Descargar como PDF, PPTX






















![B´usquedas y
Ordenamientos
Angel
V´azquez-Pati˜no
B´usqueda
Utilidad
B´usqueda secuencial
B´usqueda binaria
Eficiencia
Ordenamiento
Utilidad
Clasificaci´on
Algoritmo de burbuja
Algoritmo de selecci´on
Algoritmo de inserci´on
Eficiencia
Burbuja
Selecci´on
Inserci´on
Fuentes
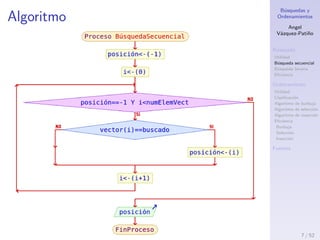
Ordenamiento de burbuja III
1. V´ıdeo: https://youtu.be/L3d48etbseY
Pseudoc´odigo
1: for i = 1 hasta n do
2: for j = 0 hasta n-i do
3: if arreglo[j] > arreglo[j+1] then
4: intercambiar(arreglo[j], arreglo[j+1]);
5: end if
6: end for
7: end for
25 / 53](https://image.slidesharecdn.com/capitulo7aovp-160609213031/85/Programacion-1-busquedas-y-ordenamientos-25-320.jpg)



![B´usquedas y
Ordenamientos
Angel
V´azquez-Pati˜no
B´usqueda
Utilidad
B´usqueda secuencial
B´usqueda binaria
Eficiencia
Ordenamiento
Utilidad
Clasificaci´on
Algoritmo de burbuja
Algoritmo de selecci´on
Algoritmo de inserci´on
Eficiencia
Burbuja
Selecci´on
Inserci´on
Fuentes
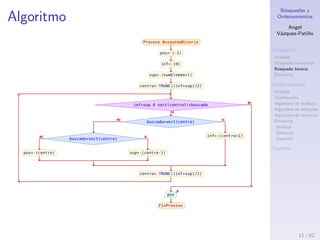
Algoritmo de selecci´on II
Pseudoc´odigo
1: for i = 0 hasta n-2 do
2: m´ınimo = i;
3: for j = i+1 hasta n-1 do
4: if arreglo[j] < arreglo[m´ınimo] then
5: m´ınimo = j;
6: end if
7: end for
8: intercambiar(arreglo[i], arreglo[m´ınimo]);
9: end for
29 / 53](https://image.slidesharecdn.com/capitulo7aovp-160609213031/85/Programacion-1-busquedas-y-ordenamientos-29-320.jpg)



![B´usquedas y
Ordenamientos
Angel
V´azquez-Pati˜no
B´usqueda
Utilidad
B´usqueda secuencial
B´usqueda binaria
Eficiencia
Ordenamiento
Utilidad
Clasificaci´on
Algoritmo de burbuja
Algoritmo de selecci´on
Algoritmo de inserci´on
Eficiencia
Burbuja
Selecci´on
Inserci´on
Fuentes
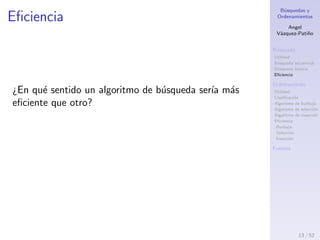
Algoritmo de inserci´on II
1. V´ıdeo 1: https://youtu.be/5kVQ8kf52K4
2. V´ıdeo 2: https://youtu.be/a7g7Z5dMdgQ
Pseudoc´odigo
1: for i = 1 hasta n-1 do
2: j = i;
3: while j > 0 and arreglo[j-1] > arreglo[j] do
4: intercambiar(arreglo[j], arreglo[j-1]);
5: j = j-1;
6: end while
7: end for
33 / 53](https://image.slidesharecdn.com/capitulo7aovp-160609213031/85/Programacion-1-busquedas-y-ordenamientos-33-320.jpg)





















Este documento trata sobre algoritmos de búsqueda y ordenamiento. Explica la búsqueda secuencial, la búsqueda binaria y tres algoritmos de ordenamiento: burbuja, selección e inserción. También analiza la eficiencia de estos algoritmos en términos del número de comparaciones requeridas, concluyendo que la búsqueda binaria es más eficiente que la secuencial al requerir O(log n) comparaciones en el peor caso.

























































