Descargar para leer sin conexión





![BURBUJA (BUBBLE)
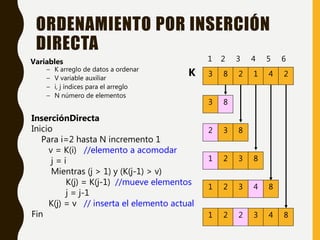
Variables
• n es el total de elementos
• K arreglo de llaves
• t variable auxiliar para el intercambio
• i,j variables para los indices
Burbuja
Inicio
para i= n-1 ; i>0 ; i--
para j=0; i>j; j++
si (k[j] > k[j+1])
t = k[j];
k[j]= k[j+1];
k[j+1] = t;
Fin
3 8 2 1 4
0 1 2 3 4 5
2
3 8 2 1 4 2
3 2 8 1 4 2
3 2 1 8 4 2
3 2 1 4 8 2
3 2 1 4 2 8
Primera
pasada](https://image.slidesharecdn.com/3-200401233913/85/3-algoritmos-de-ordenamiento-interno-6-320.jpg)
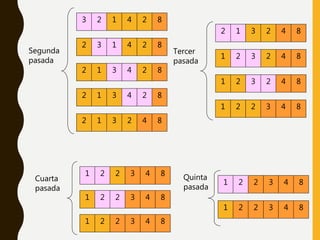

![SHELL SORTVariables
– K arreglo de datos a ordenar
– H tamaño del grupo
– i, j índices para el arreglo
– V variable auxiliar
– N número de elementos
– grupo arreglo con los tamaños de grupo
Shellsort
Inicio
grupo = [ 21, 7, 3, 1]
para g=0; g<4; g++
h=grupo[g];
para i=h; i<n; i++
v=k[i];
j=i;
mientras (j>=h && a[j-h]>v)
k[j]=k[j-h];
j=j-h;
k[j]=v;
Fin
3 7 9 0 5 1 6 8 4 2 0 6 1 5 7 3 4 9 8 2
3 7 9 0 5 1 6 8 4 2 0 6 1 5 7 3 4 9 8 2
3 3 2 0 5 1 5 7 4 4 0 6 1 6 8 7 9 9 8 2
3 3 2 5 7 4 1 6 80 5 1 4 0 6 7 9 9 8 2
0 0 1 3 3 4 5 6 81 2 2 4 5 6 7 7 9 8 9
0 0 1 1 2 2 3 3 4 4 5 6 5 6 8 7 7 9 8 9
0 0 1 1 2 2 3 3 4 4 5 5 6 6 7 7 8 8 9 9](https://image.slidesharecdn.com/3-200401233913/85/3-algoritmos-de-ordenamiento-interno-9-320.jpg)

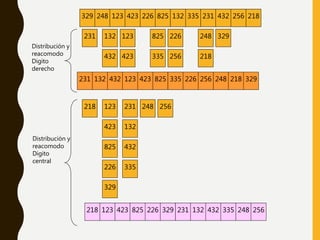
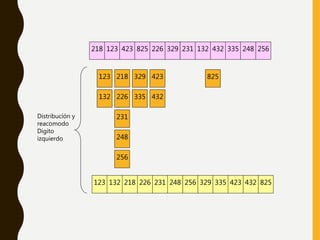
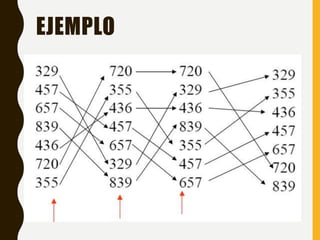






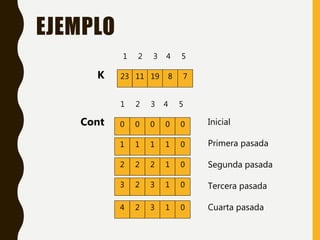


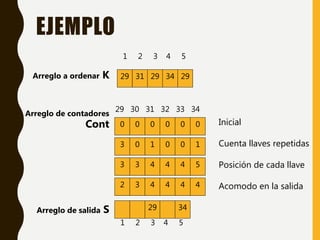


Este documento describe varios métodos de ordenamiento interno como inserción directa, burbuja, quicksort, shellsort, ordenamiento por conteo y ordenamiento por distribución. Explica los pasos de cada algoritmo y provee ejemplos para ilustrar cómo funcionan.























































































