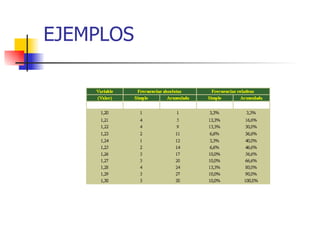
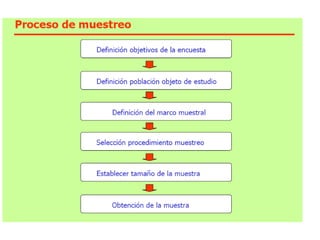
Este documento presenta conceptos básicos de estadística descriptiva, probabilidad y muestreo. Explica variables, medidas de posición central como la media y mediana, medidas de dispersión, distribución de frecuencias, y cálculo de probabilidades. También define términos como población, muestra, individuo y ofrece ejemplos para ilustrar los conceptos.






































































![Curso Estadistica Descriptiva[1]](https://cdn.slidesharecdn.com/ss_thumbnails/curso-estadistica-descriptiva1-1224279388013728-9-thumbnail.jpg?width=640&height=640&fit=bounds)






















































