Descargado 708 veces



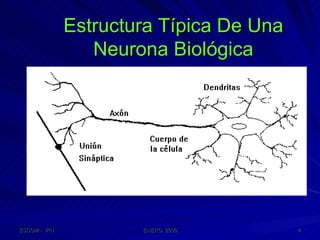








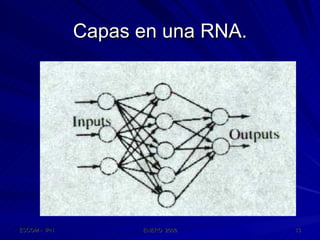


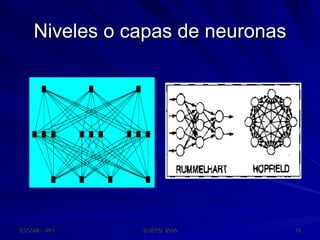













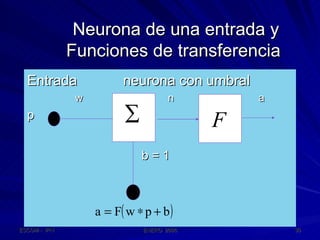
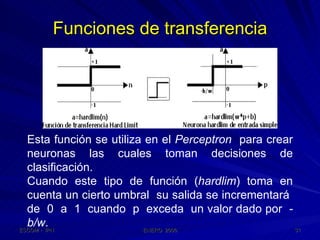
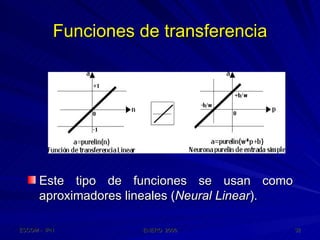

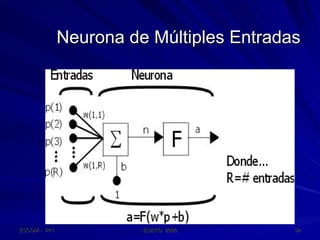
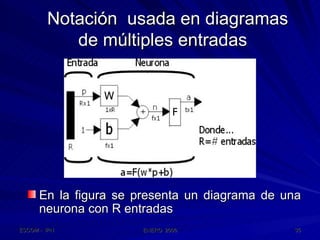

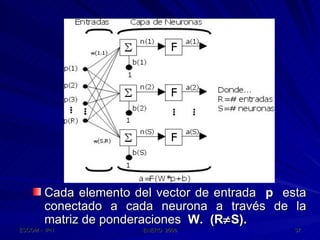

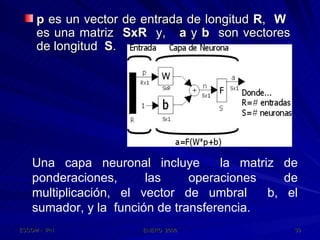

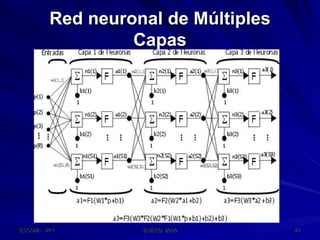
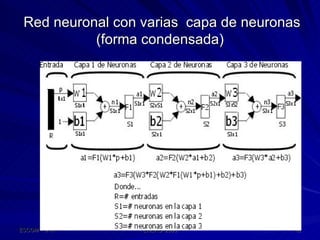




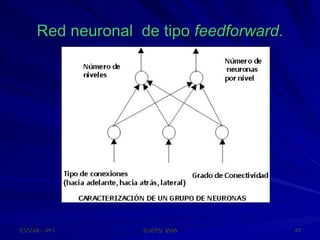
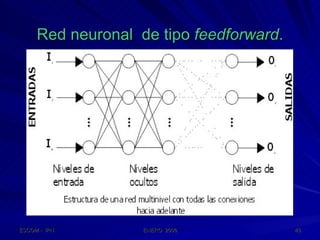
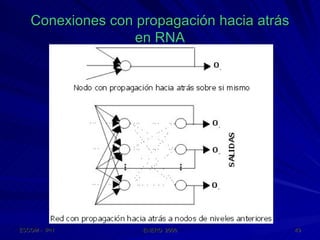
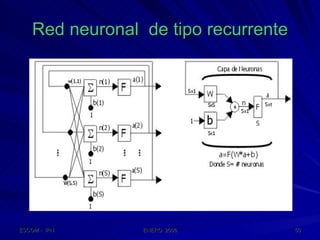























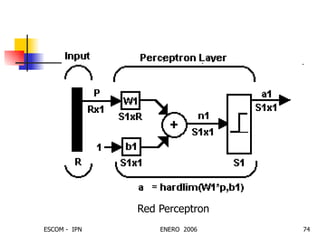
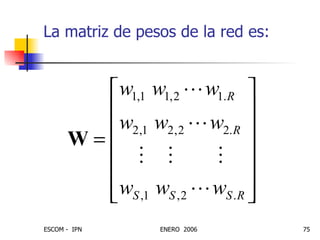
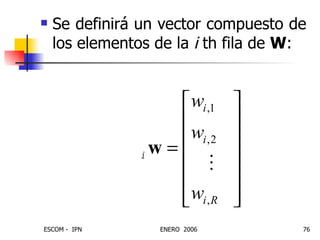
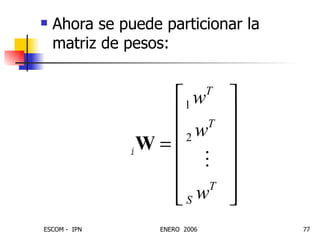










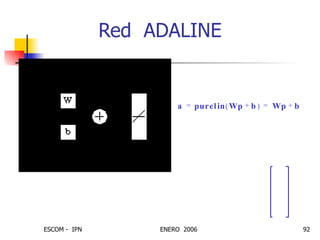




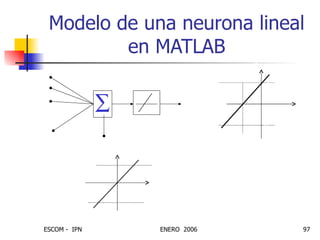




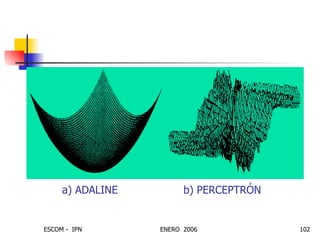






Este documento describe las redes neuronales artificiales, incluyendo su estructura, funcionamiento y mecanismos de aprendizaje. Explica que las RNA imitan a las redes neuronales biológicas mediante el uso de capas y que aprenden ajustando los pesos sinápticos a medida que procesan conjuntos de datos.






![5.2 Redes neuronales (RN) [presentación].](https://cdn.slidesharecdn.com/ss_thumbnails/5-150525095017-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)





























































































