Descargado 140 veces


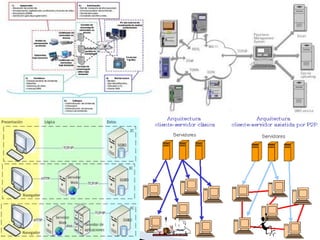

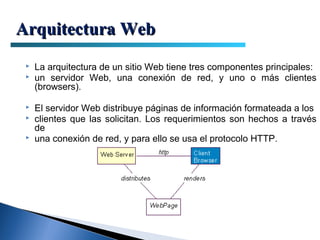
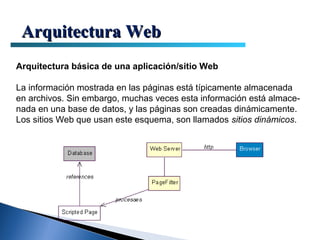



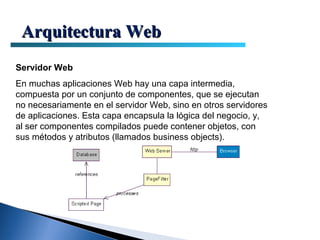
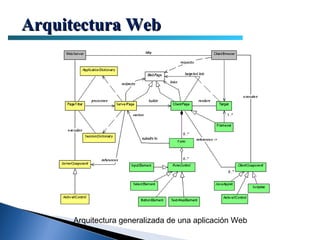

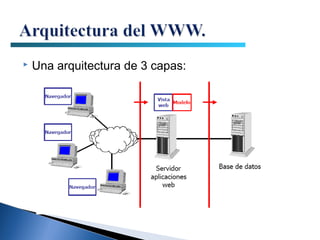
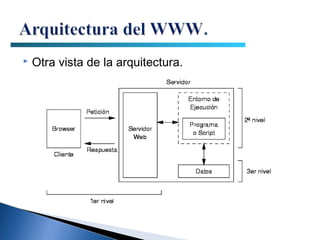






El documento proporciona información sobre la arquitectura web. Describe que la arquitectura web típica tiene tres componentes principales: un servidor web, una conexión de red y uno o más clientes (navegadores). El servidor web distribuye páginas a los clientes a través de una conexión de red usando el protocolo HTTP. Las páginas pueden almacenarse en archivos o crearse dinámicamente desde una base de datos.























































































