Descargar para leer sin conexión















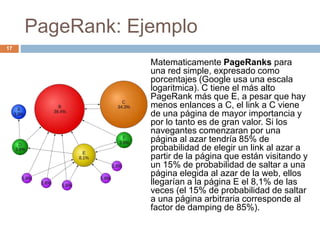



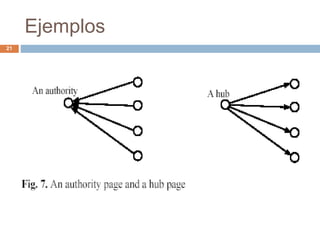






Este documento introduce los conceptos de análisis de enlaces y redes sociales en la Web. Explica dos algoritmos influyentes para clasificar páginas web: PageRank y HITS. PageRank clasifica páginas basadas en el prestigio que reciben de otras páginas, mientras que HITS clasifica páginas en autoridades y hubs dependiendo de la consulta. Ambos algoritmos explotan la estructura de hipervínculos entre páginas para mejorar los resultados de búsqueda.

















































































