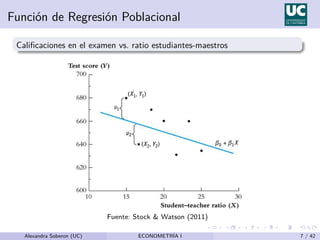
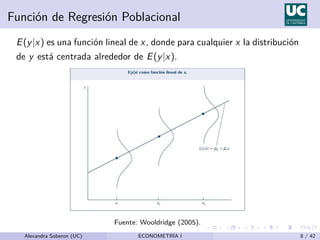
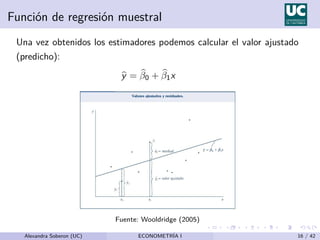
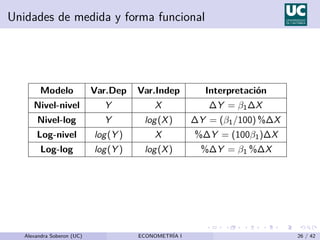
Este documento presenta el modelo de regresión lineal simple, que relaciona una variable dependiente (y) con una variable independiente (x) a través de una ecuación lineal. Explica que el modelo estima los parámetros β0 y β1 que representan el término constante y la pendiente de la recta de regresión, respectivamente. También describe los supuestos del modelo y cómo se estiman los parámetros usando el método de mínimos cuadrados ordinarios.







![Mı́nimos Cuadrados Ordinarios (MCO)
Dado que u = y − β0 − β1x, es posible expresar los parámetros
desconocidos en términos de x, y, β0 y β1. Ası́, obtenemos dos
restricciones de momento:
E [y − β0 − β1x] = 0
E [x(y − β0 − β1x)] = 0.
Método de los momentos: proceso de estimación que implica la
imposición de restricciones de momentos poblacionales sobre los
momentos muestrales.
¿Qué implica todo esto? Sea una muestra aleatoria de observacio-
nes de y, {yi }n
i=1, para estimar E(y) utilizamos la media muestral
y = 1
n
Pn
i=1 yi .
Alexandra Soberon (UC) ECONOMETRÍA I 10 / 42](https://image.slidesharecdn.com/pptch2g94214-15-220801022633-5b2907ef/85/Ppt_Ch2_G942_14-15-pdf-10-320.jpg)










![Bondad de ajuste
SST = SSE + SSR. Prueba:
n
X
i=1
(yi − y)2
=
n
X
i=1
[(yi − b
yi ) + (b
yi − y)]2
=
n
X
i=1
[b
ui + (b
yi − y)]2
=
n
X
i=1
b
u2
i + 2
n
X
i=1
b
ui (b
yi − y) +
n
X
i=1
(b
yi − y)2
= SSR + 2
n
X
i=1
b
ui (b
yi − y) + SSE,
donde sabemos que
Pn
i=1 b
ui (b
yi − y) = 0.
Alexandra Soberon (UC) ECONOMETRÍA I 22 / 42](https://image.slidesharecdn.com/pptch2g94214-15-220801022633-5b2907ef/85/Ppt_Ch2_G942_14-15-pdf-22-320.jpg)









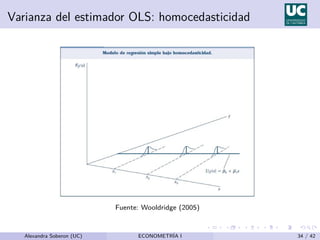
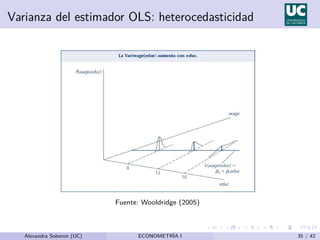
![Varianza de los estimadores MCO
Supuesto adicional: Var(u|x) = σ2 (homocedasticidad) y dado
que Var(u|x) = E(u2|x) − [E(u|x)]2
y E(u|x) = 0,
σ2
= E(u2
|x) = E(u2
) = Var(u).
Ası́, σ2 es la varianza incondicional, también conocida como la
varianza del error.
σ (la raı́z cuadrada de la varianza del error) es conocida como la
desviación estándar del error.
Alexandra Soberon (UC) ECONOMETRÍA I 33 / 42](https://image.slidesharecdn.com/pptch2g94214-15-220801022633-5b2907ef/85/Ppt_Ch2_G942_14-15-pdf-33-320.jpg)