Descargar para leer sin conexión



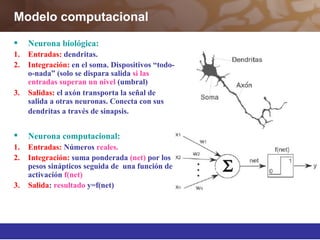

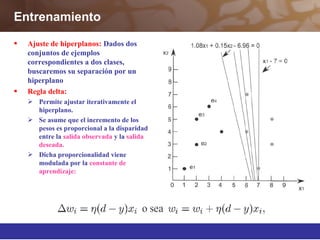


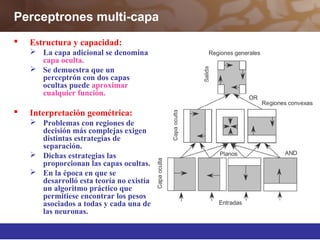
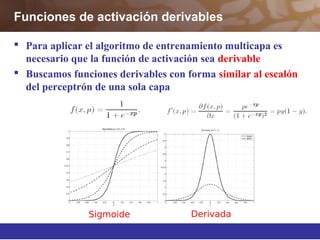







Este documento describe diferentes técnicas de aprendizaje automático como el perceptrón multicapa y el algoritmo de retropropagación. Explica cómo el perceptrón multicapa, con múltiples capas ocultas, puede aproximar cualquier función mediante la introducción de hiperplanos complejos. También describe el algoritmo de retropropagación para entrenar redes neuronales multicapa mediante la propagación hacia atrás de los errores y la actualización de los pesos para minimizar dichos errores.










































































