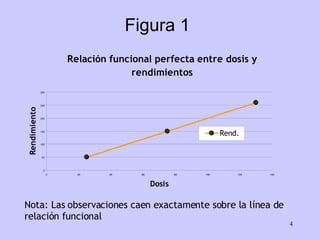
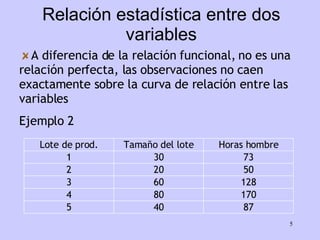
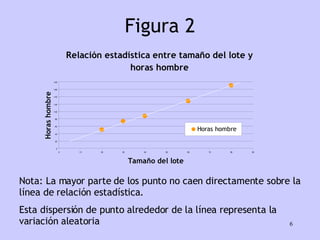
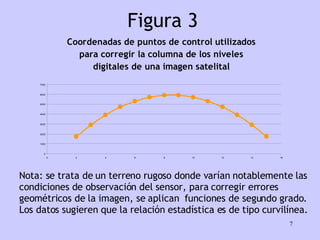
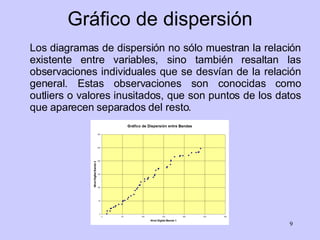
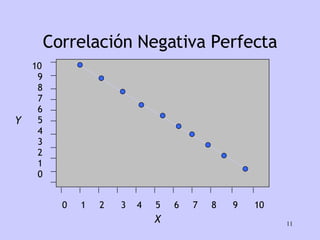
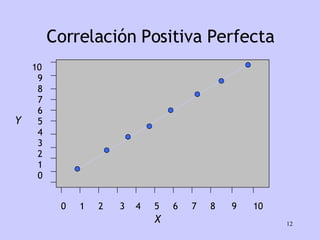
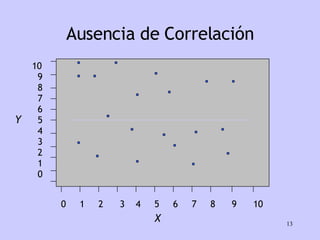
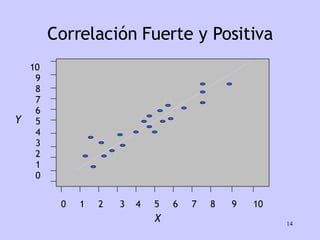
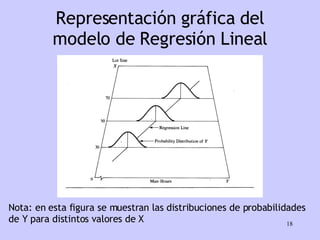
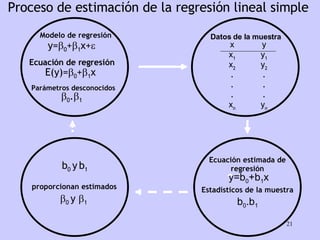
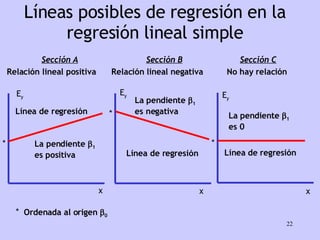
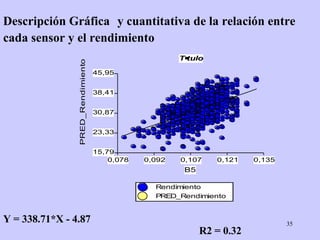
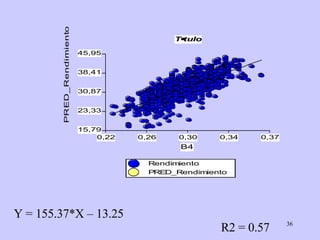
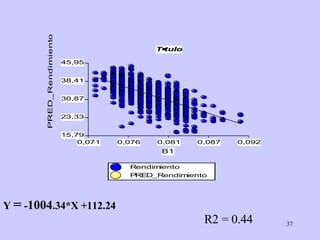
El documento analiza la relación entre variables a través de regresión y correlación. Explica que la regresión predice una variable en función de otras y que la correlación mide la intensidad de la relación. Define relación funcional como aquella expresada por una función matemática, a diferencia de la estadística donde los puntos no caen exactamente sobre la curva.