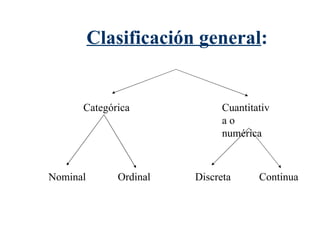
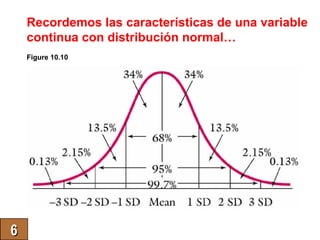
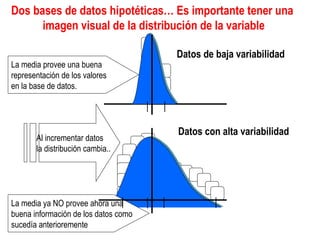
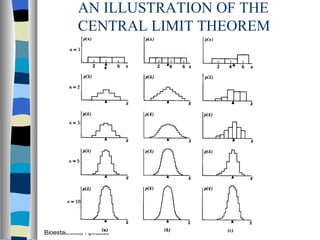
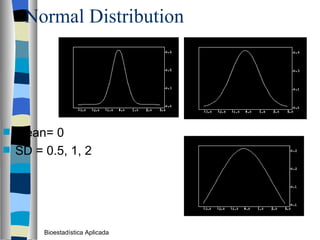
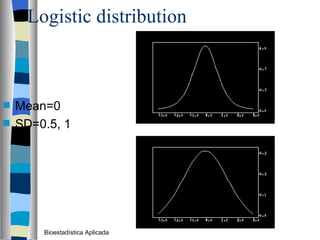
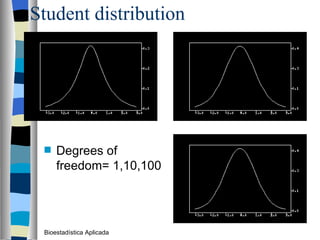
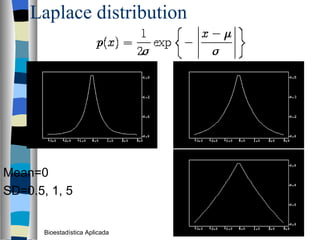
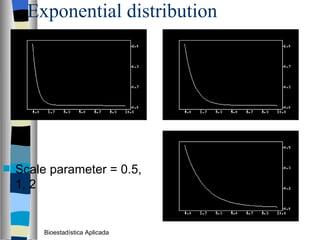
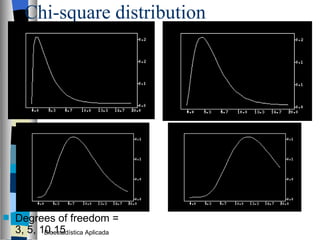
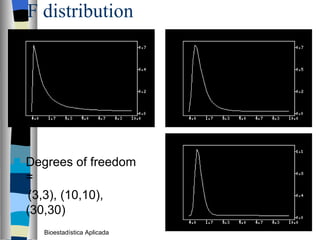
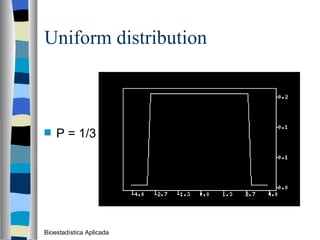
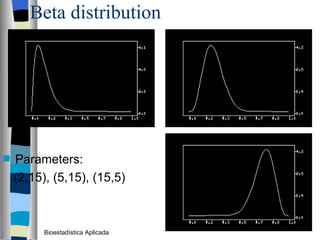
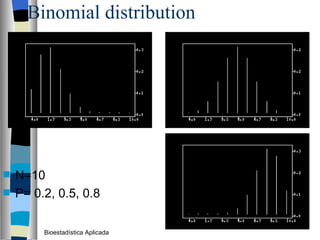
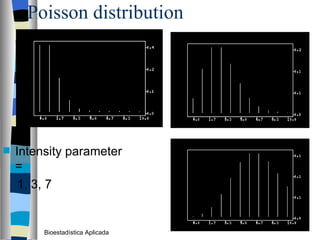
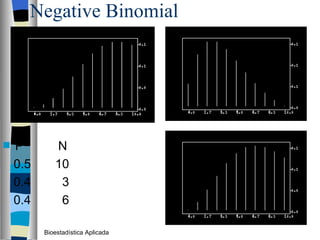
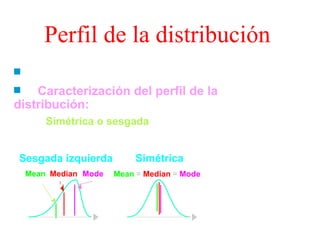
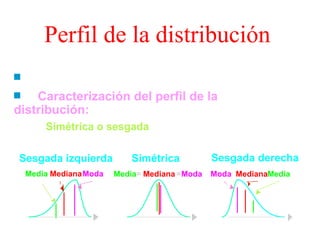
El documento trata sobre conceptos básicos de bioestadística como variables continuas y discretas, distribuciones de probabilidad como la normal y binomial, y el teorema del límite central. Explica que las variables continuas son independientes de cómo se miden y que al discretizar se pierde información. También describe diferentes distribuciones de probabilidad como la normal, exponencial y binomial y sus parámetros.


![Contactos Mirko Zimic Jefe de la Unidad de Bioinformática y Biología Computacional, Facultad de Ciencias, UPCH 3190000 anexo 2604 [email_address] [email_address] http://www.upch.edu.pe/facien/dbmbqf/docentes.htm http://www.abeperu.net/](https://image.slidesharecdn.com/distribucioncontinua-110202160349-phpapp02/85/Distribucioncontinua-2-320.jpg)
















































![Biol 2153-1-investigaciones [compatibility mode]](https://cdn.slidesharecdn.com/ss_thumbnails/biol-2153-1-investigacionescompatibilitymode-110421144324-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)































