Descargar para leer sin conexión

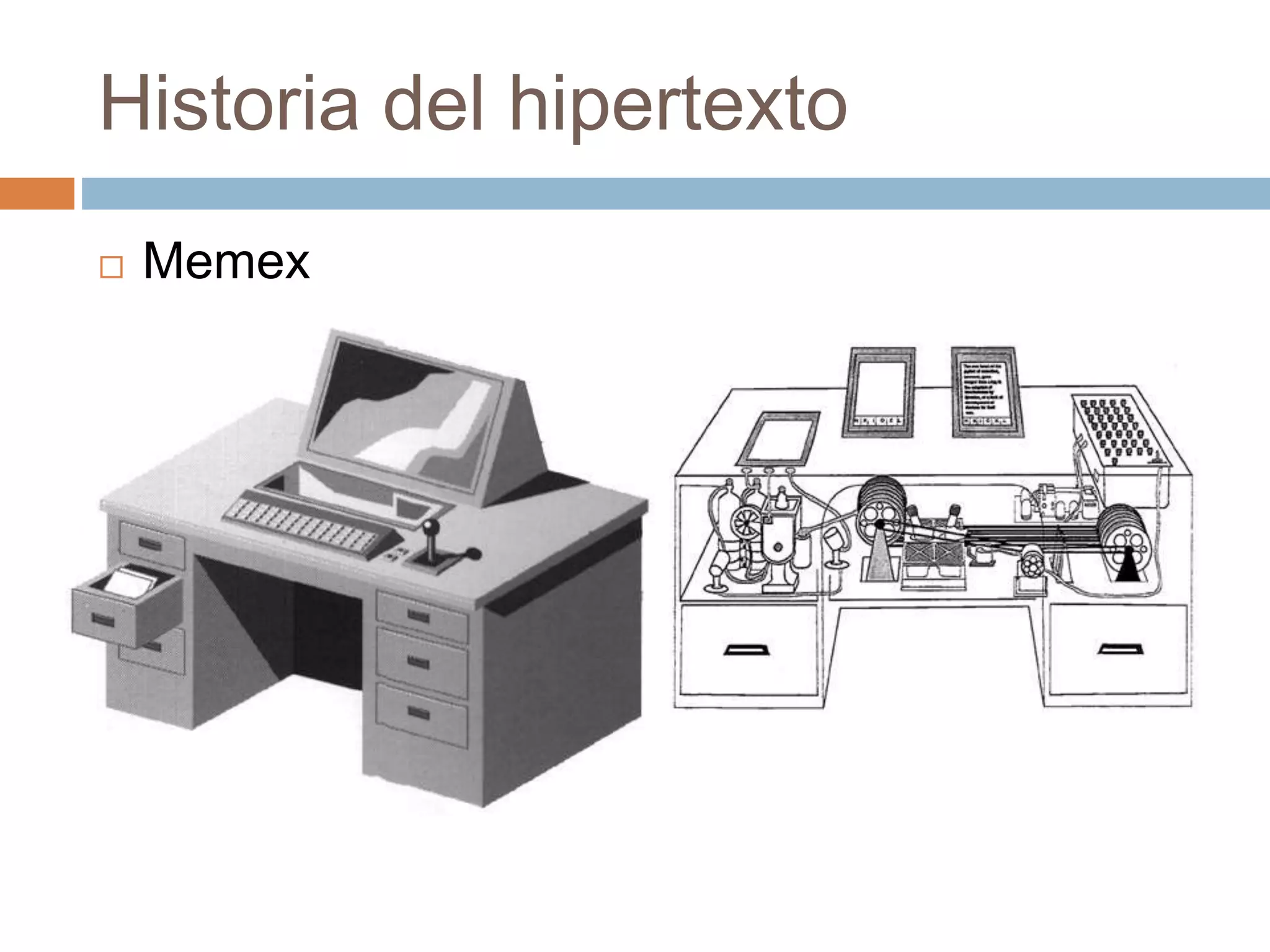
![Historia del hipertexto
Memex [Vannevar Bush, 1945]
extension de memoria (“memory extension”)
dispositivo de almacenamiento y
computación (fotoeléctrico y mecánico)
objetivo: crear y ayudar a seguir
hiperenlaces a través de documentos.
El concepto de Memex influenció el desarrollo de
sistemas de hipertexto (liderando la creación de la
World Wide Web) y bases de software para
conocimiento personal.](https://image.slidesharecdn.com/webmining-introduccin-160725192928/75/Introduccion-a-Web-Mining-2-2048.jpg)

![La hipótesis de la web
estructurada
La información de la web es suficientemente
estructurada como para que sea posible la
minería de la Web [Etzioni, 1996].](https://image.slidesharecdn.com/webmining-introduccin-160725192928/75/Introduccion-a-Web-Mining-5-2048.jpg)



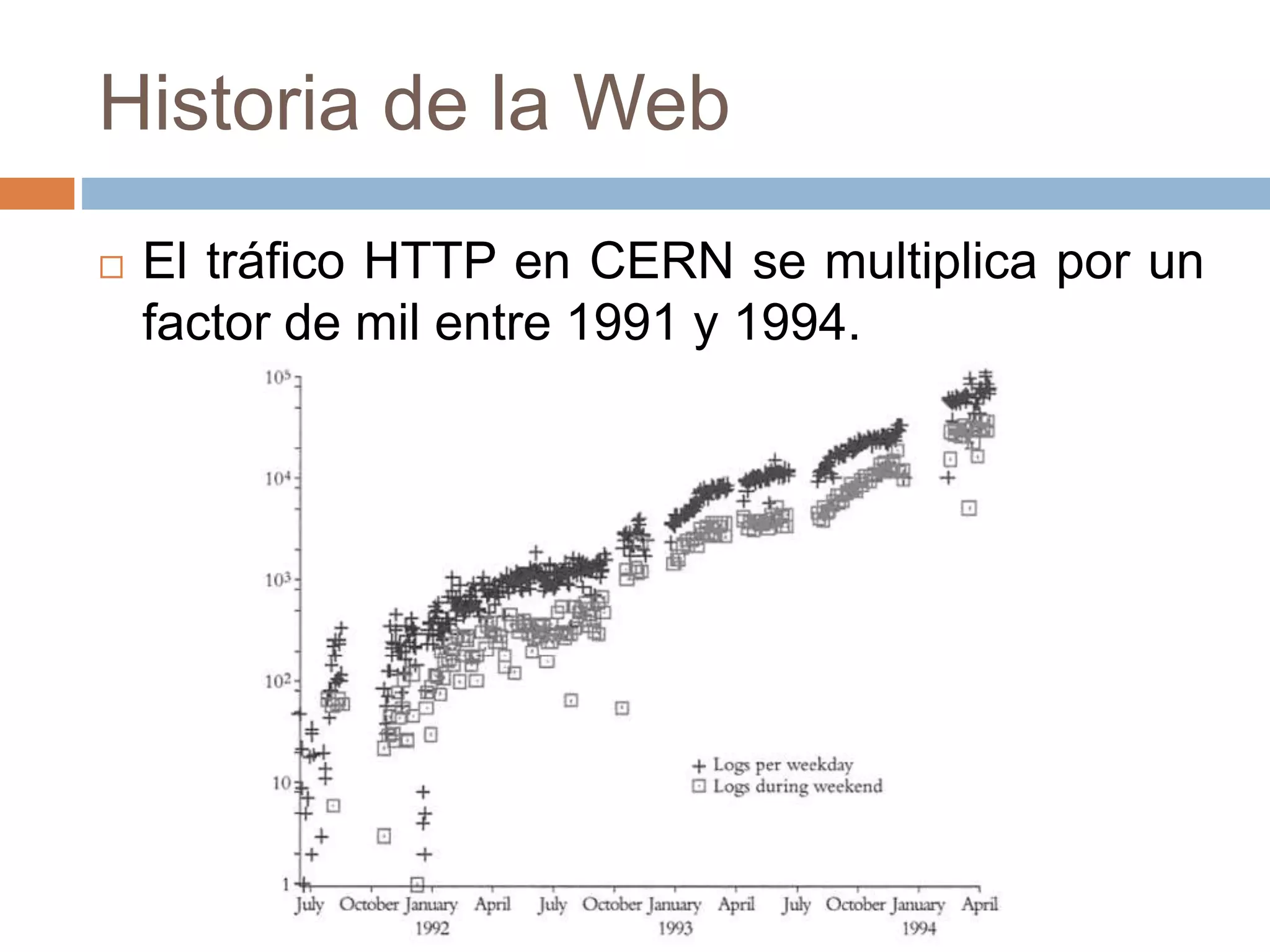
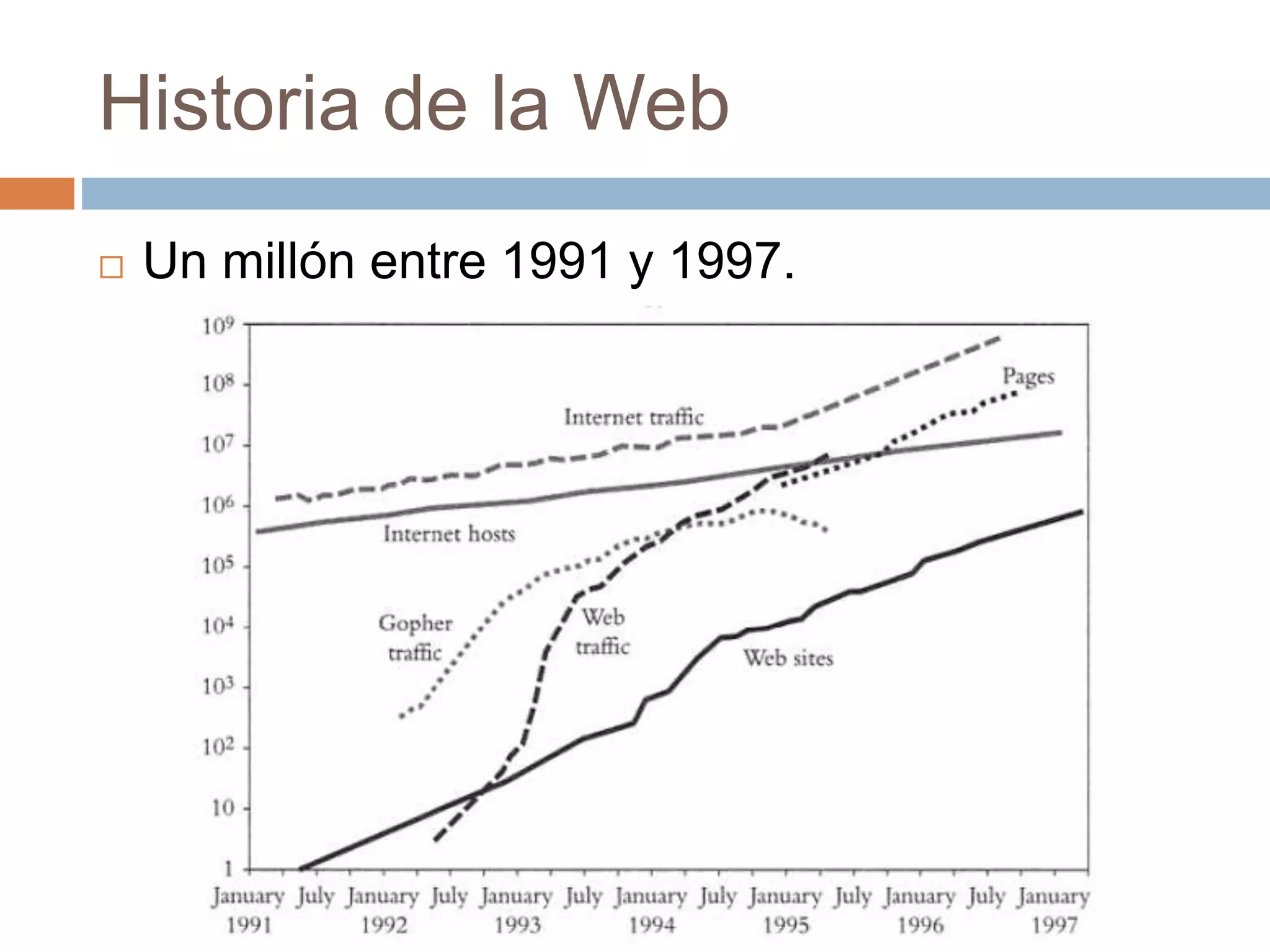
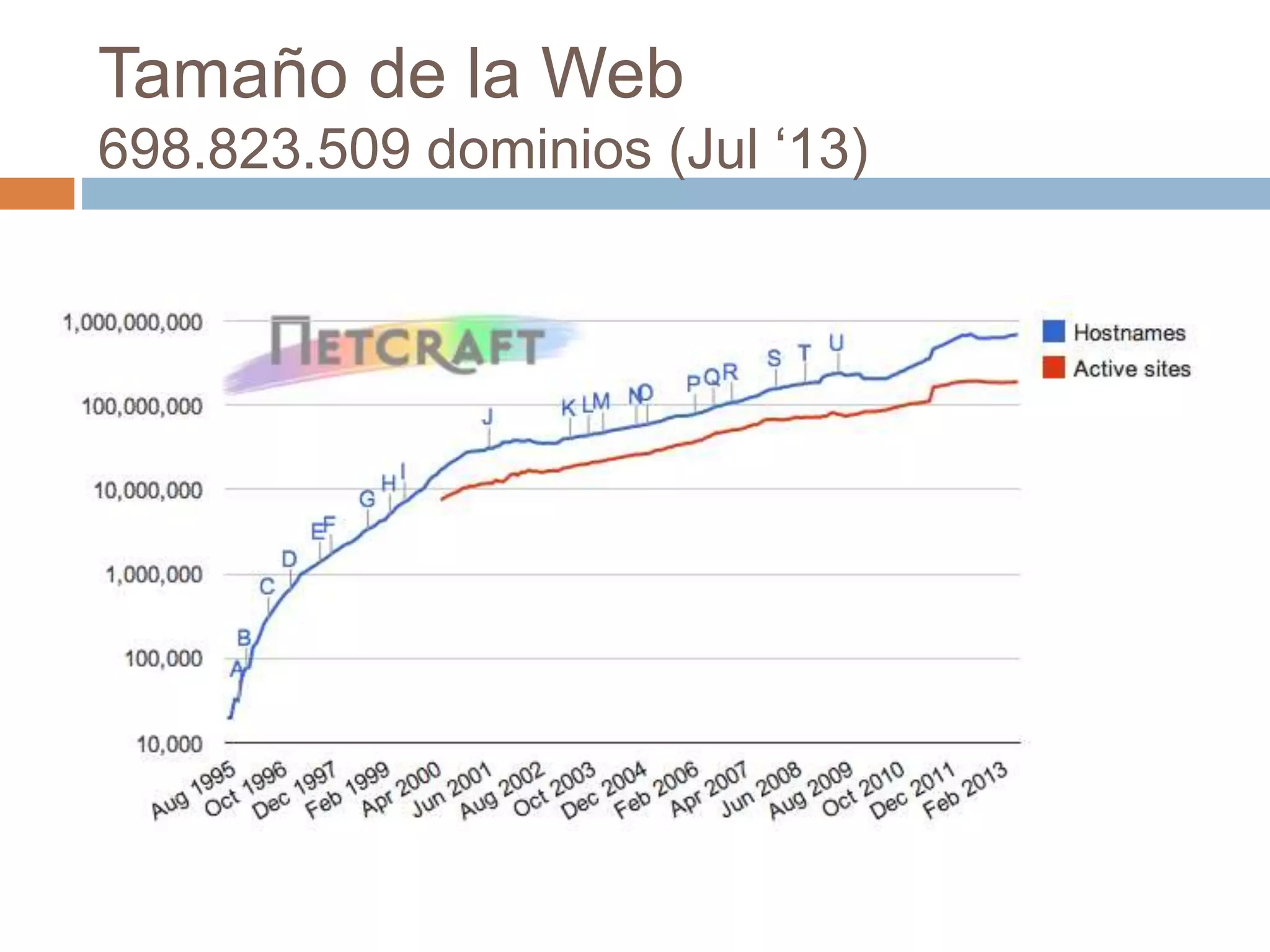

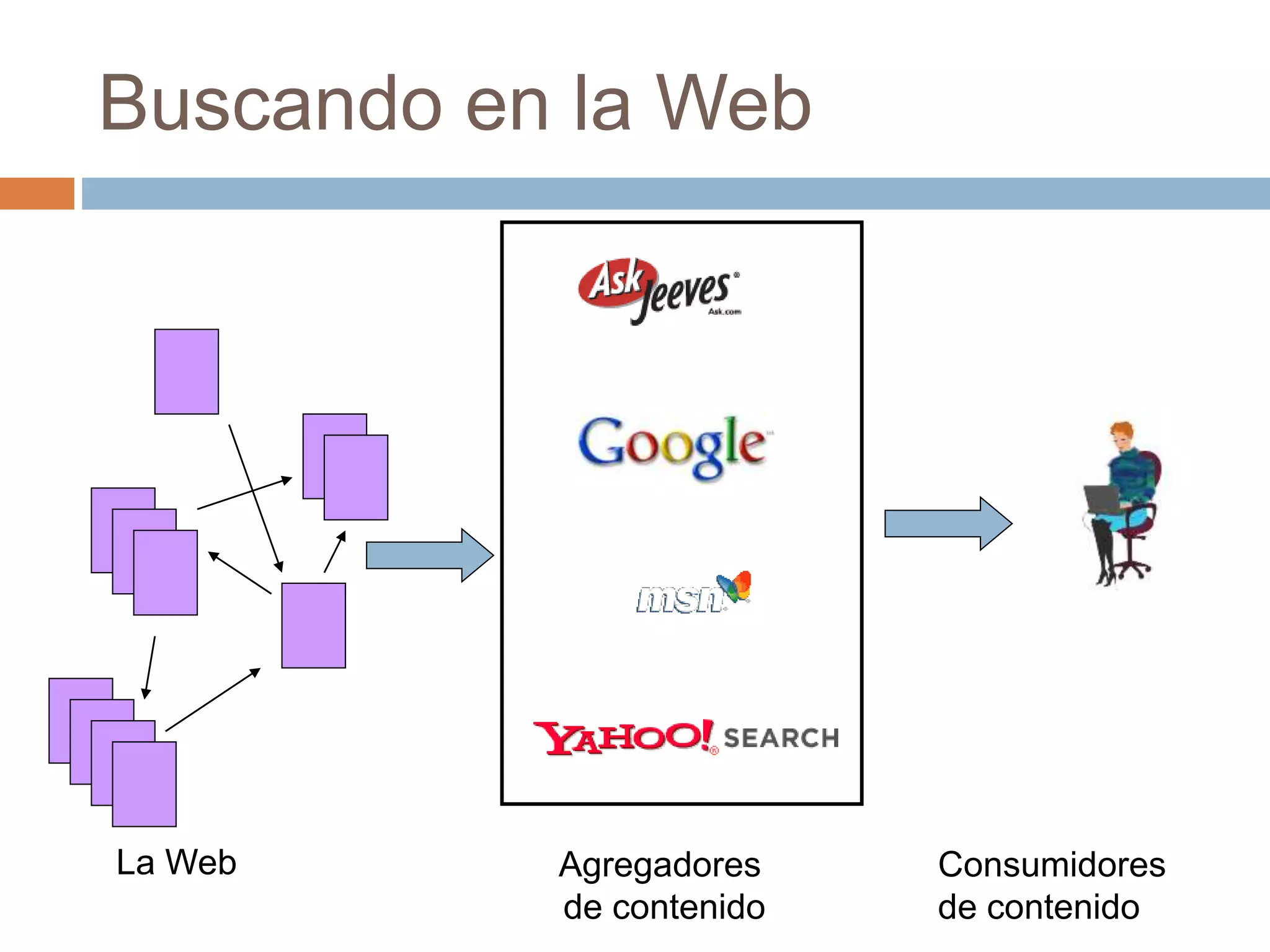





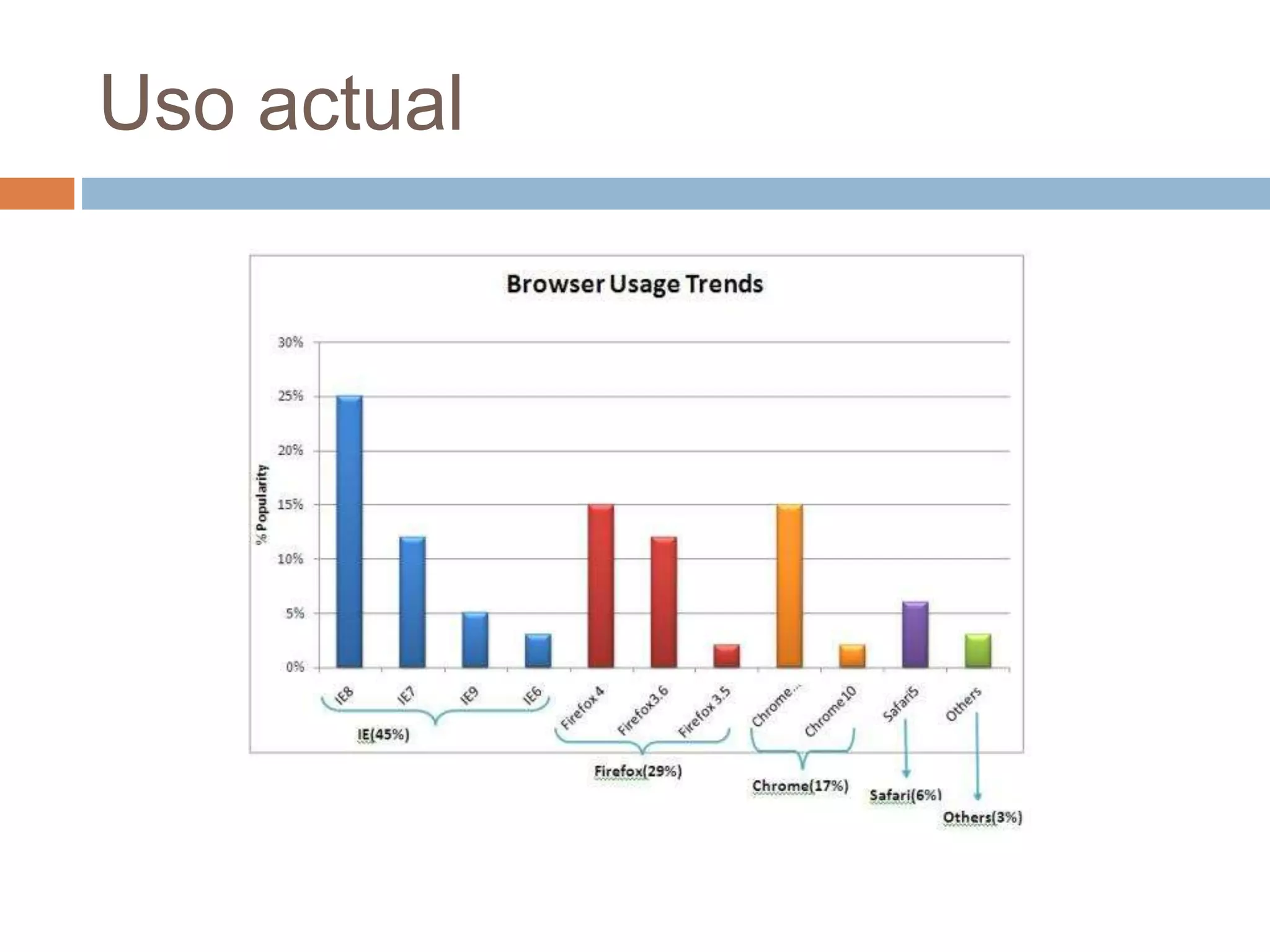



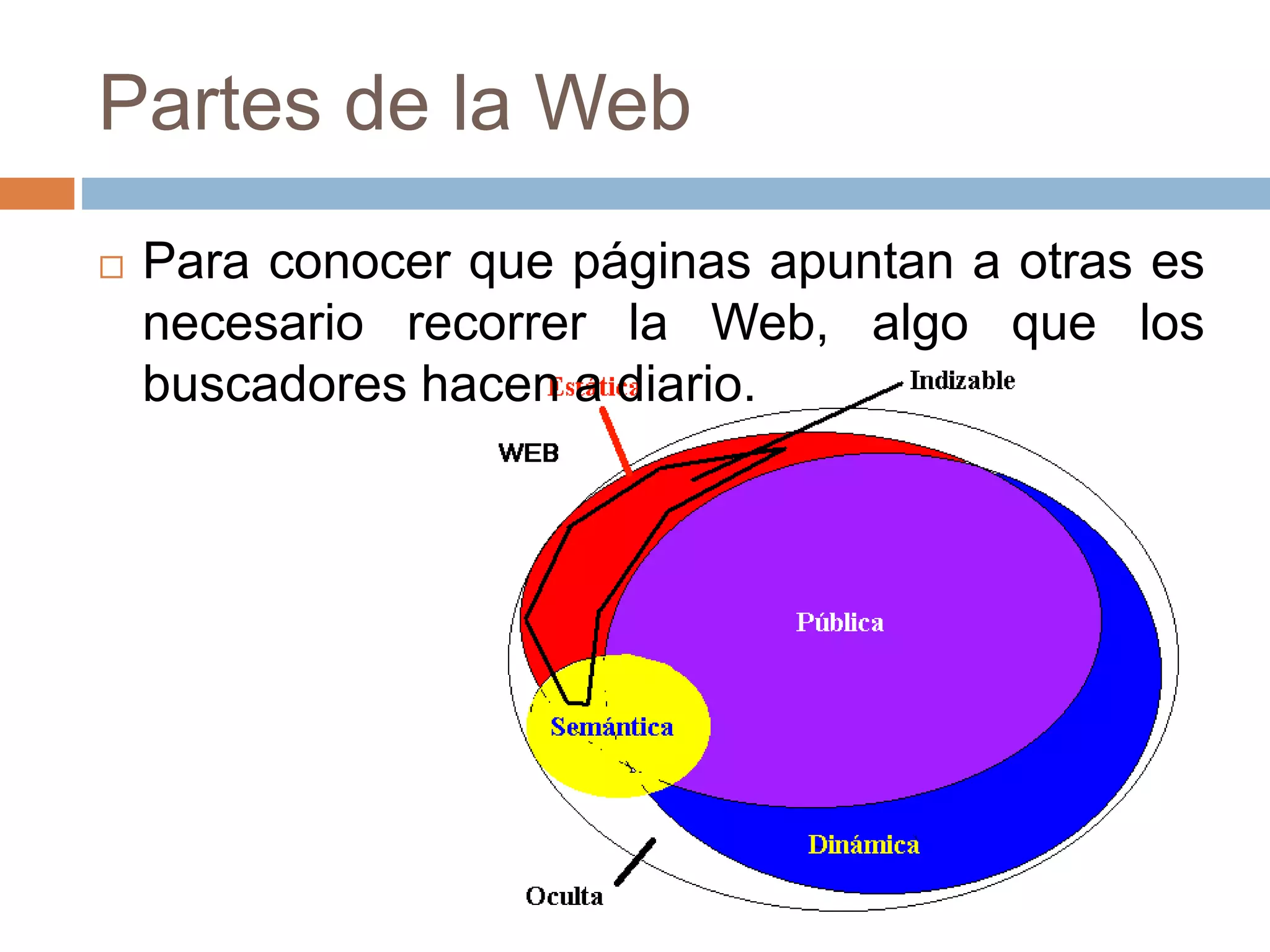


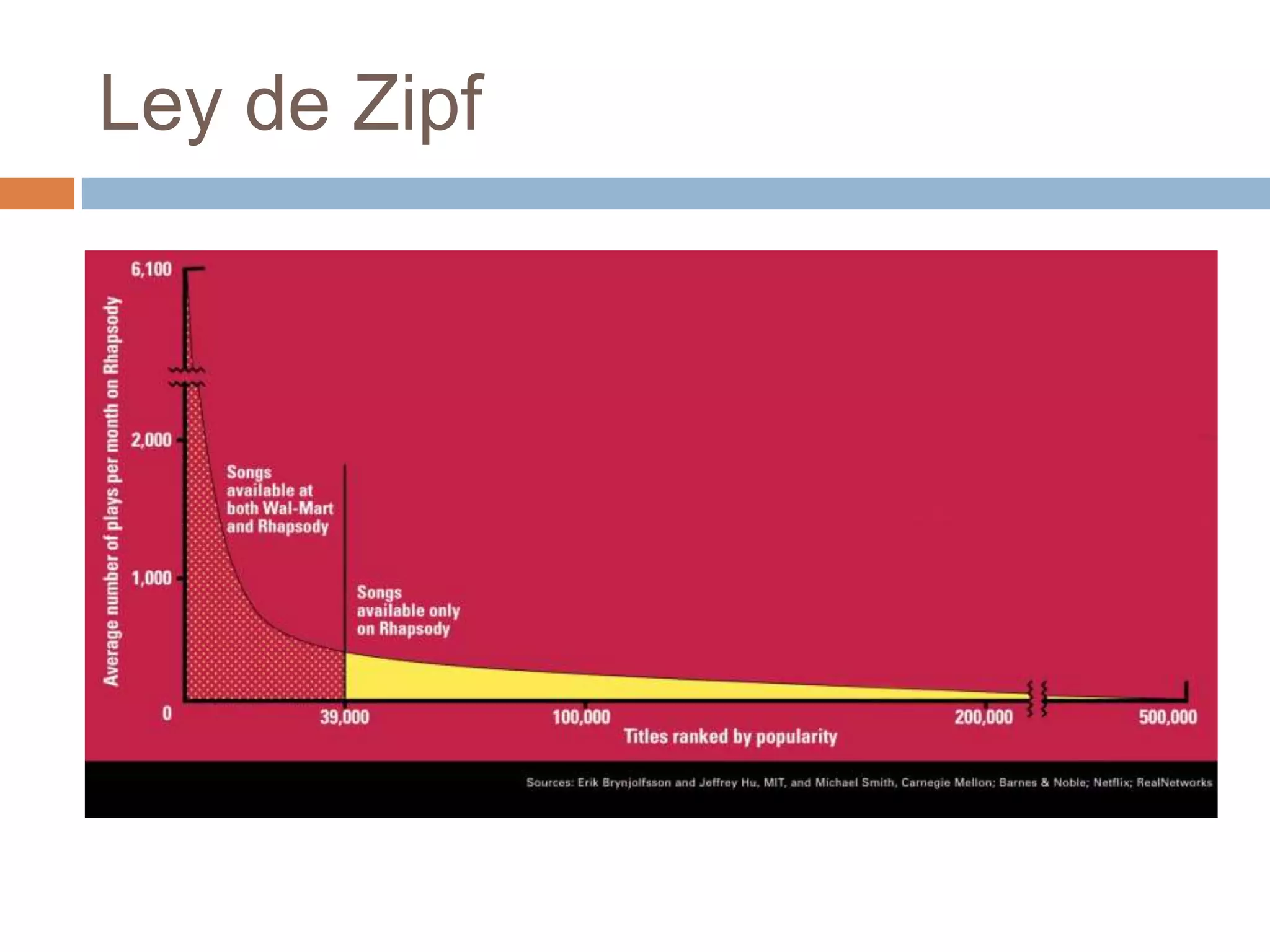





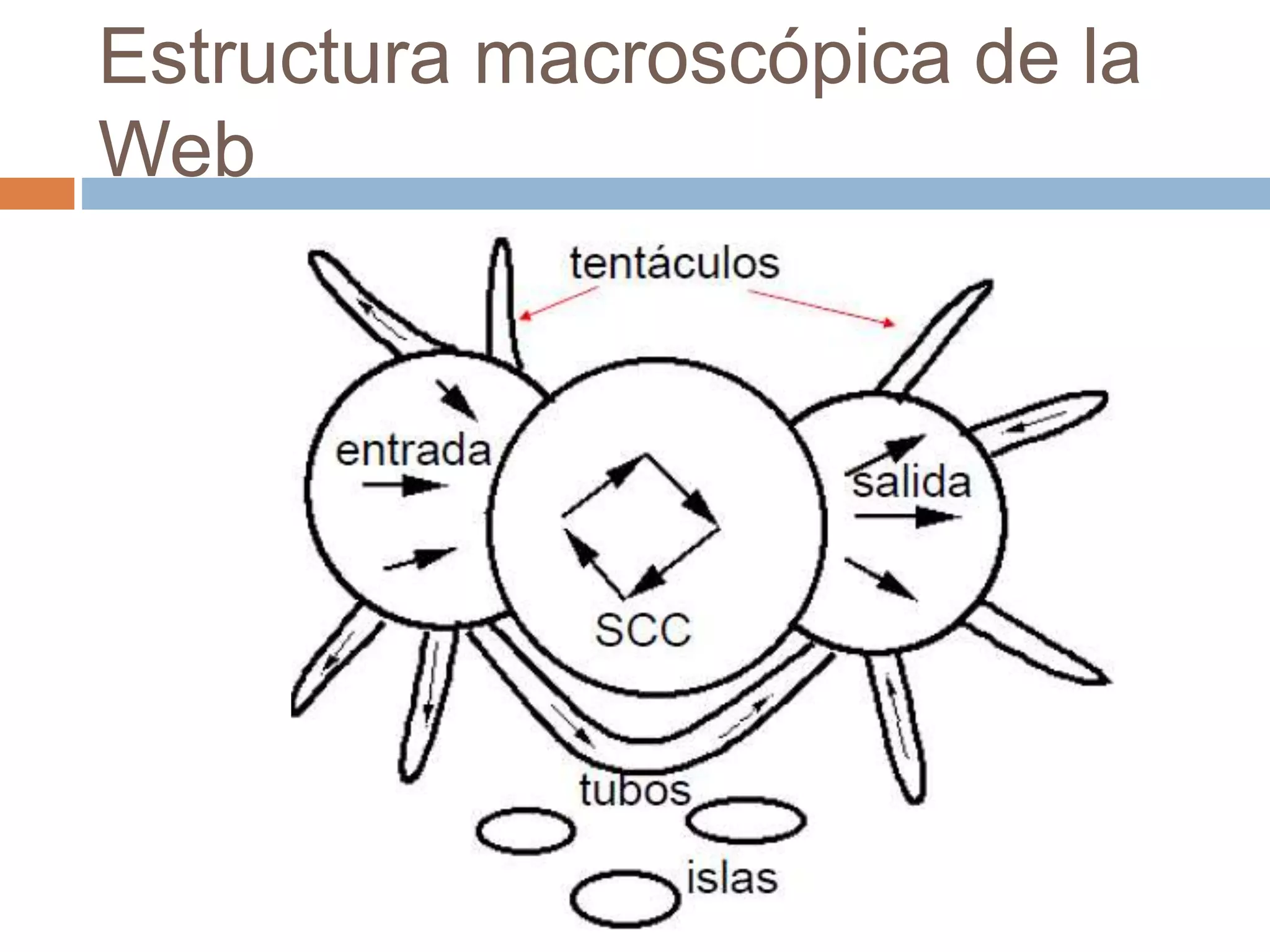
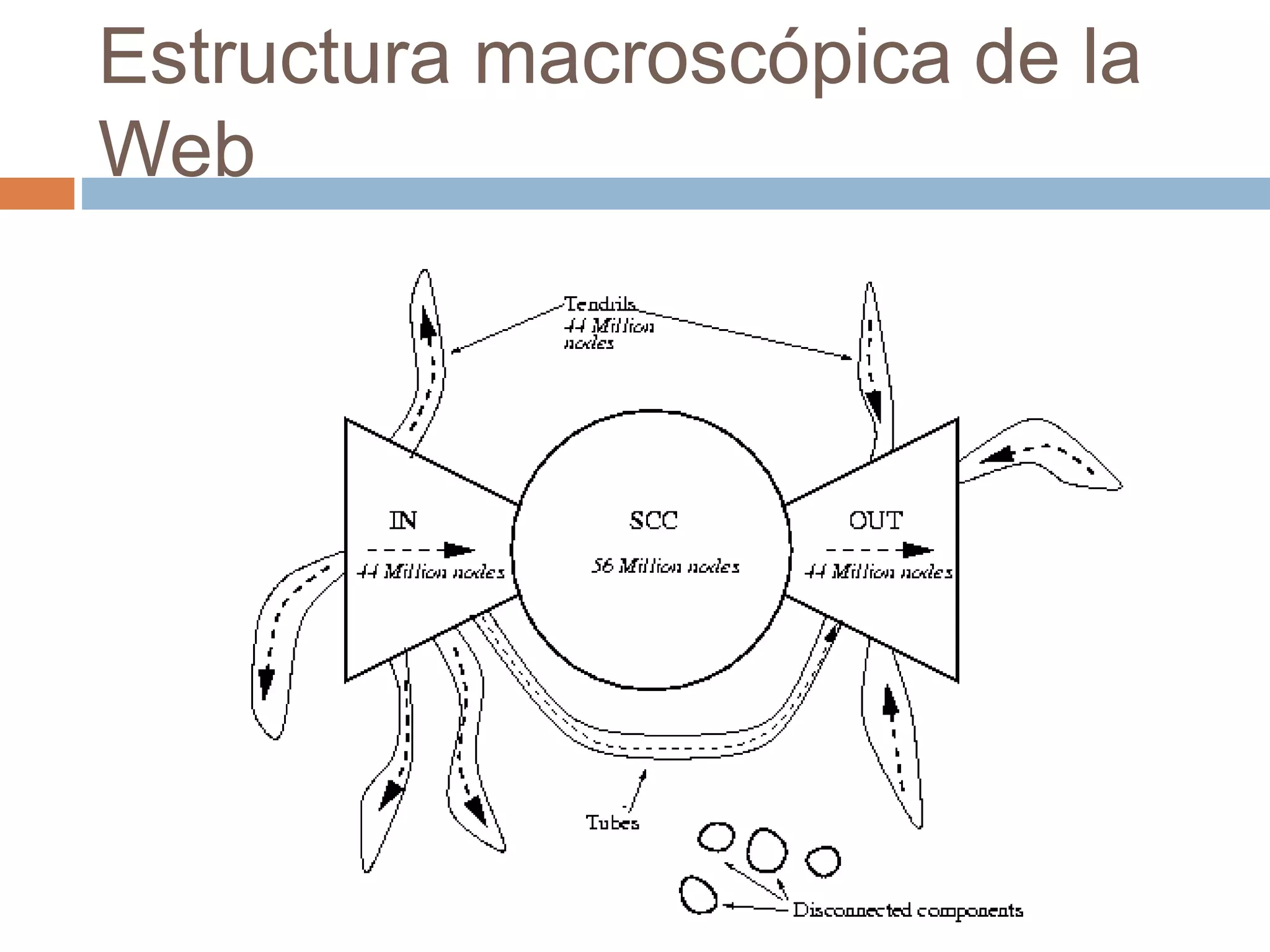
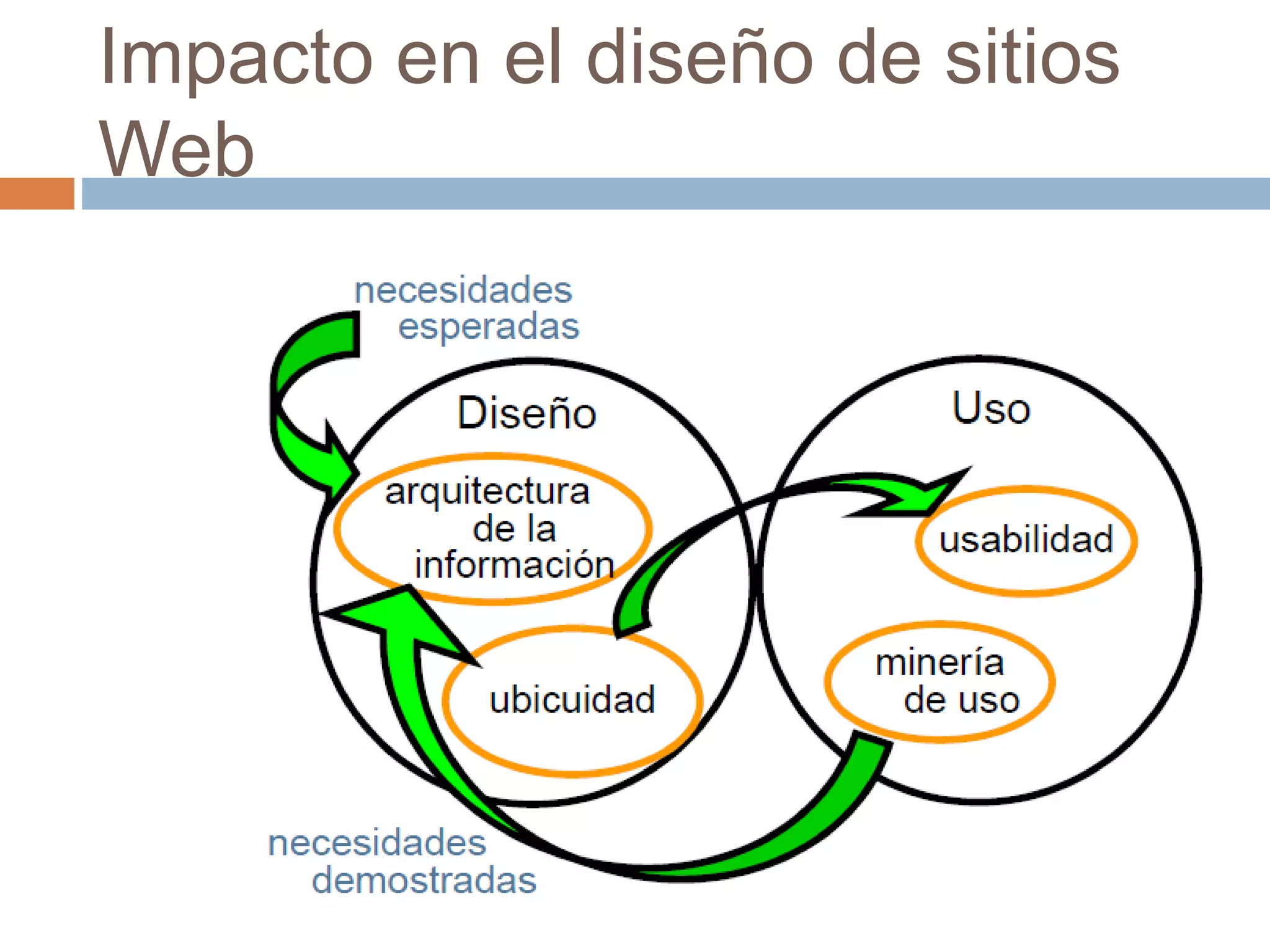

Este documento trata sobre la historia del hipertexto y la web. Explica que el concepto de Memex de Vannevar Bush en 1945 influyó en el desarrollo de sistemas hipertexto y bases de conocimiento personal. Luego describe sistemas pioneros como Xanadu de Ted Nelson y Hypercard de Apple, y detalla los orígenes y crecimiento exponencial de la World Wide Web desde su creación por Tim Berners-Lee en el CERN en 1990. Finalmente, analiza el uso actual de la web, su estructura a gran escala y el impacto del aná




























































