Descargar para leer sin conexión



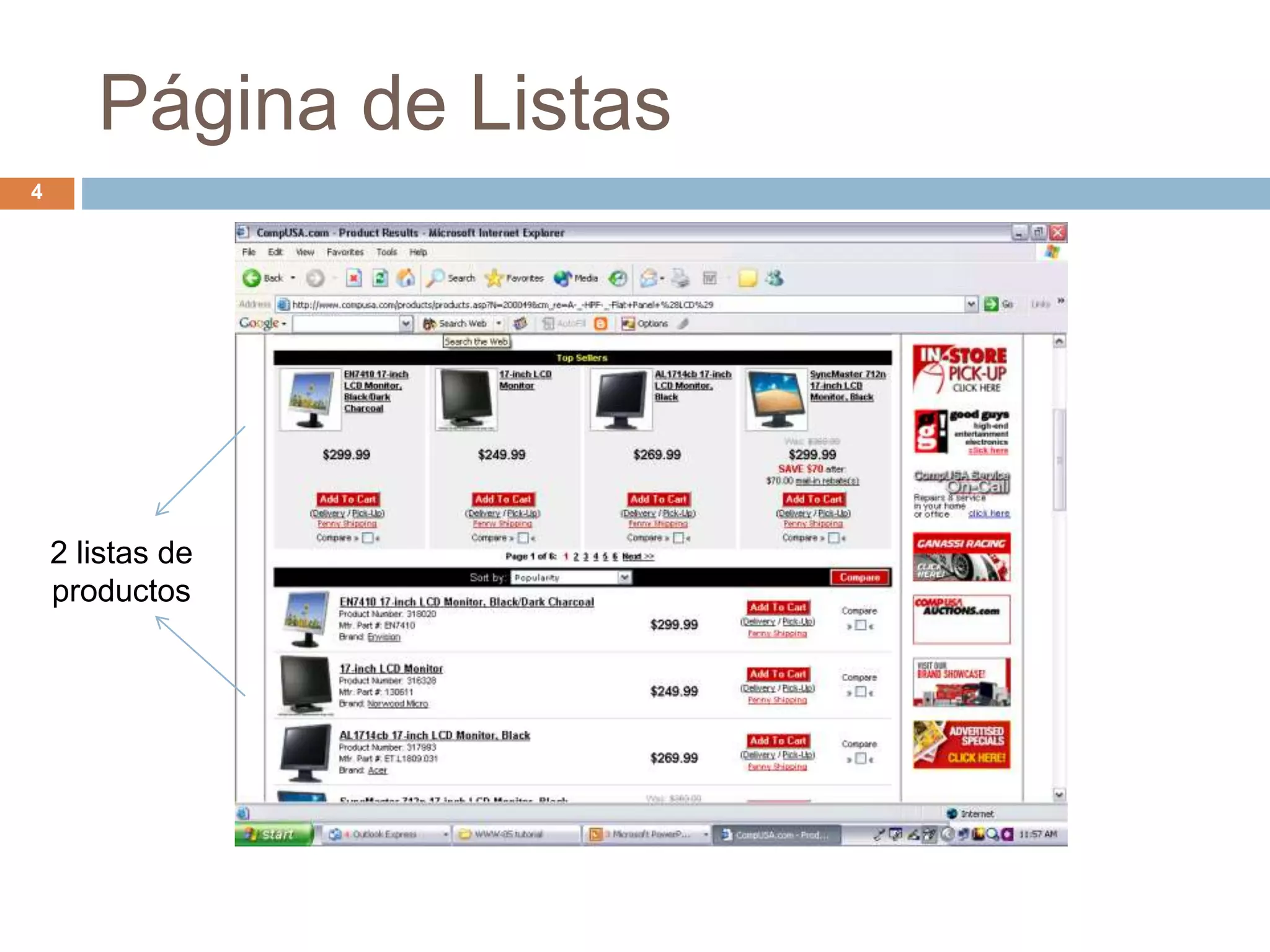
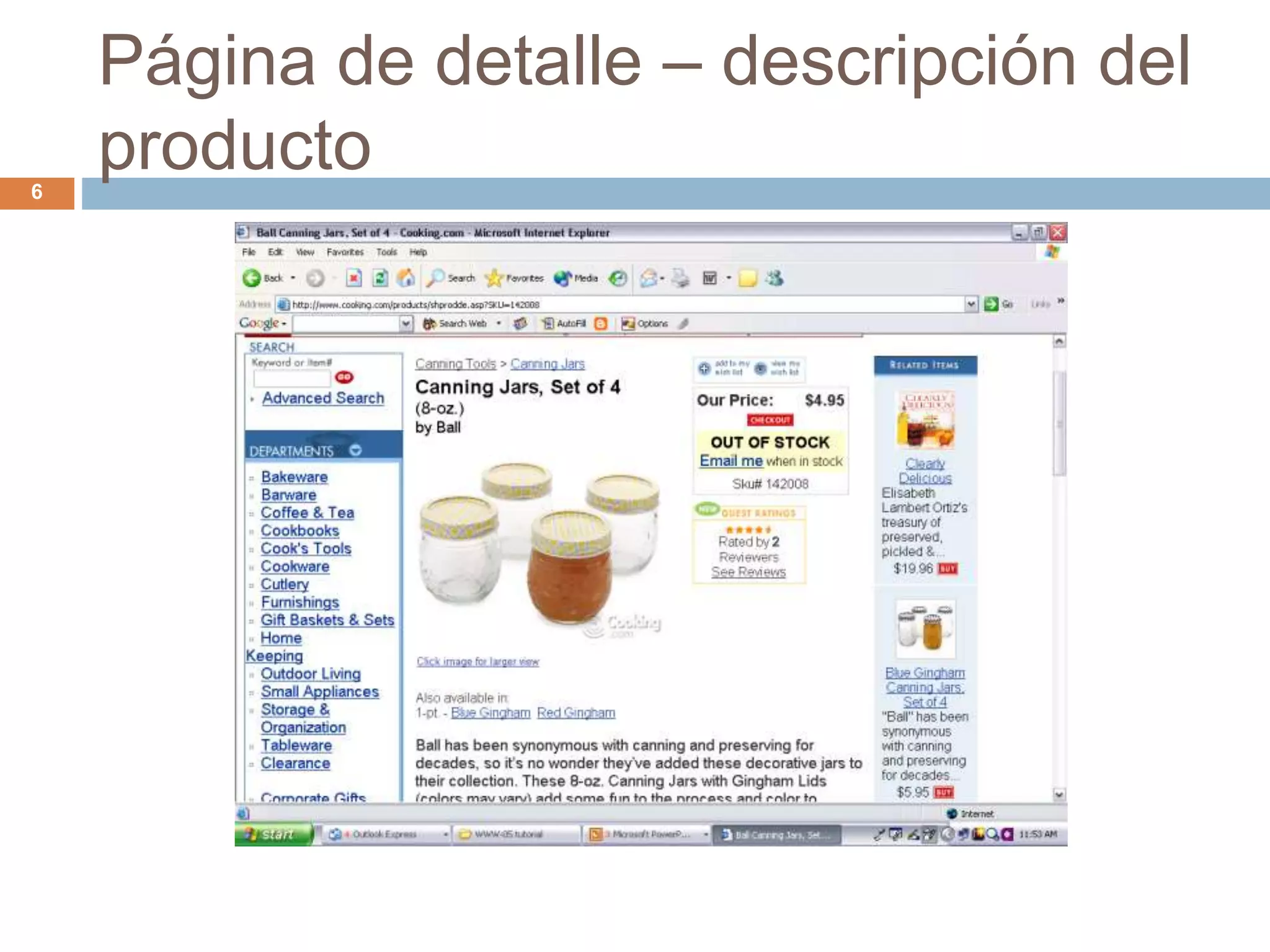


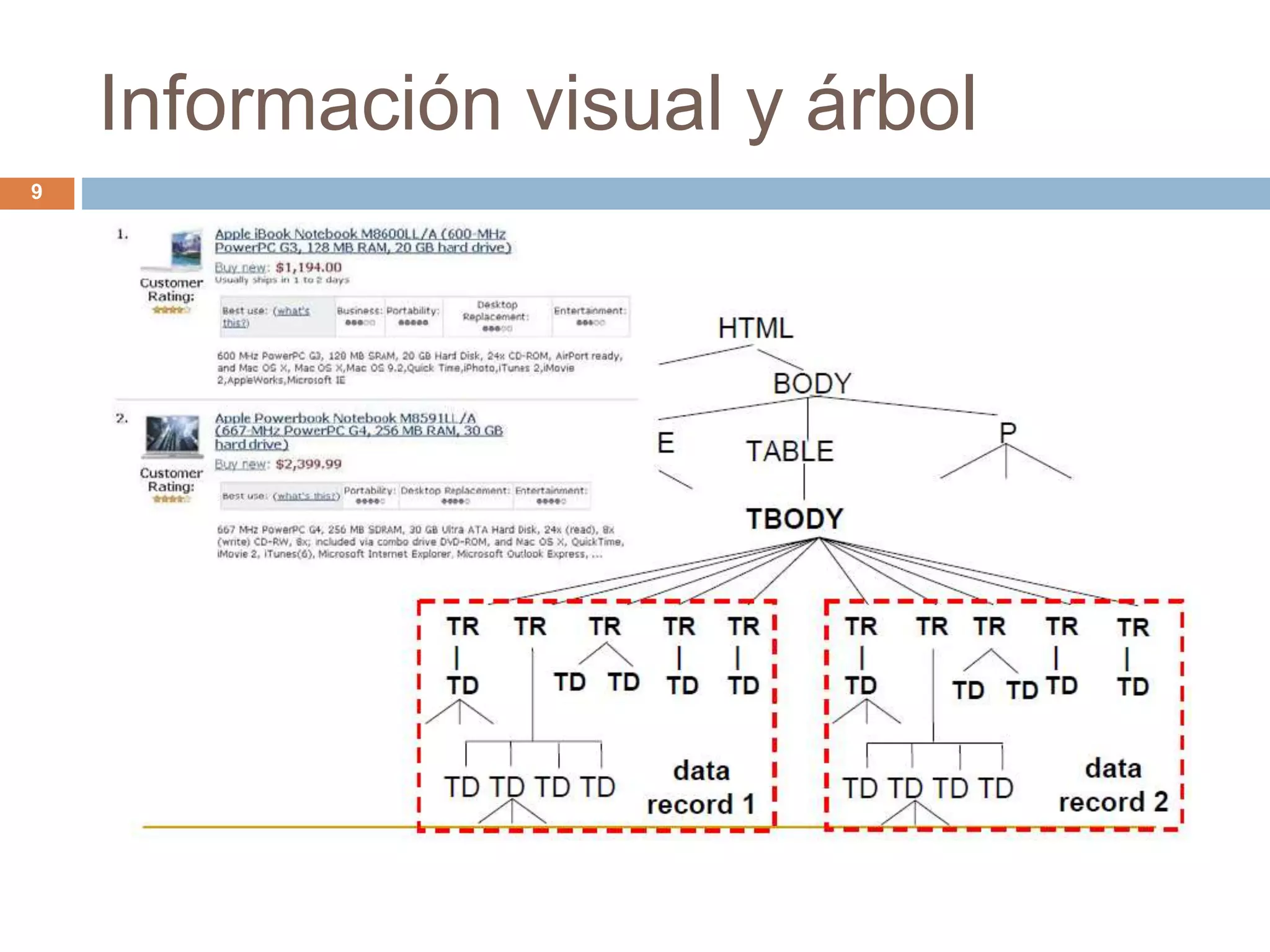





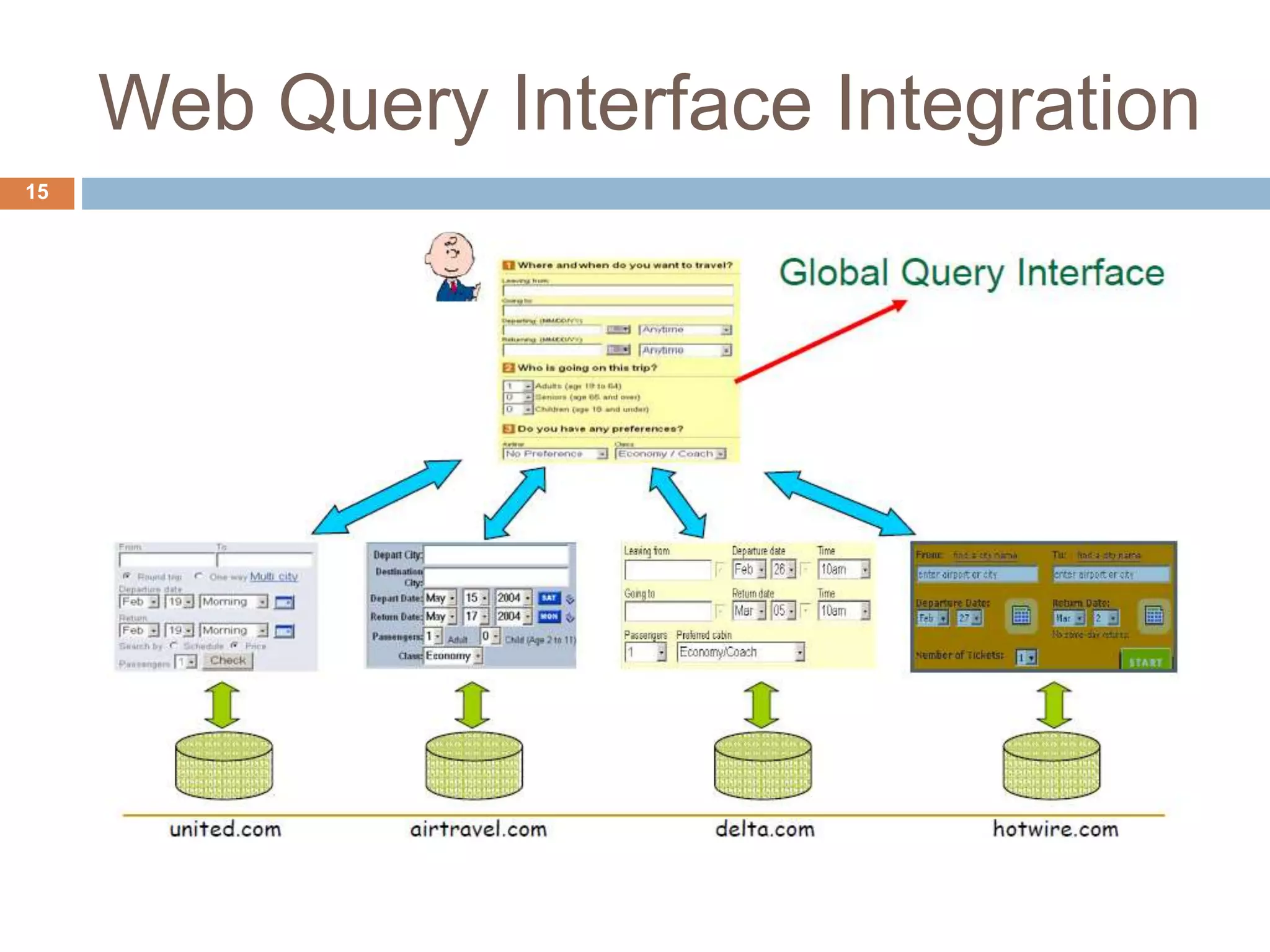
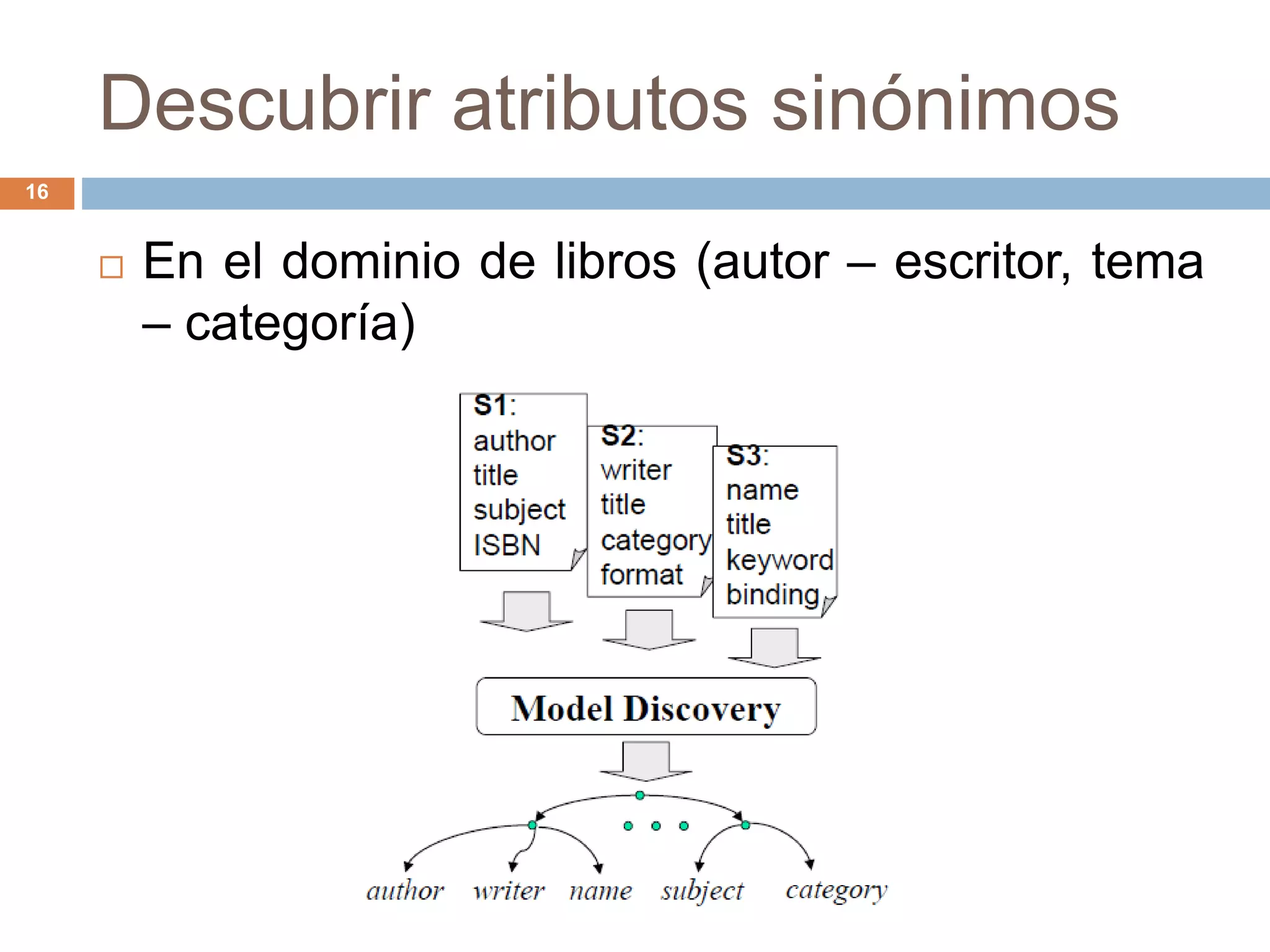

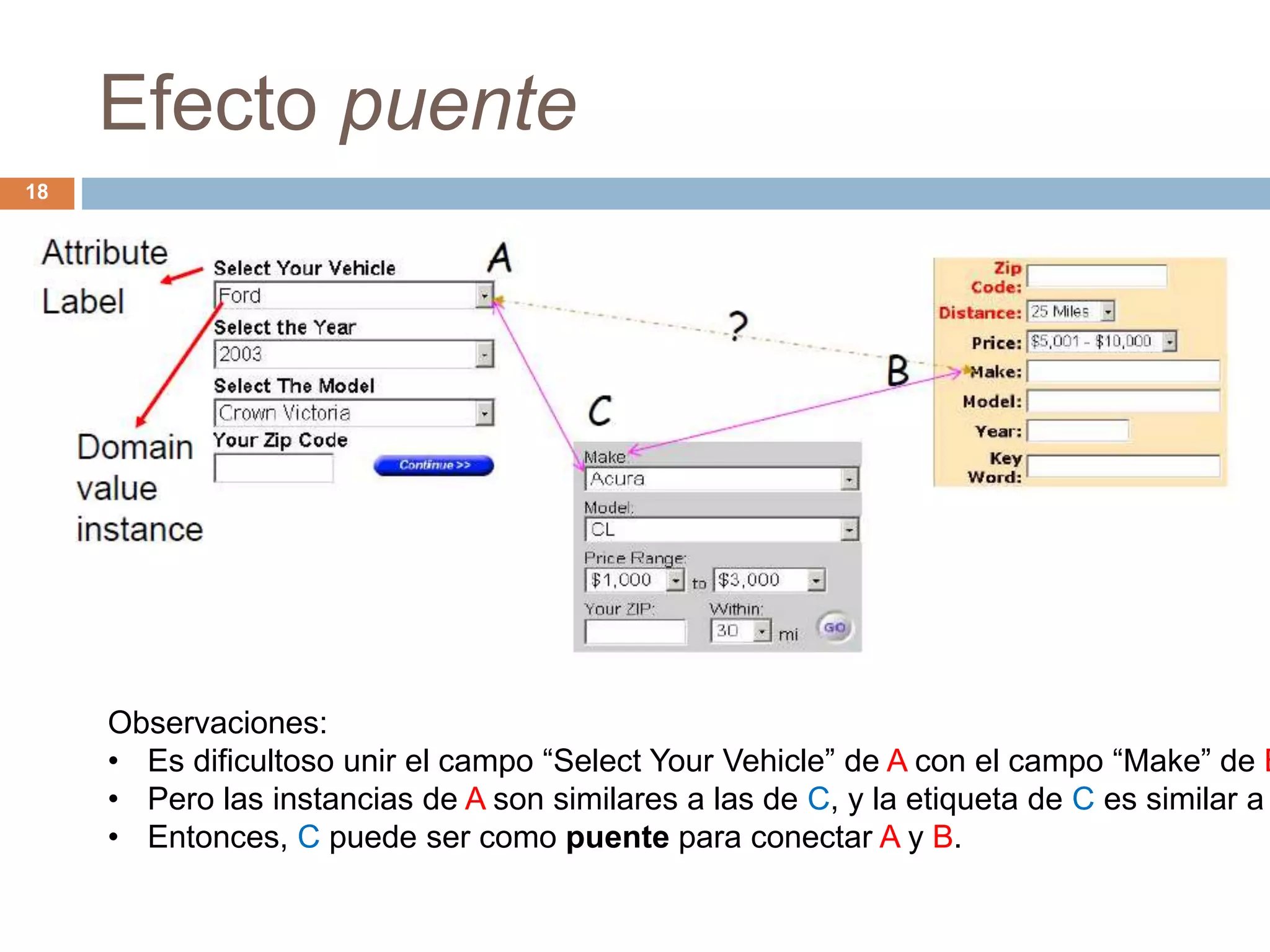



Este documento describe técnicas para extraer datos estructurados de la web. Explica que existen dos tipos de páginas con datos estructurados: páginas de listas y páginas de detalle. Luego describe dos enfoques para la extracción de datos: wrapper inductivo (aprendizaje supervisado) y extracción automática (aprendizaje no supervisado). Finalmente, discute técnicas como la integración de datos extraídos de diferentes sitios web.



































































