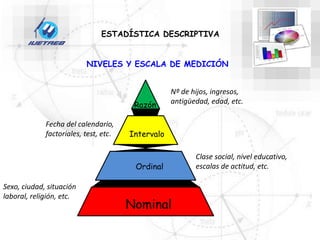
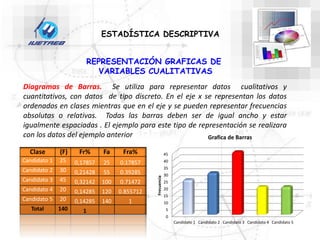
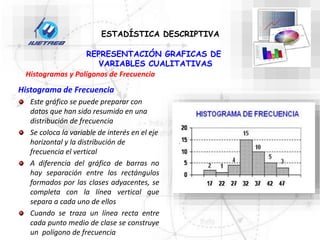
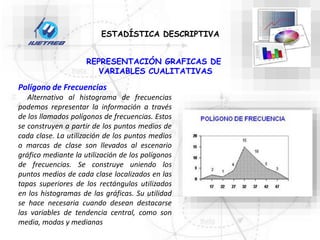
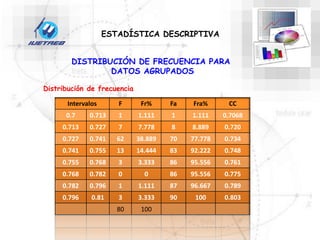
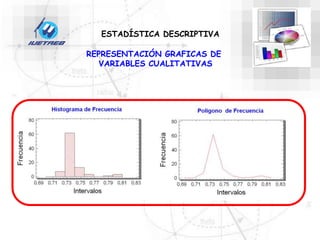
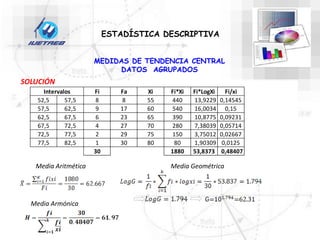
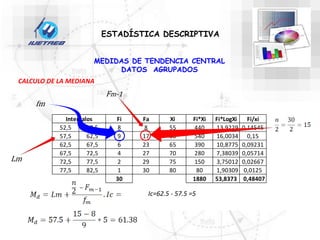
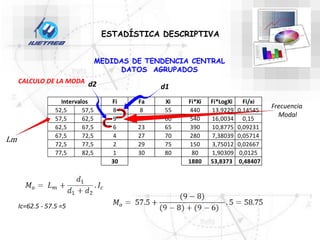
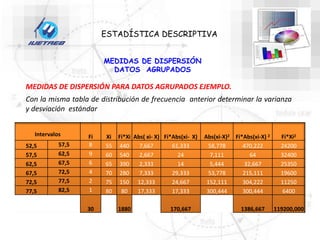
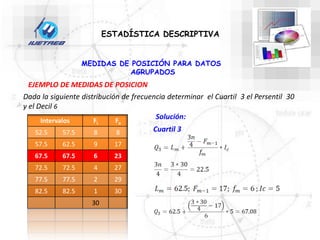
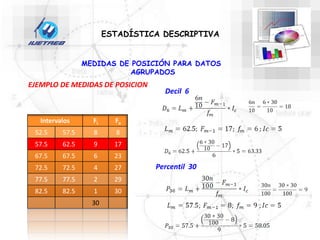
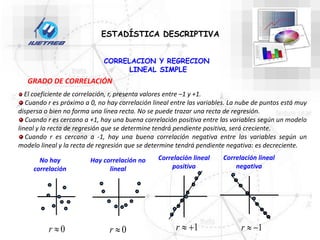
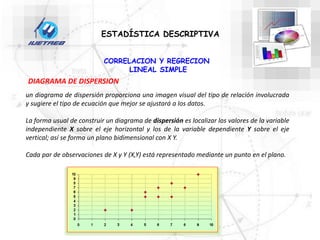
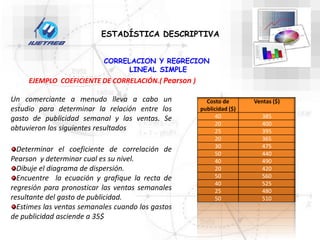
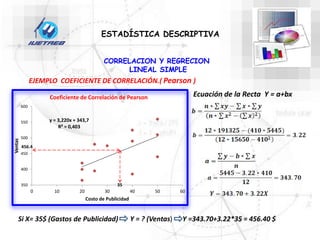
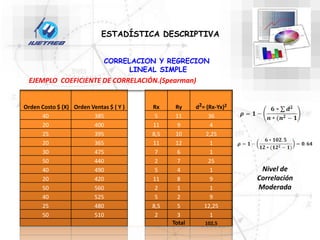
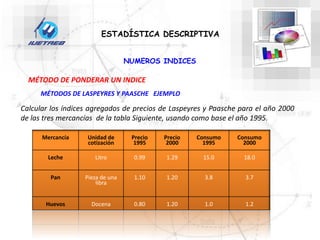
Este documento trata sobre la estadística. Explica que la estadística es el estudio de los métodos para recoger, clasificar, resumir y analizar datos, así como hacer inferencias basadas en estos datos. También menciona que la estadística actúa como puente entre los modelos matemáticos y los fenómenos reales, y que proporciona una metodología para evaluar las discrepancias entre la teoría y la realidad. Además, distingue entre estadística descriptiva e inferencial.