Descargado 41 veces

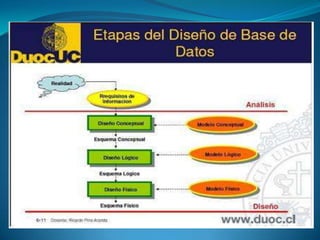
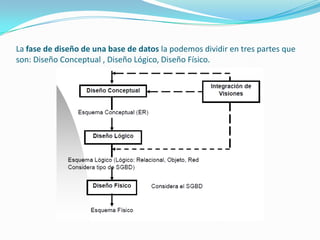







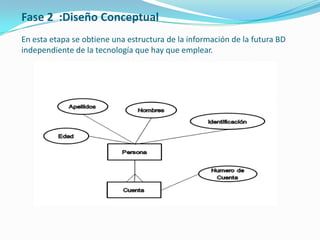







Este documento presenta las tres fases principales del diseño de una base de datos: el diseño conceptual, el diseño lógico y el diseño físico. En la fase de diseño conceptual, se identifican y documentan los requisitos de datos de la organización sin considerar aspectos tecnológicos. Luego, en el diseño lógico, se transforma el esquema conceptual en un modelo específico para un sistema de gestión de bases de datos. Finalmente, el diseño físico describe la implementación física de la base de datos en la memoria secundaria









































































