliera adelante. Más de $200000 millones se destinaron a instituciones financieras con
problemas con la esperanza de que hubiera un incremento en los créditos para ayudar a reacti-
var la economía. Pero tres meses después, una encuesta de la Reserva Federal reveló que dos
tercios de los bancos que recibieron fondos del TARP habían restringido las condiciones de los
créditos empresariales (The Wall Street Journal, 3 de febrero de 2009). De los 10 principales
bancos receptores de fondos del TARP, sólo tres incrementaron realmente los créditos durante
el periodo.
Incremento en los créditos Disminución en los créditos
BB&T Bank of America
Sun Trust Banks Capital One
U.S. Bancorp Citigroup
Fifth Third Bancorp
J.P. Morgan Chase
Regions Financial
U.S. Bancorp
AUTO evaluación](https://image.slidesharecdn.com/andersonsweeneyestadisticaparanegoci-220509164515-9735decd/85/Anderson_Sweeney_ESTADISTICA_PARA_NEGOCI-pdf-258-320.jpg)





















![246 Capítulo 6 Distribuciones de probabilidad continua
Un valor de x igual a su media µ da como resultado z ! (µ " µ)/σ ! 0. Por tanto, vemos
que un valor de x igual a su media µ corresponde a z ! 0. Ahora suponga que x está a una des-
viación estándar por encima de su media; es decir, x ! µ # σ. Al aplicar la ecuación (6.3),
vemos que el valor de z correspondiente es z ! [(µ # σ) " µ]/σ ! σ/σ ! 1. En consecuencia,
un valor de x que está a una desviación estándar sobre su media corresponde a z ! 1. En otras
palabras, z puede interpretarse como el número de desviaciones estándar de la media µ a las
que está la variable aleatoria normal x.
Para ver cómo esta conversión permite calcular las probabilidades de cualquier distribu-
ción normal, suponga que se tiene una distribución con µ ! 10 y σ ! 2. ¿Cuál es la probabili-
dad de que la variable aleatoria x esté entre 10 y 14? Aplicando la ecuación (6.3) vemos que
en x ! 10, z ! (x " µ)/σ ! (10 " 10)/2 ! 0 y que en x ! 14, z ! (14 " 10)/2 ! 4/2 ! 2. Por
tanto, la respuesta a nuestra pregunta sobre la probabilidad de que x esté entre 10 y 14 está dada
por la probabilidad equivalente de que z esté entre 0 y 2 para la distribución normal estándar.
En otras palabras, la probabilidad que se busca estriba en que la variable aleatoria x esté entre
su media y a dos desviaciones estándar sobre la media. Al usar z ! 2.00 y la tabla de proba-
bilidad normal estándar de las guardas de la cubierta anterior del libro, P(z $ 2) ! 0.9772.
Como P(z $ 0) ! 0.5000, podemos calcular P(0.00 $ z $ 2.00) ! P(z $ 2) " P(z $ 0) !
0.9772 " 0.5000 ! 0.4772. De ahí que la probabilidad de que x esté entre 10 y 14 sea 0.4772.
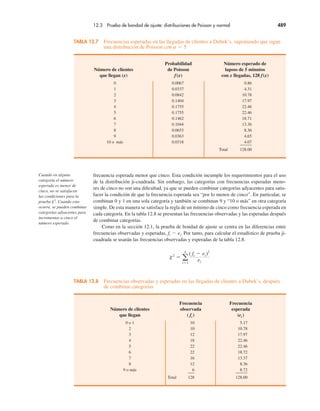
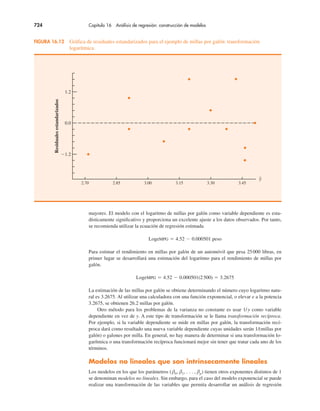
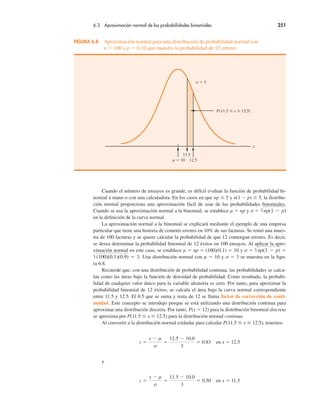
El problema de Grear Tire Company
Ahora veremos una aplicación de la distribución de probabilidad normal. Suponga que Grear
Tire Company desarrolló un nuevo neumático radial con cinturón de acero que se vende a tra-
vés de una cadena nacional de tiendas de descuento. Debido a que el neumático es un nuevo
producto, los gerentes de Grear creen que la garantía de millaje ofrecida con la llanta será un
factor importante para su aceptación. Antes de que la póliza de garantía de millaje de los neu-
máticos caduque, los gerentes de Grear quieren información de probabilidad sobre los x !
número de millas que éstos durarán.
A partir de las pruebas de carretera reales con los neumáticos, el grupo de ingeniería esti-
mó que su millaje es µ ! 36500 millas y que la desviación estándar es σ ! 5000. Además,
los datos recabados indican que una distribución normal es una suposición razonable. ¿Qué
porcentaje de las llantas se espera que dure más de 40000 millas? En otras palabras, ¿cuál es
la probabilidad de que el millaje de los neumáticos, x, supere la cifra de 40000? Esta pregunta
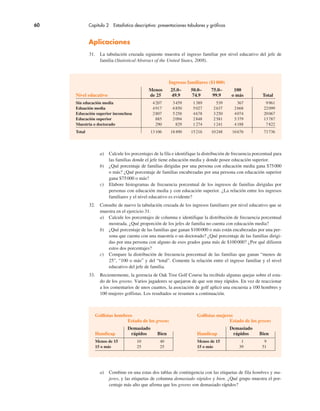
puede responderse al calcular el área de la región sombreada de la figura 6.6.
FIGURA 6.6 Distribución de millaje de Grear Tire Company
x
40000
P(x ! 40000) " ?
µ " 36500
z
0.70
0
z " 0 corresponde
a x " µ " 36500
Nota. z " 0.70 corresponde
a x " 40000
Nota.
P(x # 40000)
σ " 5 000](https://image.slidesharecdn.com/andersonsweeneyestadisticaparanegoci-220509164515-9735decd/85/Anderson_Sweeney_ESTADISTICA_PARA_NEGOCI-pdf-280-320.jpg)

















![Chapter 3 [(H2F)] 265
Muestreo y distribuciones
de muestreo
CONTENIDO
ESTADÍSTICA EN LA PRÁCTICA:
MEADWESTVACO CORPORATION
7.1 EL PROBLEMA
DE MUESTREO DE
ELECTRONICS ASSOCIATES
7.2 SELECCIÓN DE
UNA MUESTRA
Muestreo de una población finita
Muestreo de una población
infinita
7.3 ESTIMACIÓN PUNTUAL
Consejo práctico
7.4 INTRODUCCIÓN A
LAS DISTRIBUCIONES
MUESTRALES O
DE MUESTREO
7.5 DISTRIBUCIÓN DE
MUESTREO DE x
Valor esperado de x
Desviación estándar de x
Forma de la distribución
de muestreo de x
Distribución de muestreo de x
en el problema EAI
Valor práctico de la distribución
de muestreo de x
Relación entre el tamaño de
la muestra y la distribución
de muestreo de x
7.6 DISTRIBUCIÓN
DE MUESTREO DE p
Valor esperado de p
Desviación estándar de p
Forma de la distribución
de muestreo de p
Valor práctico de la distribución
de muestreo de p
7.7 PROPIEDADES DE LOS
ESTIMADORES PUNTUALES
Insesgadez
Eficiencia
Consistencia
7.8 OTROS MÉTODOS
DE MUESTREO
Muestreo aleatorio estratificado
Muestreo por conglomerados
Muestreo sistemático
Muestreo de conveniencia
Muestreo subjetivo
CAPÍTULO 7](https://image.slidesharecdn.com/andersonsweeneyestadisticaparanegoci-220509164515-9735decd/85/Anderson_Sweeney_ESTADISTICA_PARA_NEGOCI-pdf-299-320.jpg)





































![304 Capítulo 7 Muestreo y distribuciones de muestreo
54. Lori Jeffrey es una exitosa representante de ventas de libros universitarios. Históricamente,
ella consigue una adopción de libros de texto en 25% de sus llamadas de ventas. Considere sus
telefonemas de ventas de un mes como muestra de todas sus posibles llamadas; suponga que en
el análisis estadístico de los datos se encuentra que el error estándar de la proporción es 0.0625.
a) ¿De qué tamaño fue la muestra que se utilizó en el análisis? Es decir, ¿cuántas llamadas
hizo Lori Jeffrey en ese mes?
b) Sea p la proporción muestral de adopciones de libros de texto en el mes. Presente la distri-
bución de muestreo de p.
c) Mediante la distribución de muestreo de p, calcule la probabilidad de que Lori logrará
adopciones de libros de texto en 30% o más de sus llamadas de ventas en el lapso de un
mes.
Apéndice 7.1 Valor esperado y desviación estándar de x
En este apéndice se presentan las bases matemáticas de las expresiones E(x), valor esperado
de x dado en la ecuación (7.1), y σx, la desviación estándar de x dada por la ecuación (7.2).
Valor esperado de x
Se tiene una población con media µ y varianza σ2
. Se selecciona una muestra aleatoria sim-
ple de tamaño n cuyas observaciones individuales se denotan x1, x2, . . . , xn. La media muestral
x se calcula como sigue.
x !
!xi
n
Si se repiten los muestreos aleatorios simples de tamaño n, x será una variable aleatoria que
tomará diferentes valores dependiendo de los n elementos que formen la muestra. El valor espe-
rado de la variable aleatoria x es la media de todos los posibles valores de x.
Media de x ! E(x) ! E
!xi
n
!
1
n
[E(x1 & x2 & . . . & xn)]
!
1
n
[E(x1) & E(x2) & . . . & E(xn)]
Para cada xi se tiene E(xi) ! µ; por tanto, escribimos
E(x) !
1
n
(µ & µ & . . . & µ)
!
1
n
(nµ) ! µ
Este resultado indica que la media de todos los posibles valores de x es igual a la media pobla-
cional µ. Es decir, E(x) ! µ.
Desviación estándar de x
Se tiene, de nuevo, una población con media µ y varianza σ2
, y una media muestral dada por
x !
!xi
n](https://image.slidesharecdn.com/andersonsweeneyestadisticaparanegoci-220509164515-9735decd/85/Anderson_Sweeney_ESTADISTICA_PARA_NEGOCI-pdf-338-320.jpg)
![Apéndice 7.1 Valor esperado y desviación estándar de x 305
Se sabe que x es una variable aleatoria que toma distintos valores numéricos, con repetidas
muestras aleatorias simples de tamaño n, dependiendo de los n elementos que integran la mues-
tra. Lo que sigue es una derivación de la fórmula para la desviación estándar de los valores de
x, σx, en el caso de que la población sea infinita. La deducción de la fórmula para σx cuando la
población es finita y el muestreo se realiza sin remplazo es más complicada, y queda fuera de
los alcances de este libro.
De vuelta al caso de una población infinita, recuerde que una muestra aleatoria simple de
una población infinita consta de observaciones x1, x2, . . . , xn que son independientes. Las dos
expresiones siguientes son fórmulas generales para la varianza de variables aleatorias.
Var(ax) ! a2
Var(x)
donde a es una constante y x es una variable aleatoria, y
Var(x & y) ! Var(x) & Var(y)
donde x y y son variables aleatorias independientes. Utilizando las dos ecuaciones anteriores,
se puede deducir la fórmula para la varianza de la variable aleatoria x como sigue.
Var(x) ! Var
!xi
n
! Var
1
n !xi
Entonces, como 1/n es una constante, tenemos
Var(x) !
1
n
2
Var(!xi)
!
1
n
2
Var(x1 & x2 & . . . & xn)
En el caso de una población infinita, las variables aleatorias x1, x2, …, xn son independientes, lo
que permite escribir
Var(x) !
1
n
2
[Var(x1) & Var(x2) & . . . & Var(xn)]
Para toda xi se tiene Var(xi) ! σ2
; por tanto, obtenemos
Var(x) !
1
n
2
(σ2
& σ2
& . . . & σ2
]
Como en esta expresión hay n valores σ2
, tenemos
Var(x) !
1
n
2
(nσ2
) !
σ2
n
Calculando ahora la raíz cuadrada, se obtiene la fórmula de la desviación estándar de x.
σx ! "Var(x) !
σ
"n](https://image.slidesharecdn.com/andersonsweeneyestadisticaparanegoci-220509164515-9735decd/85/Anderson_Sweeney_ESTADISTICA_PARA_NEGOCI-pdf-339-320.jpg)