Descargado 360 veces






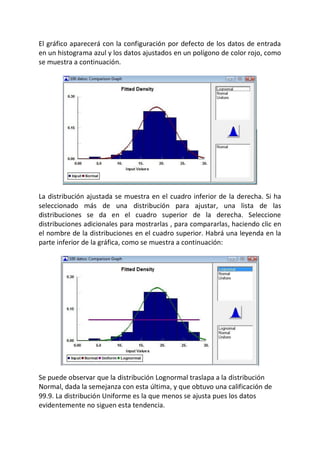

El documento describe el uso de la herramienta Stat::Fit para determinar que la distribución Normal es la que mejor se ajusta a los datos del ejercicio 6 de la página 91 del libro Simulación y Análisis de sistemas con Promodel. Stat::Fit realiza un análisis automático y determina que la distribución Normal con media 18.7 y desviación estándar 4.11 obtiene la máxima calificación, por lo que mejor representa los datos.
















































































