Descargado 16 veces


























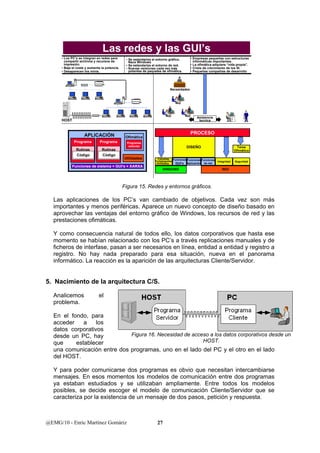



















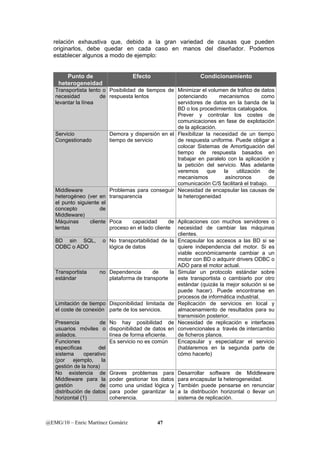







































































































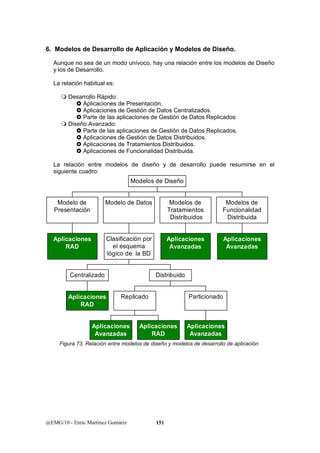

















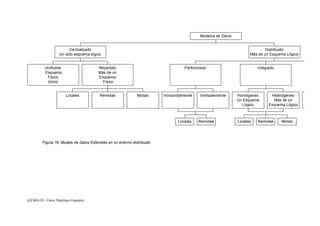




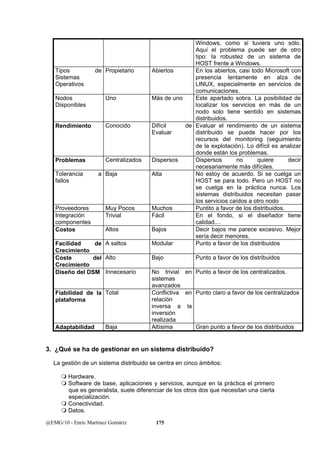
































































Este documento presenta una introducción a los sistemas distribuidos. Explica que un sistema distribuido es un sistema de información donde las funciones se distribuyen en diferentes áreas de trabajo que trabajan de forma coordinada para lograr los objetivos de la organización. También describe los diferentes componentes de un sistema distribuido como la plataforma de procesamiento, la conectividad, el almacenamiento de datos, el software y la gestión del sistema. El objetivo final es diseñar aplicaciones que utilizan servicios para integrarse de forma transparente en este entorno distribuido.























































