
Recomendados
Más contenido relacionado
La actualidad más candente
La actualidad más candente (19)
Similar a Regresión Logística clasifica datos en categorías
Similar a Regresión Logística clasifica datos en categorías (20)
Último
Último (20)
Regresión Logística clasifica datos en categorías
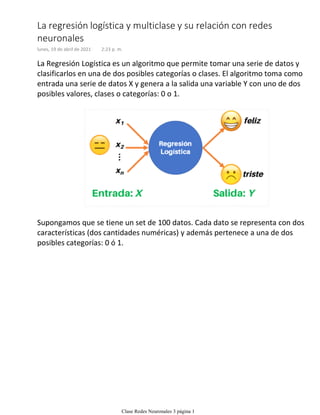
- 1. La Regresión Logística es un algoritmo que permite tomar una serie de datos y clasificarlos en una de dos posibles categorías o clases. El algoritmo toma como entrada una serie de datos X y genera a la salida una variable Y con uno de dos posibles valores, clases o categorías: 0 o 1. Supongamos que se tiene un set de 100 datos. Cada dato se representa con dos características (dos cantidades numéricas) y además pertenece a una de dos posibles categorías: 0 ó 1. La regresión logística y multiclase y su relación con redes neuronales lunes, 19 de abril de 2021 2:23 p. m. Clase Redes Neuronales 3 página 1
- 2. El objetivo de la Regresión Logística es clasificar de forma automática estos datos en las dos categorías existentes. Esto equivale a encontrar una frontera que permita separar los datos en dos agrupaciones diferentes, como se muestra a continuación: Para obtener la frontera de decisión el problema se puede modelar como una red Clase Redes Neuronales 3 página 2
- 3. Para obtener la frontera de decisión el problema se puede modelar como una red neuronal que lleva a cabo los siguientes pasos: Transformación de los datos de entrada • Aplicación de una función de activación • Transformación de los datos de entrada. Es aquí donde el problema se modela como una red neuronal, donde una neurona recibe los datos de entrada y los transforma primero en un número Z de salida. Como en este caso, tenemos 2 datos de entrada (X1,X2); cada dato tendrá su peso (w1, w2); y se realiza la combinación lineal, y luego se le suma la constante "b" al resultado. En el ejemplo, como tenemos 100 datos, entonces, Esos 100 datos son los "datos de entrenamiento", donde cada dato tiene una etiqueta (1 o 0) (Aprendizaje supervisado). El valor de Z es un número natural. El paso siguiente es hallar la "probabilidad" de que ese número corresponda a la etiqueta 1 o 0. Para hallar esa probabilidad se debe evaluar en Z una función llamada "Función de Activación", la cual dará un número entre 0 y 1. Si el resultado es menor o igual que 0.5; la etiqueta se colocará como CERO, y si el resultado es mayor a 0.5, la etiqueta se colocará como 1. Clase Redes Neuronales 3 página 3
- 4. La función de activación común usada en una neurona es la "Función Sigmoidal", cuya expresión y gráfica son: Es así como finalmente se obtiene de la neurona, un dato que es 1 o 0, de acuerdo al dato de la entrada. Formalmente entonces se puede definir una neurona, llamada "Perceptron", como una unidad algorítmica que toma un vector de entrada y genera un vector de salida llevando primero una acción de transformación de los datos, multplicándolos por unos pesos y luego sumando una constate y luego aplicando una función de activación. Clase Redes Neuronales 3 página 4
- 5. Los pesos y la constante se hallan por un proceso de entrenamiento que sigue normalmente los siguientes pasos: Definición de la función de error. • Inicialización aleatoria de los parámetros del modelo. • Definición de la tasa de aprendizaje y el número de iteraciones. • Actualización de los parámetros del modelo usando el algoritmo del Gradiente Descendente. • En cuanto a la función de error, en este caso el error se halla con valores binarios, y si se usara una función de error ECM (Error cuadrático medio), con el error en función de "w", como lo vimos la clase pasada, si se hace eso con este tipo de datos binarios, dicha función daría con mínimos locales, como se muestra en la figura: Clase Redes Neuronales 3 página 5
- 6. Por lo tanto, es posible que el algoritmo de gradiente descendiente no calcule el valor mínimo del error en forma adecuada. Por lo tanto, en las redes neuronales de clasificación, como es el caso de la regresión logística, se usa mejor la siguiente función de error llamada "Entropía Cruzada": Esta función es convexa y garantiza un único mínimo, lo cual a su vez, garantiza la efectividad del algoritmo de gradiente descendiente. Una vez entrenada la red, se dan los valores y de entrenamiento. Con estos valores se puede construir la frontera de decision mostrada en la figura de arriba. Pero esta frontera de decisión es "lineal", y por lo tanto solo clasificará bien los datos, si estos se pueden separar por una línea. En el caso que la distribución de los datos no se adapte a que sean separados por una línea, es necesario un modelo de red neuronal diferente, que se adapte a una frontera de decisión no lineal. TALLER 1 Clase Redes Neuronales 3 página 6
- 7. Los datos de entrenamiento de la neurona del ejemplo anterior son y 1. Escoja 3 puntos y usando la neurona entrenada con estos puntos como entrada, determine cada punto en donde queda clasificado (1 o 0). Anote el paso a paso para hallar la clasificación en el taller. (Paso 1, transformación; Paso 2, función de activación) Invente 10 puntos y un nuevo valor para w1, w2 y b. Ahora, con esos datos, evalue la función de error de entropia cruzada. ¿Cuánto da el error?. Nota: Los valores de Y que deben dar, calcúlelos con y ; y los valores que estan dando hallelos con los nuevos valores de w1, w2 y b que se inventó. 2. En este punto anote en el taller el paso a paso de todos los cálculos. Ahora, implemente en COLAB, el siguiente código de python el cual desarrolla el algoritmo de regresión logística, con datos X1 y X2 de entrada, donde X1 es el número de horas de estudio, y X2 es el número de horas de sueño, de unos estudiantes encuestados; y la salida es el éxito o fracaso al presentar un examen. codigo regresion ... dataset2 Algunos aspectos a tener en cuenta de este código, adicionales a los ejemplos que ya hemos desarrollado en COLAB, son: El dato de entrada contiene dos dimensiones ( y ), mientras que el dato de salida tendrá una dimensión (“0” ó “1”). Además, es necesario el uso de np.random.seed para garantizar la reproducibilidad de los resultados en diferentes computadores. • Clase Redes Neuronales 3 página 7
- 8. diferentes computadores. En la última línea de código hemos definido una función de activación sigmoidal (activation = 'sigmoid') que corresponde precisamente a la función usada en la Regresión Logística. • Para el optimizador hemos definido una tasa de aprendizaje (lr) igual a 0.2. Adicionalmente, además de la entropía cruzada (loss='binary_crossentropy') usaremos la precisión (metrics=['accuracy']) para medir el desempeño del modelo. Esta precisión es simplemente la cantidad de datos clasificador erróneamente, dividida entre la cantidad total de datos. • Al imprimir la información sobre el modelo (usando modelo.summary()), podemos observar que el modelo tiene tres parámetros entrenables (Trainable params: 3). Estos parámetros corresponden a los dos coeficientes w y al parámetro b. • Al ejecutar la anterior línea de código observamos que la precisión se incrementa progresivamente, iniciando con un valor cercano al 55% (acc = 0.55) en la iteración 1, hasta un valor del 89% (acc = 0.89) en la última iteración. • De los 100 datos, 11 fueron clasificados incorrectamente y 89 correctamente, lo que equivale a una precisión del 89%, que fue el valor obtenido en la última iteración del entrenamiento. Incluso si se incrementa el número de iteraciones, la precisión no sobrepasará este 89%. Esto se debe a la forma como están distribuidos los datos, y a la limitación inherente de la Regresión Logística, que no permite obtener una frontera de decisión no lineal (la cual mejoraría la precisión en la clasificación). • Para hacer la predicción de un dato, puede usar la línea: • Z = modelo.predict_classes(np.c_[X1,X2]) print(Z) Donde X1 y X2 es el dato que usted busca hallar la predicción. TALLER 2 Ejecute el código en COLAB. En la ejecución coloque su nombre al final de la ejecución programa para el informe. 1. Luego de ejecutar el programa, realice una predicción de cómo le irá en el parcial 2 de la materia, colocando las horas que piensa estudiar y las horas de sueño. 2. REGRESIÓN MULTICLASE Clase Redes Neuronales 3 página 8
- 9. REGRESIÓN MULTICLASE Permite realizar la clasificación de datos cuando existen tres o más categorías. Por ejemplo, supongamos que se tienen los siguientes datos, donde cada uno está clasificado en una de tres categorías. El objetivo de la Regresión Multiclase es clasificar los datos en estas tres categorías, encontrando de forma automática las fronteras de decisión que establecen los límites entre una y otra. Estas fronteras de decisión se muestran como líneas rectas de color azul en la siguiente figura: Clase Redes Neuronales 3 página 9
- 10. Para obtener las fronteras de decisión el problema se puede modelar como una red neuronal que lleva a cabo tres pasos: Transformación de los datos de entrada • Aplicación de una función de activación • Clasificación en una de las tres categorías existentes. • Note que como hay 3 posibles categorizaciones se usarán 3 neuronas, que luego de transformar los datos, ejecutar la función de activación y hallar las Clase Redes Neuronales 3 página 10
- 11. de transformar los datos, ejecutar la función de activación y hallar las probabilidades, dará en la salida un vector de un 1 y 2 ceros; donde la posición de del 1 indicará la categoría a la que pertenece. En este caso, la función de activación tiene en cuenta 3 entradas, se llama softmax, y es la siguiente: Esta función permite normalizar las tres probabilidades, garantizando que la suma de las mismas sea igual a 1.0. Posteriormente, para realizar la clasificación se determina cuál de las tres probabilidades calculadas tiene el valor más alto, que corresponderá a la clase asignada. TALLER 3 Suponga que la red neuronal ya entrenada dio los siguientes resultados para cada perceptrón: Perceptrón 1: y Perceptrón 2: y Perceptrón 3: y Compruebe que si la entrada es X=(1.839, 0.557) la red clasifica ese dato en la categoría 2. Debe hacer en el informe el paso a paso de esta comprobación. 1. Repita el punto 1 pero con otro valor de X que quede clasificado en la categoría 1, y otro que quede clasificado en la categoría 3. 2. Clase Redes Neuronales 3 página 11