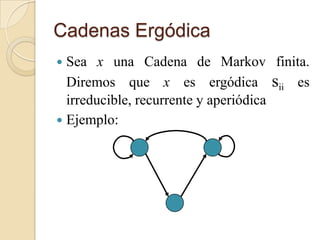
Este documento presenta conceptos básicos sobre cadenas de Markov de estados finitos. Explica que una cadena de Markov es un proceso estocástico donde el estado futuro depende solo del estado presente. También describe la matriz de transición de probabilidades y cómo se puede usar para calcular la probabilidad de transición entre estados a lo largo del tiempo. Además, introduce la teoría de Perron-Frobenius sobre eigenvalores y eigenvectores de matrices estocásticas asociadas a cadenas de Markov.














![ La matriz [P] de transición de
probabilidades de las cadenas de Markov
es llamada una matriz estocástica.
Una matriz estocástica es una matriz
cuadrada de términos no negativos en la
cual los elementos en cada línea suman 1.](https://image.slidesharecdn.com/presentacionestadofinitodecadenasdemarkov-111216070929-phpapp02/85/Estado-Finito-de-Cadenas-de-Markov-14-320.jpg)
![ Debemos considerar n pasos de probabilidades
de transición Pijn en términos de [P].
La probabilidad de ir del estado i al estado j en
dos pasos es la suma sobre h de todos los
posibles tránsitos de dos pasos, de i a h y de h a
j. Esto utilizando la condición de Markov.
(Pr{Xn=j | Xn−1=i,Xn−2=k, . . . ,X0=m} = Pr{Xn=j | Xn−1=i})](https://image.slidesharecdn.com/presentacionestadofinitodecadenasdemarkov-111216070929-phpapp02/85/Estado-Finito-de-Cadenas-de-Markov-15-320.jpg)
![M
Pij2 Pih Phj
h 1
Puede verse que es solo el termino i j del
producto de la matriz [P] consigo misma.
Esto denota[P][P] como P2, esto significa
P 2 es el (i , j) elemento de la
que ij
matriz[P]2.
Similarmente, Pijn es el elemento i j de la n
potencia de la matriz [P].](https://image.slidesharecdn.com/presentacionestadofinitodecadenasdemarkov-111216070929-phpapp02/85/Estado-Finito-de-Cadenas-de-Markov-16-320.jpg)
![ Pues como [ P]m n [ P]m [ P]n entonces:
M
Pijm n Pih Phj
m n
h 1
Esta ecuación es conocida como La Ecuación
Chapman-Kolmogorov.
n
**Un método muy eficiente de computar [P]n así como Pij
para un n muy grande, multiplicando [P]2 por [P]2, [P]4 por
[P]4, hasta entonces multiplicar estas potencias binarias
entre si hasta donde sea necesario.](https://image.slidesharecdn.com/presentacionestadofinitodecadenasdemarkov-111216070929-phpapp02/85/Estado-Finito-de-Cadenas-de-Markov-17-320.jpg)
![ La matriz [P]n es muy importante por varias
razones:
◦ Los elementos i , j de la matriz lo cual es P n que
ij
es la probabilidad de estar en un estado j a tiempo
n dando un estado i a tiempo 0.
◦ Pues si la memoria del pasado muere con un
incremento en n, entonces podemos esperar la
dependencia de i y n desaparecer en P n .
ij
◦ Esto quiere decir que [P]n debe converger a un
limite de n → 1, y , segundo, que cada línea de
[P]n debe tender al mismo grupo de
probabilidades.
◦ Si esta convergencia se gesta (aunque luego
determinemos las razones bajo las que se da), [P]n
y [P]n+1 serán iguales cuando el limite → .](https://image.slidesharecdn.com/presentacionestadofinitodecadenasdemarkov-111216070929-phpapp02/85/Estado-Finito-de-Cadenas-de-Markov-18-320.jpg)
![ Esto quiere decir entonces que :
Lim[ P]n ( Lim[ P]n [ P])](https://image.slidesharecdn.com/presentacionestadofinitodecadenasdemarkov-111216070929-phpapp02/85/Estado-Finito-de-Cadenas-de-Markov-19-320.jpg)

![Definición
El vector de línea es el eigenvector
izquierdo de [P] del eigenvalor si ≠ 0 y
[P]= .
El vector columna v es el eigenvector
derecho del eigenvalor si v ≠ 0 y [P]v = v.](https://image.slidesharecdn.com/presentacionestadofinitodecadenasdemarkov-111216070929-phpapp02/85/Estado-Finito-de-Cadenas-de-Markov-21-320.jpg)

![ Estas ecuaciones no tienen solución en cero si la
matriz [P − I], donde [I] es la matriz
identidad, (debe haber un v no igual a 0 para el cual
[P − I] v = 0). Entonces debe ser tal que el
determinante de [P − I], conocido como
(P11 − )(P22 − ) − P12P21, es igual a 0.
Resolver estas ecuaciones cuadráticas en
, encontraremos que tiene dos soluciones, 1 = 1
y 2 = 1 − P12 − P21.
Asuma inicialmente que P12 y P21 son ambos 0.
Entonces la solución para el eigenvector izquierdo y
derecho, π(1) y v(1), de 1 y π(2) y v(2) de 2, son
dadas por:](https://image.slidesharecdn.com/presentacionestadofinitodecadenasdemarkov-111216070929-phpapp02/85/Estado-Finito-de-Cadenas-de-Markov-23-320.jpg)
![ Estas soluciones poseen un factor de normalización
arbitrario.
1 0
Dejemos que []
0 2
y que [U] sea la matriz con
columnas v(1) y v(2).
Entonces las dos ecuaciones derechas de eigenvectores
en
Pueden ser combinadas de forma compacta como
[P][U] = [U][Λ].
Surge entonces (dado como se ha normalizado el
eigenvector) que el inverso de [U] es exactamente la
matriz cuyas líneas son el eigenvector izquierdo de [P]
Lo que muestra que todo eigenvector derecho de un
eigenvalor debe ser ortogonal a cualquier eigenvalor
izquierdo.
Vemos entonces que [P]=[U][Λ][U]−1y consecuentemente
[P]n = [U][Λ]n[U]−1.](https://image.slidesharecdn.com/presentacionestadofinitodecadenasdemarkov-111216070929-phpapp02/85/Estado-Finito-de-Cadenas-de-Markov-24-320.jpg)

![ Si recordamos que 2 = 1 − P12 −
P21, veremos que | 2| ≤ 1. Si P12 = P21 =
0, entonces 2 = 1 tal que [P] y [P]n son
simplemente matrices idénticas. Si P12 =
P21 = 1, entonces 2 = −1 tal que [P]n
alterna entre la matriz identidad para n
eventos y [P] para n impar.
En todos los demás casos | 2| < 1 y [P]n
se acerca a la matriz cuyas líneas son
iguales a π.](https://image.slidesharecdn.com/presentacionestadofinitodecadenasdemarkov-111216070929-phpapp02/85/Estado-Finito-de-Cadenas-de-Markov-26-320.jpg)
![ Parte de este caso especifico generaliza a un numero
arbitrario de estados finitos.
En particular =1 es siempre un eigenvalor y el vector
e cuyos componentes son igual a 1 es siempre un
eigenvector derecho de =1 (esto se debe de que cada
línea de una matriz estocástica suma igual a 1).
Desafortunadamente, no todas las matrices
estocásticas pueden ser representadas en la forma de
[P]= [U][Λ][U−1] (ya que M la necesidad de los
independientes eigenvectores derechos no existe.
En general, l matriz diagonal de eigenvalores en
[P] = [U][Λ][U−1] debe entonces esta ser remplazada
por el la Forma Jordan, la cual no necesariamente
nos producirá resultados deseables.](https://image.slidesharecdn.com/presentacionestadofinitodecadenasdemarkov-111216070929-phpapp02/85/Estado-Finito-de-Cadenas-de-Markov-27-320.jpg)

![ Un vector real x (un vector con componentes reales) es definido como
positivo, denotando x > 0.
Si xi > 0 para cada componente i. Una matriz real [A] es
positiva, denotando [A] > 0, si Aij > 0 para cada i , j.
De igual forma, x es no negativo, denotando x ≥ 0, si xi ≥ 0 para todo i.
[A] es no negativa, denotando [A] ≥ 0, si Aij ≥ 0 para todo i, j.
Nota: Es posible tener x ≥ 0 and x ≠ 0 sin tener que x > 0, pues x > 0
quiere decir que al menos un componente de x es positivo y todos son
no negativos.
Si x > y y y < x ambos quieren decir que x −y > 0.
De igual forma si x ≥ y y y ≤ x quiere decir que x −y ≥ 0.
Entonces las desigualdades matriciales correspondientes tienen
significados correspondientes.](https://image.slidesharecdn.com/presentacionestadofinitodecadenasdemarkov-111216070929-phpapp02/85/Estado-Finito-de-Cadenas-de-Markov-29-320.jpg)
![Que muestra el Teorema de Perron-
Fobenius
Muestras:
◦ Una matriz positiva cuadrada [A] siempre
tiene un eigenvalor positivo que excede la
magnitud de todos los demás eigenvalores.
◦ Este tiene un eigenvector derecho v que es
positivo y único dentro una escala de factores.
◦ Establece estos resultados relacionando a
los siguientes y comúnmente usados
problemas de optimización.](https://image.slidesharecdn.com/presentacionestadofinitodecadenasdemarkov-111216070929-phpapp02/85/Estado-Finito-de-Cadenas-de-Markov-30-320.jpg)
![ Para una matriz cuadrada dada [A] > 0, y
para cualquier vector no igual a cero x ≥
0, sea g(x) el mas grande numero real a por
el que ax ≤ [A]x. Sea definida por:
Podemos expresar g(x) explícitamente re-
escribiendo ax ≤ Ax como axi ≤ Aij xj para
toda i. La mas grande a para la que esto es
satisfecho es:
Donde](https://image.slidesharecdn.com/presentacionestadofinitodecadenasdemarkov-111216070929-phpapp02/85/Estado-Finito-de-Cadenas-de-Markov-31-320.jpg)
![ Si [A] > 0, x ≥ 0 y x ≠ 0, lleva a que el
numerador iAij xj es positivo para todo i.
Como gi(x) es positivo para xi > 0 e
infinito para xi = 0, tal que g(x) > 0.](https://image.slidesharecdn.com/presentacionestadofinitodecadenasdemarkov-111216070929-phpapp02/85/Estado-Finito-de-Cadenas-de-Markov-32-320.jpg)
![Teorema Perron-Frobenius
Para Matrices Positivas
Sea [A] > 0 sea una M por M matriz, sea > 0
dada por
y por donde
y dejemos ser un vector x que maximiza
Entonces:
1. v = [A]v y v > 0.
2. Para cualquier otro eigenvalor μ de [A], |μ| < .
3. Si x satisface x = [A]x, entonces x = βv para
algunos (posiblemente complejos) números β.](https://image.slidesharecdn.com/presentacionestadofinitodecadenasdemarkov-111216070929-phpapp02/85/Estado-Finito-de-Cadenas-de-Markov-33-320.jpg)

![ Para algunas matrices estocásticas, una matriz
irreducible es una matriz estocástica, una matriz
recurrente de Cadena de Markov.
Si denotamos el elemento i, j de [A]n por
Anij, entonces vemos como Anij > 0 si existe un
largo de desplazamiento n desde i a j en la grafica.
Si [A] es irreducible, un desplazamiento existe
desde cualquier i a cualquier j (incluyendo j = i)
con largo al menos M, desde que el
desplazamiento necesario visita cada otro nodo al
menos una vez.
Entonces si Anij > 0 para algunos n, 1 ≤ n ≤ M, y
Mn=1 Anij > 0 .](https://image.slidesharecdn.com/presentacionestadofinitodecadenasdemarkov-111216070929-phpapp02/85/Estado-Finito-de-Cadenas-de-Markov-35-320.jpg)
![*La clave para analizar Matrices
Irreducibles es que la Matriz B n 1[ A] es
M n
estrictamente positiva.](https://image.slidesharecdn.com/presentacionestadofinitodecadenasdemarkov-111216070929-phpapp02/85/Estado-Finito-de-Cadenas-de-Markov-36-320.jpg)
![Teorema Perron-Frobenius
Para Matrices Irreducibles
Sea [A] ≥ 0 sea una M por M matriz irreducible y sea lo
supremo en
y en donde
Entonces lo supremo es alcanzado como un máximo en algún
vector v y el par ,v que tiene las siguientes cualidades:
1. v = [A]v y v > 0.
2. Para cualquier otro eigenvalor μ de [A], |μ| ≤ .
3. Si x satisface x = [A]x, entonces x = βv para algunos
(posiblemente complejos) números β.](https://image.slidesharecdn.com/presentacionestadofinitodecadenasdemarkov-111216070929-phpapp02/85/Estado-Finito-de-Cadenas-de-Markov-37-320.jpg)
![Nota!!!!
Este es casi el mismo teorema que mencionamos
anteriormente , la diferencia es que , se espera
que [A] sea irreducible (pero no necesariamente
positiva), y la magnitud la necesidad de los otros
eigenvalores no es estrictamente menos que .
Cuando miramos a matrices recurrentes de un
periodo d, encontraremos que hay d - 1 otros
eigenvalores de magnitud igual a .
Por esta posibilidad de otros eigenvalores con la
misma magnitud que , nos referimos a como el
mas grande del los eigenvalores reales de [A].](https://image.slidesharecdn.com/presentacionestadofinitodecadenasdemarkov-111216070929-phpapp02/85/Estado-Finito-de-Cadenas-de-Markov-38-320.jpg)
![Corolario
El mas grande de los eigenvalores reales
de una matriz irreducible [A] ≥ 0 tiene un
eigenvector izquierdo positivo . es el
único eigenvector de ( dentro de un
factor escala) y que es solo un vector no
negativo no cero u (dentro de un factor
escala) que satisface u ≤ u[A].](https://image.slidesharecdn.com/presentacionestadofinitodecadenasdemarkov-111216070929-phpapp02/85/Estado-Finito-de-Cadenas-de-Markov-39-320.jpg)
![Corolario
Sea el mas grande de los eigenvalores
reales de una matriz irreducible y sea el
eigenvector derecho e izquierdo de ser v
>0 y >0. Entonces, dentro de un factor
escala, v es el único eigenvector derecho
no negativo de [A] (no hay otros
eigenvalores que tengan eigenvectores no
negativos). Similarmente, dentro de un
factor escala, es el único eigenvector
izquierdo no negativo de [A].](https://image.slidesharecdn.com/presentacionestadofinitodecadenasdemarkov-111216070929-phpapp02/85/Estado-Finito-de-Cadenas-de-Markov-40-320.jpg)
![Corolario
Sea [P] una matriz estocástica irreducible
(Una matriz recurrente de cadena de
Markov). Entonces =1 siendo el mas
grande de los eigenvalores de
[P], e = (1, 1, . . . , 1)T es el
eigenvector derecho de =1, único dentro
de un factor escala, y hay una
probabilidad única vector π > 0 que es el
eigenvector izquierdo de =1.](https://image.slidesharecdn.com/presentacionestadofinitodecadenasdemarkov-111216070929-phpapp02/85/Estado-Finito-de-Cadenas-de-Markov-41-320.jpg)
![Corolario
Sea [P] una matriz de transición de una
uni-cadena . Entonces =1 siendo el mas
grande de los eigenvalores de
[P], e = (1, 1, . . . , 1)T es el
eigenvector derecho de =1, único dentro
de un factor escala, y hay una
probabilidad única vector π ≥ 0 que es el
eigenvector izquierdo de =1; i>0 para
cada estado i de recurrencia y i=0 para
cada estado de transición.](https://image.slidesharecdn.com/presentacionestadofinitodecadenasdemarkov-111216070929-phpapp02/85/Estado-Finito-de-Cadenas-de-Markov-42-320.jpg)


![Corolario
El mas grande de los eigenvalores reales
de una matriz irreducible [A] ≥ 0 es
estrictamente una función creciente de
cada componente de [A].](https://image.slidesharecdn.com/presentacionestadofinitodecadenasdemarkov-111216070929-phpapp02/85/Estado-Finito-de-Cadenas-de-Markov-45-320.jpg)
![Corolario
Sea el mas grande de los eigenvalores
de [A] > 0 y sea y v los egenvectores
positivos derecho e izquierdo de
, normalizado tal que v =I. Entonces:](https://image.slidesharecdn.com/presentacionestadofinitodecadenasdemarkov-111216070929-phpapp02/85/Estado-Finito-de-Cadenas-de-Markov-46-320.jpg)
![Teorema
Sea [P] una matriz de transición de un
estado finito ergodico de Cadena de
Markov. Entonces = 1 es el mas grande
de los eigenvalores reales de [P], y > |μ|
para cada otro eigenvalor μ. En adición el
Limn→1[P]n = eπ , donde π > 0 es el único
vector de probabilidad capaz de satisfacer
π[P] = π y e = (1, 1, . . . , 1)T es el único
vector v (dentro de un factor escala) que
satisface [P]v = v.](https://image.slidesharecdn.com/presentacionestadofinitodecadenasdemarkov-111216070929-phpapp02/85/Estado-Finito-de-Cadenas-de-Markov-47-320.jpg)
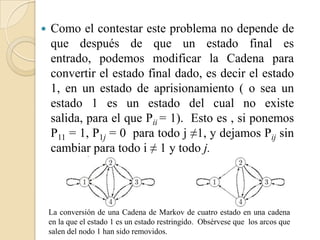
![Teorema
Sea [P] un matriz de transición de una
unicadena ergódica. Entonces = 1 es el
mas grande de los eigenvalores reales de
[P], y >|μ| para cualquier otro eigenvalor
μ.
En adición, el Limm→1[P]m = eπ ,
donde π ≥ 0 es el único vector de
probabilidad que satisface π[P] = π y e =
(1, 1, . . . , 1)T es el único v (dentro de un
factor escala) satisfaciendo [P]v = v.](https://image.slidesharecdn.com/presentacionestadofinitodecadenasdemarkov-111216070929-phpapp02/85/Estado-Finito-de-Cadenas-de-Markov-49-320.jpg)








![ Si definimos v1 = 0, entonces
, junto con v1 = 0, que tiene la forma de
vector:
Esta ecuación v = r +[P]v es un grupo de M
ecuaciones lineales, de los cuales la primera es
v1 = 0 + v1, y , con v1 = 0, el ultimo M − 1
corresponde a](https://image.slidesharecdn.com/presentacionestadofinitodecadenasdemarkov-111216070929-phpapp02/85/Estado-Finito-de-Cadenas-de-Markov-59-320.jpg)

































































