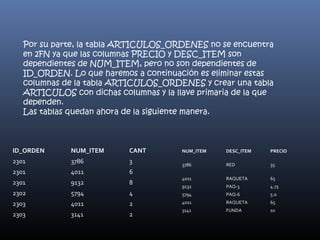
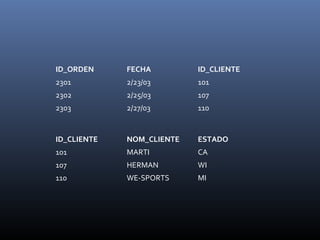
El documento describe los fundamentos de la normalización de bases de datos. La normalización es el proceso de organizar los datos en tablas y establecer relaciones entre ellas para eliminar redundancias y dependencias inconsistentes. Esto se logra mediante tres formas normales: eliminar grupos repetidos en tablas separadas, eliminar columnas no dependientes de la clave primaria en otras tablas, y eliminar columnas dependientes de otras no clave en tablas separadas.