Descargado 267 veces


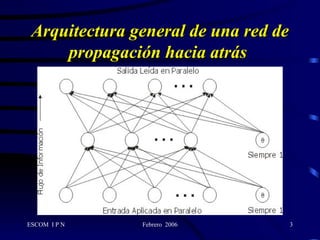
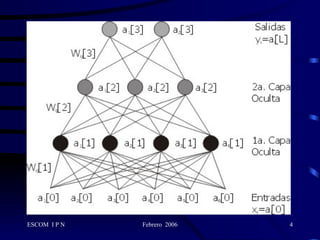
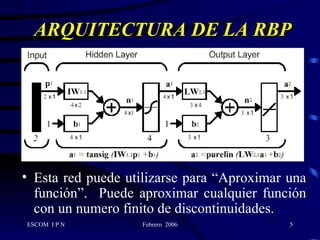









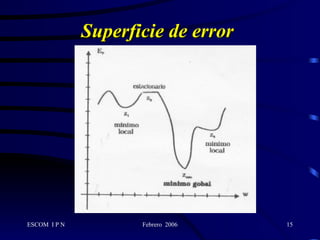











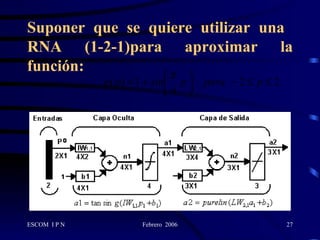













Este documento describe la arquitectura y el algoritmo de aprendizaje de las redes neuronales de retropropagación. Estas redes multicapas utilizan un método de aprendizaje supervisado llamado retropropagación del error para ajustar los pesos de las conexiones entre neuronas y minimizar el error entre la salida de la red y la salida deseada. El algoritmo consta de dos fases: propagación y retropropagación del error para actualizar los pesos y reducir progresivamente el error total de la red.






































































































