Descargado 55 veces





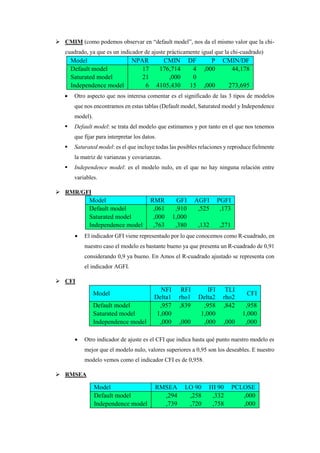


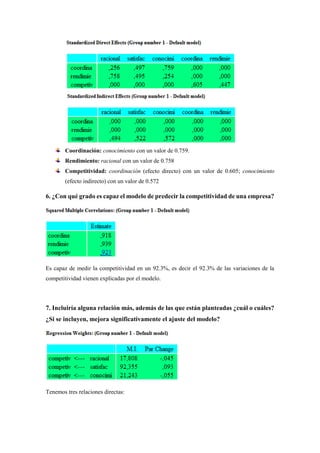


El análisis de caminos (path analysis) se utiliza para representar y medir las interdependencias entre variables a través de un modelo de regresión que establece relaciones causales. En un estudio de mercado de 500 empresas, se evaluaron variables como el conocimiento de los directivos, la satisfacción laboral y el rendimiento, encontrando que estos influyen sobre la competitividad empresarial, la cual puede ser predecida en un 92.3% por el modelo. Se sugiere que agregar relaciones adicionales entre variables puede mejorar significativamente el ajuste del modelo.






















































![Resumen temas vistos[1]](https://cdn.slidesharecdn.com/ss_thumbnails/resumentemasvistos1-100719000505-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
























