Descargado 28 veces






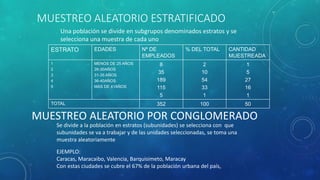




















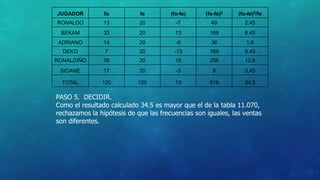

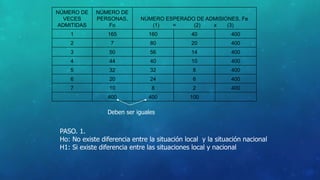
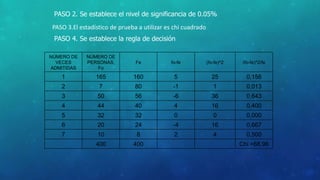


Este documento define la inferencia estadística y describe sus métodos fundamentales como la estimación, el contraste de hipótesis y los intervalos de confianza. Explica los tipos de muestreo probabilísticos y no probabilísticos, y los pasos para probar hipótesis estadísticas utilizando estadísticos como z, t de Student y Ji cuadrado.



































































