Descargado 10 veces
















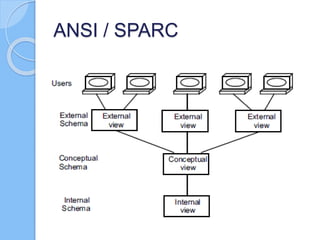
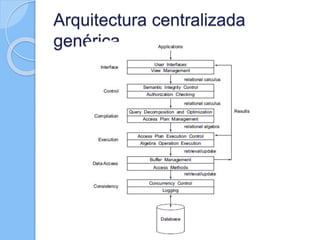

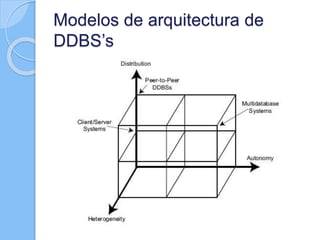






Este documento describe los conceptos básicos de las bases de datos distribuidas, incluyendo los retos introducidos por la distribución como la replicación y la sincronización de transacciones entre múltiples sitios. También discute cuestiones clave de diseño como la fragmentación y distribución de datos, y aborda temas como el procesamiento de consultas distribuidas, el control de concurrencia y la replicación. Finalmente, presenta tres modelos de arquitectura basados en el grado de autonomía, la distribución de datos y la heterogeneidad.






















































































