Descargado 240 veces



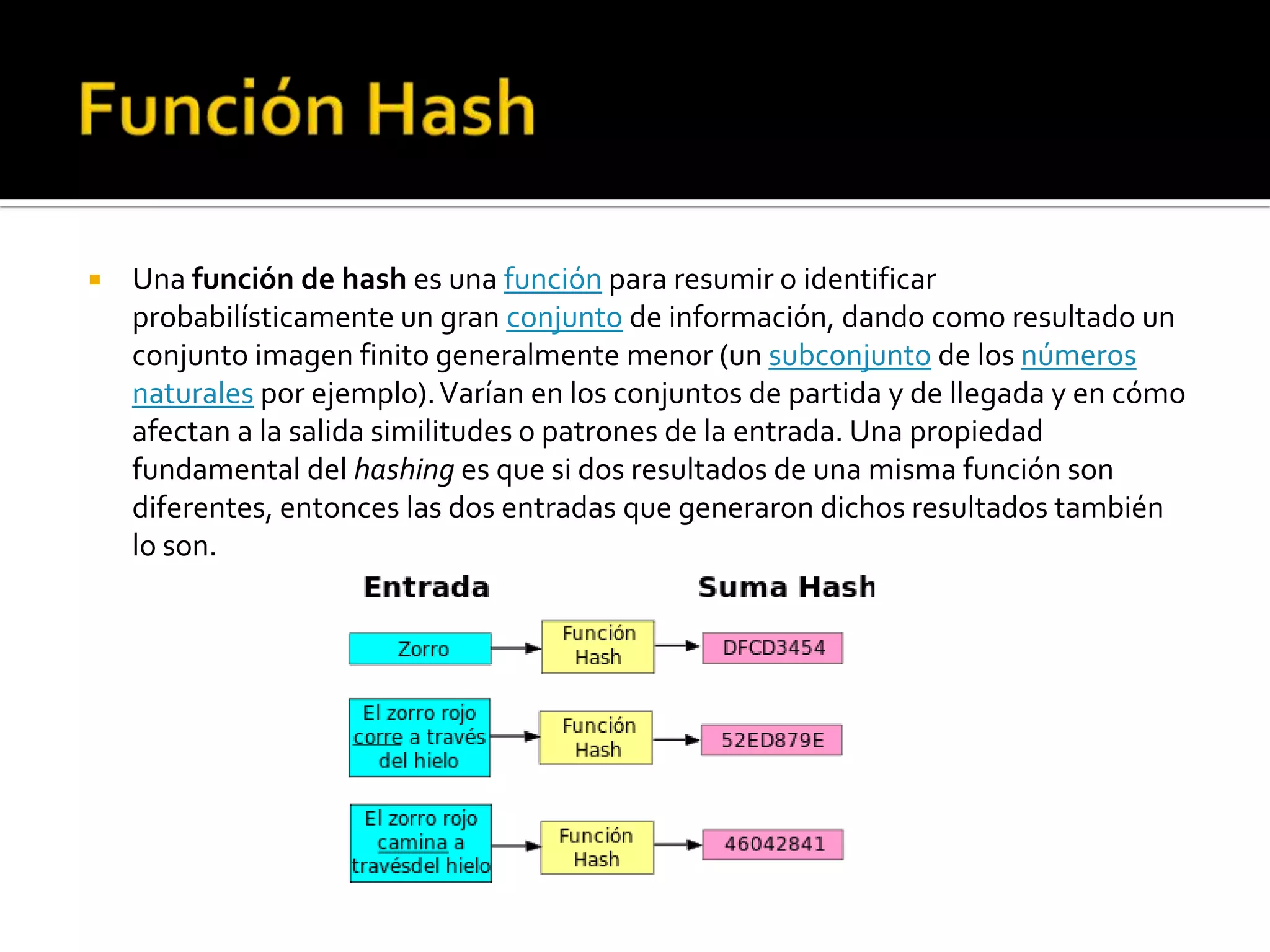




Un hash es el resultado de aplicar una función matemática a un documento u objeto para generar una clave única que lo represente de forma concisa. Las funciones hash se usan comúnmente en tablas hash para acelerar la búsqueda de información mediante el mapeo casi directo de claves a ubicaciones de memoria. Una buena función hash distribuye las claves de forma aleatoria para minimizar las colisiones donde claves diferentes generan la misma salida.























































































