Contenido para la presentación de un proyecto de investigación epidemiológica
•Descargar como DOC, PDF•
0 recomendaciones•1,387 vistas


Más contenido relacionado
La actualidad más candente
La actualidad más candente (18)
Similar a Contenido para la presentación de un proyecto de investigación epidemiológica
Similar a Contenido para la presentación de un proyecto de investigación epidemiológica (20)
Contenido para la presentación de un proyecto de investigación epidemiológica
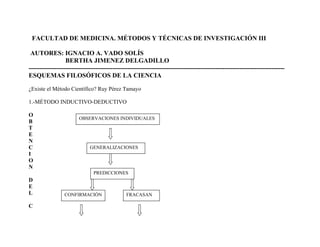
- 1. FACULTAD DE MEDICINA. MÉTODOS Y TÉCNICAS DE INVESTIGACIÓN III AUTORES: IGNACIO A. VADO SOLÍS BERTHA JIMENEZ DELGADILLO ----------------------------------------------------------------------------------------------------------------------- ESQUEMAS FILOSÓFICOS DE LA CIENCIA ¿Existe el Método Científico? Ruy Pérez Tamayo 1.-MÉTODO INDUCTIVO-DEDUCTIVO O B T E N C I O N D E L C OBSERVACIONES INDIVIDUALES GENERALIZACIONES PREDICCIONES CONFIRMACIÓN FRACASAN
- 2. O N O C I M I E N T O 2.- MÉTODO A PRIORI DEDUCTIVO O B T E N C I O N REFUERZAN DEBILITAN CAPTURA MENTAL DE PRINCIPIOS GENERALES DEDUCCIÓN DE INSTANCIAS PARTICULARES DIOS U OTRAS IDEAS
- 3. D E L C O N O C I M I E N T O 3.-MÉTODO HIPOTÉTICO-DEDUCTIVO O B T E N C DEMOSTRADAS OBJETIVAMENTE NO DEMOSTRADAS OBJETIVAMENTE I N T U I C I Ó N ELEMENTOS TEÓRICO- HIPOTÉTICOS
- 4. I O N D E L C O N O C I M I E N T O 4.- NO HAY MÉTODO (ANARQUISTA) CONFRONTACIÓN CON LA NATURALEZA (PRUEBAS) OBSERVACIONES EXPERIMENTOS DOS CORRIENTES NUNCA HA HABIDO UN MÉTODO EXISTEN MUCHOS MÉTODOS DEBIDO A LA DIVERSIFICACIÓN DE LA CIENCIA
- 5. LA INVESTIGACIÓN Y EL MÉTODO CIENTÍFICO. F.H. de Canales, E.L. de Alvarado y E. B. Pineda. Ciencia - Concepto: conocimiento racional, cierto o probable, obtenido metódicamente, sistematizado o verificable. - Clasificación: Pura o formal y fáctica o aplicada Teoría - Concepto: principios generales que orientan la explicación de uno o varios hechos específicos que se han observado en forma independiente, y que están relacionados con un modelo conceptual. - Clasificación: descriptivo, explicativo y predictivo. Método Científico - Concepto: proceder ordenado y sujeto a ciertos principios o normas para llegar de una manera segura a un fin u objetivo que se ha determinado de antemano. - Etapas: planteamiento del problema, construcción de un modelo teórico, deducción de juicios y razonamientos (hipótesis), prueba de las hipótesis y conclusiones. Investigación - Concepto: estudio sistemático, controlado, empírico, reflexivo, y crítico de proposiciones hipotéticas sobre las supuestas relaciones que existen entre fenómenos naturales. Permite descubrir nuevos hechos o datos, relaciones o leyes en cualquier campo del conocimiento humano. - Tipos: descriptiva , analítica y experimental. EL MÉTODO CIENTÍFICO. ¿MITO O REALIDAD? Luis Benítez Bribiesca. Orígenes del pensamiento Occidental -Pitágoras, Aristóteles, Bacon, Galileo, Bernard, Popper, Medawar y otros. Conclusiones: -No existe método para descubrir una teoría científica
- 6. -No existe método de verificación -No existe método para averiguar si una hipótesis es probablemente verdadera. ¿Cómo se originan LAS INVESTIGACIONES? ¡ IDEAS ! Fuentes de ideas para investigaciones: -experiencias individuales -materiales escritos -observaciones de hechos -teorias -creencias e incluso presentimientos ¿Como y donde surgen las ideas? -pueden surgir donde se congregan grupos (Hospitales, Industrias, Universidades, Centros de Investigaciones, Colegios, Asociaciones, Congresos etc. Otras consideraciones: -Vaguedad de las ideas La mayoría de las ideas iniciales son vagas y requieren analizarse para que sean transformadas en planteamientos más precisos y estructurados. -Importancia del conocimiento de los antecedentes De preferencia seleccionar temas de investigación que no han sido estudiados muy a fondo.
- 7. Estructurar formalmente la idea de investigación Seleccionar la perspectiva desde la cual se abordará la idea de investigación -Investigación previa de los temas Temas ya investigados, estructurados y formalizados. Temas ya investigados pero menos estructurados y formalizados Temas poco investigados y poco estructurados Temas no investigados -Criterios para generar ideas Ideas de investigación nuevas, originales, de frontera. Ideas no nuevas pero si novedosas. Las buenas ideas generan teorías y solucionan problemas.
- 8. SACRIFICAR Y OBTENER BAZO CORAZÓN HIGADO Y CEREBRO ESTUDIO DE TOXOPLASMOSIS EN MUJERES Y RESERVORIOS DEL MUNICIPIO DE TICUL (MUESTREO) GALLINAS, GATOS, SUELO SACRIFICAR CORAZÓN FORMOL ESTUDIO HISTOPATOLOGICO INOCULAR RATONES ESTOMAGO ¿Asociación? SACRIFICAR Y OBTENER BAZO CORAZÓN HIGADO Y CEREBRO IDENTIFICACION DE POR PCR TIPOS I, II Ó III MUJERES QUE ABORTAN (MUESTREO) PLACENTASANGRE SEROLOGIA IgG, IgM, IgE, IgA. IDENTIFICAR AGENTE ( PCR) INOCULAR RATONES IDENTIFICACION POR PCR IDENTIFICACION POR PCR TIPOS I, II Ó III IDENTIFICACION POSITIVA
- 9. Corroborar casos de Pirexia de origen no conocido. Tipo de Muestreo Sangre Serología (IgG e IgM) ¿Determinar tamaño de la muestra ? •Centro de Salud de la Localidad •Casos que hayan presentado: •Fiebre •Cefalea •Mialgia •Artralgia 1 2 3 4 5 Determinar Prevalencia en la Población 6 Encuestas 4’ Procesar datos 5’ Identificar factores de riesgo 6’ LEPTOSPIROSIS.
- 10. VIGILANCIA EPIDEMIOLOGICA Antecedentes.- Esta práctica tiene su origen hace unos 600 años en Venecia, cuando tres guardias se encargaban de detener las embarcaciones que arribaban al puerto con casos de peste o provenían de lugares sospechosos. Con la detención de los viajeros para su observación durante cuarenta días, se instituyó la cuarentena como una de las primeras intervenciones sanitarias para detener la transmisión de agentes infecciosos. El término “vigilancia” de origen francés, fue introducido durante las guerras napoleónicas para hacer referencia a la necesidad de mantener vigilados a ciertos grupos de personas. En 1963, Lagmuir la definió como la observación continuada de la distribución y de las tendencias de la enfermedad mediante la recogida sistemática, la consolidación y la evaluación de informes de morbilidad y mortalidad, así como de otros datos relevantes. Objetivos a.- Detectar epidemias b.- Detectar casos individuales de problemas especiales c.- Detectar cambios en los agentes causales d.-Contribuir al conocimiento de la historia natural de la enfermedad e.- Facilitar la planificación y evaluación de programas de salud f.- Detectar cambios de tendencias g.- Efectuar proyecciones futuras Clasificación 1.- Activa 2.- Pasiva Sistemas utilizados para la vigilancia a.- Notificación obligatoria de enfermedades b.-Vigilancia basada en los laboratorios c.-Registros de enfermedades d.-Sistemas centinela
- 11. ESTUDIOS CLÍNICO -EPIDEMIOLÓGICOS TIPO DE ESTUDIO SINÓNIMOS UNIDAD DE ESTUDIO ESTUDIOS OBSERVACIONALES Estudios descriptivos Estudios transversales De sección cruzada Individuos De prevalencia De caso o serie de casos Pacientes Estudios analíticos Casos y controles Casos y testigos Individuos Cohorte Seguimiento Individuos Ecológicos De correlación Poblaciones (Paises) ESTUDIOS EXPERIMENTALES Estudios de intervención Ensayos aleatorios controlados Ensayos clínicos Pacientes Ensayos no aleatorios controlados Cuasiexperimentales Pacientes Ensayos de campo - Personas sanas Ensayos comunitarios Ensayos de intervención Comunidades
- 12. Manipulación de las variables por el investi INVESTIGACIÓN CLÍNICA- EPIDEMIOLÓGICA gador, intervención. Secció n cruzad a Casos y Controles Estudi o cohorte Estudio experimental exexperimental Estudio observacional Distribución al azar Comparación de grupos Ensayo controlado aleatorizado Ensayo controlado no aleatorizado Estudio analítico Estudios descriptivos NoSi Si No NoSi INVESTIGACIÓN CLÍNICA-EPIDEMIOLÓGICA SERIE CASO SSS
- 13. ESTUDIOS OBSERVACIONALES TRANSVERSALES Y EXPLORATORIOS DIFICIL DETECTAR CON PRECISIÓN LA RELACIÓN CAUSA-EFECTO PREVIOS A ESTUDIOS COMPARATIVOS GENERAN HIPÓTESIS AUNQUE NO SIEMPRE UTILIZAN LOS MÁS COMUNES EN EPIDEMIOLOGÍA DETECTAN FRECUENCIA Y DISTRIBUCIÓN DE LA ENFERMEDAD NO HAY GRUPO CONTROL ESTUDIO DE SECCIÓN CRUZADA O DE PREVALENCIA TIEMPOTIEMPO EXPOSICIÓNEXPOSICIÓN RESULTADOSRESULTADOS
- 14. ESTUDIO DE CASO O DE SERIE DE CASOS: Se establece el cuadro clínico de enfermedades nuevas o raras en alguna región o lugar realizándose un estudio descriptivo de las mismas. Ejemplo.1) Un deportista de élite con síndrome de Gilbert. 2) Hemorrhagic pulmonary leptospirosis: three cases from the Yucatán, peninsula, Mexico. DISEÑO DE UN ESTUDIO DE CASOS Y CONTROLES -SENCILLOS Y ECONÓMICOS -INVESTIGAN LAS CAUSAS DE LA ENFERMEDAD -LONGITUDINALES -RETROSPECTIVO - UTILIZAN GRUPO CONTROL -EFECTO-CAUSA DIRECCIÓN DE LA INVESTIGACIÓN POBLACIÓN CASOS (ENFERMOS) CONTROLES (NO ENFERMOS) NO EXPUESTOS EXPUESTOS EXPUESTOS NO EXPUESTOS TIEMPOTIEMPO
- 15. DISEÑO DE UN ESTUDIO DE COHORTE -PROSPECTIVO -LONGITUDINALES -LARGOS PERÍODOS DE SEGUIMIENTO -PARTEN DE LA CAUSA BUSCANDO EL EFECTO -MÁS COSTOSOS -MIDEN INCIDENCIA -CAUSA-EFECTO EXPUESTOS POBLACIÓN NO EXPUESTOS SIN ENFERMEDAD CON ENFERMEDAD CON ENFERMEDAD SIN ENFERMEDAD PERSONAS SIN LA ENFERMEDAD TIEMPO TIEMPO DIRECCIÓN DE LA INVESTIGACIÓN
- 16. CONTENIDO PARA LA PRESENTACIÓN DE UN PROTOCOLO DE INVESTIGACIÓN . -TÍTULO -INTRODUCCIÓN -ANTECEDENTES -JUSTIFICACIÓN -PLANTEAMIENTO DEL PROBLEMA -HIPÓTESIS (puede omitirse en estudios descriptivos) -OBJETIVOS (general, específicos, metas) -MATERIAL Y MÉTODOS ( a veces solo se usa metodología) -CRONOGRAMA -BIBLIOGRAFÍA -ANEXOS FORMATO UPI 1.-TÍTULO 2.-DATOS DE IDENTIFICACIÓN De la institución. a) Hospitalaria b) Universitaria c) De la especialidad que está cursando De los investigadores: a) Del investigador principal (alumno, escribir su nombre completo y otros datos de identificación) b) De los asesores 3.- MARCO TEÓRICO a)Definición del problema b) Antecedentes c) Justificación d) Hipótesis e) Objetivo general 4.- MATERIAL Y MÉTODO a)Objetivos específicos b)Diseño: a).- Definición del universo b).-Tamaño de la muestra c).-Definición de las unidades de observación
- 17. d).- Definición del grupo control e).-Criterios de inclusión f).-Criterios de exclusión g).-Criterios de eliminación h).-Definición de variables y unidades de medida i).- Selección de las fuentes, métodos, técnicas (laboratorio) y procedimientos de recolección de información. j).- Prueba piloto k).-Definición del plan de procesamiento (datos) y presentación de la información. c)Referencias bibliográficas 5.- ORGANIZACIÓN DE LA INVESTIGACIÓN: a)Cronograma de actividades b)Recursos humanos c)Presupuesto d)Difusión 6.- ANEXOS: a) Instrumentos de recolección b) Instructivos c) Los demás que requieran las instituciones respaldantes o que los investigadores consideren de interés. INFORME FINAL DEBE CONTENER: -RESUMEN -INTRODUCCIÓN -ANTECEDENTES -OBJETIVO GENERAL -OBJETIVOS ESPECÍFICOS -MATERIAL Y MÉTODOS -RESULTADOS -DISCUSIÓN O ANÁLISIS -CONCLUSIONES -REFERENCIAS BIBLIOGRÁFICAS -ANEXOS
- 18. DESGLOSE DE LOS COMPONENTES DE UN PROTOCOLO TÍTULO: Es el primer acercamiento que tiene el lector con cualquier documento (libro, artículo científico, folletos etc.), el cual le permite su aceptación o rechazo. Particularmente en un proyecto de investigación, debe describir el contenido en forma clara, exacta y concisa, de manera que permita el fácil reconocimiento del tema en cuestión. Además, debe ser congruente con el problema y los objetivos planteados. Máximo 15-20 palabras. No incluir siglas o abreviaturas. Ejem: Eficiencia entre la mesoterapia y la fisioterapia en el tratamiento de las lumbalgias. -Prevalencia y factores asociados al consumo de tabaco en estudiantes del campus de la salud de la UADY. INTRODUCCIÓN: incluye teorías y conceptos del tema en cuestión, a nivel internacional, nacional y local. El texto se orienta hacia la particularidad del tema que se pretende estudiar. Debe ser apoyada con referencias bibliográficas. ANTECEDENTES: breve exposición del desarrollo histórico-científico del problema así como de otros datos que apoyen y fundamenten la investigación. Debe ser apoyada con referencias bibliográficas. JUSTIFICACIÓN: se establece la contribución de los resultados del proyecto, es decir, se describe el grado en que el trabajo propuesto resuelve el problema antes descrito. Incluye las razones, los beneficios y la relevancia de realizar el proyecto de investigación. Ejem: Se requiere conocer las causas de la baja cobertura del programa de detección oportuna de cáncer cervicouterino dentro del contexto cultural local (razón), de esta manera se podrán diseñar campañas de difusión y de educación específicas a la población blanco, incrementando así las posibilidades de utilización del mismo (beneficio). De no realizarse el proyecto, se pueden realizar campañas con el riesgo de fracasar, por desconocimiento del origen del problema (relevancia). Las razones de la investigación son los argumentos que la motivan; sus beneficios, la utilidad que representa el proyecto; la relevancia es el porqué no se puede prescindir de la realización del proyecto.
- 19. PLANTEAMIENTO DEL PROBLEMA: el planteamiento del problema marca el arranque de la investigación, ya que es donde el investigador plasma la realidad de una situación imperante para ser investigada. Es recomendable que este se exprese en términos de duda, desconocimiento, falta de precisión en el conocimiento actual o discrepancia entre lo que es y lo que debe ser, asociado en la medida de lo posible, de su origen, magnitud, trascendencia, vulnerabilidad y alternativas de solución; es recomendable terminar el planteamiento del problema con una pregunta de investigación. Ejem: la cobertura del programa de detección oportuna de cáncer cervicouterino (DOC) en el estado X es muy baja (discrepancia). En los últimos cinco años la cobertura estatal del programa de (DOC) es del 20% (magnitud). La falta de difusión del programa y el excesivo pudor que muchas mujeres experimentan por la realización del examen citológico, son causas posibles de la bajísima cobertura (posible origen). El CACU, se detecta fácilmente y es curable en etapas tempranas, por lo que puede considerarse que todas aquellas muertes por esta causa pudieron haberse prevenido (trascendencia). Campañas de difusión y de educación pueden y deben incrementar la cobertura de tan importante programa preventivo (vulnerabilidad y alternativas de solución). ¿Cuál es o son las causas de la baja cobertura del programa de detección oportuna del CACU en el estado X? El origen de esta pregunta puede ser:1) la propia inquietud del investigador, que busca respuestas racionales a lo que sucede en su entorno o 2) una necesidad muy concreta de una institución o de una población específica. Por tanto, si no existe pregunta de investigación, no hay investigación. HIPÓTESIS: son respuestas tentativas o provisionales que se pretenden demostrar al final del estudio. Manifiestan una relación productiva entre las variables de interés en aquellos estudios de causa –efecto : El nivel de colesterol alto (causa) se asocia a una cifra elevada de presión arterial sanguínea (efecto). o expresan una diferencia con respecto a un valor preestablecido: El nivel de colesterol de la población X es mayor al promedio de colesterol de la población nacional (valor preestablecido).
- 20. O en relación al correspondiente grupo de control: El promedio del nivel de colesterol es menor en el grupo de estudio expuesto a la intervención (medicamento)“A”, en comparación al correspondiente del grupo sin la intervención (sin medicamento) (grupo control). Las hipótesis se verifican estadísticamente por diversas pruebas de análisis y por lo general, se enuncian mediante una expresión nula o alterna. Hipótesis nula: se plantea con el propósito deliberado de rechazarla y se le representa con el símbolo Ho. Por lo general el enunciado se presenta en términos de no diferencia o igualdad o de no asociación entre las variables de interés. Hipótesis alterna: es la que se cree verdadera. Se plantea con el propósito deliberado de aceptarla y se le representa con el símbolo Ha. Por lo general se plantea en términos positivos, es decir de diferencia o desigualdad o de asociación entre las variables de interés. Ho: El nivel de 310 mg de colesterol o mayor no se asocia con la presencia de infarto del miocardio. Ha: El nivel de 310 mg de colesterol o mayor se asocia con la presencia de infarto del miocardio. No todos los estudios de investigación requieren de planteamiento y verificación estadística de hipótesis, tal es el caso de los estudios descriptivos o de los exploratorios. OBJETIVO GENERAL: describe el propósito global que se espera lograr, por lo que debe ser susceptible de medición. Representa la guía o la línea de investigación y debe expresarse de manera clara y concisa. Se recomienda incluir objetivos específicos, los cuales tienen que ser congruentes entre sí. El objetivo general es el que resume el propósito de la investigación y se asemeja al título del mismo. Objetivo general: Evaluar la calidad de la atención médica en pacientes pediátricos con asma bronquial. Objetivos específicos: 1) Identificar el apego a lineamientos diagnósticos normados. 2) Identificar el apego a lineamientos terapéuticos normados.
- 21. 3) Determinar la prevalencia de complicaciones hospitalarias previsibles. MATERIAL Y MÉTODOS. Diseño del estudio.- EASTADÍSTICA INFERENCIAL (MUESTREO) CONCEPTOS: ESTADÍSTICA INFERENCIAL. Procedimiento por medio del cual, se llega a conclusiones acerca de una población con base en la información que se obtiene a partir de una muestra seleccionada de esa población. Considera dos grandes áreas: a).- La estimación b).- La prueba de hipótesis La estimación produce un cálculo aproximado de un parámetro, llámese porcentaje o promedio en la población. Prueba de hipótesis da respuesta a la existencia de una asociación o una diferencia entre los parámetros POBLACIÓN O UNIVERSO Conjunto grande de individuos que deseamos estudiar y que reúne determinadas características. a.-Finita b.-Infinita Parámetros: valores de la población o universo (promedio, porcentaje, varianza etc) d)MUESTRA Conjunto menor o subconjunto de individuos sobre el que realizamos las mediciones o el experimento con la intención de obtener conclusiones generalizables a la población o universo. Debe ser representativa de la población o sea que cada individuo de la población en estudio debe haber tenido la misma probabilidad de ser elegido.
- 22. Estadísticos o estimadores. Valores de la muestra que se infieren a la población (promedio, varianza, porcentaje etc). RAZONES PARA ESTUDIAR MUESTRAS EN LUGAR DE POBLACIONES - Ahorro en tiempo y dinero - Aumenta la calidad del estudio - Diminuir la heterogeneidad de la población mediante criterios de inclusión y/o exclusión. INDIVIDUO O SUJETO DE ESTUDIO (unidad de interés) Cada uno de los componentes de la muestra o población PROCEDIMIENTO PARA OBTENER UN TAMAÑO DE MUESTRA EN ESTMACIONES. 1) Población 2) Precisión o error aleatorio 3) Prevalencia estimada (%) o variabilidad esperada en la variable de interés 4) Riesgo, error tipo 1 o significancia estadística (&) SELECCIÓN DE UNA FÓRMULA MATEMÁTICA ADECUADA PARA CALCULAR EL TAMAÑO DE MUESTRA Que tipo de población es? (finita o infinita) Que tipo de inferencia será realizada? (estimación o prueba de hipótesis) Que tipo de parámetro será empleado? (una media o un porcentaje) ---------------------------------------------------------------------------------------------- Para población finita. Estimación Tipo de estimación Fórmula
- 23. NZ²PQ Proporción de una población n= ------------------------- d² (N-1) +Z²PQ NZ² s² Media de una población n= --------------------------- d² (N-1) +Z² s² ---------------------------------------------------------------------------------------------- Para población infinita. Estimación tipo de estimación fórmula Z2 PQ Proporción en una población n= ------------- d² Z² s² Media en una población n= ------------ d² Valores de Z para los IC de mayor uso (ESTIMACIONES) --------------------------------------------------------------------------------------------------------- Intervalo de confianza Valor Z 0.90 1.64 0.95 1.96 0.99 2.57 _____________________________________________________________
- 24. INTERVALOS DE CONFIANZA.- (para estimaciones) Conjunto de valores que rodean al valor estimado (muestra) y que tienen una probabilidad específica( nivel de confianza) de contener al valor verdadero de la población. DE UNA PROPORCIÓN Ejem. Se desea estimar la proporción de afecciones pulmonares (p) de una región. Después de seleccionar de forma aleatoria a 125 individuos de la región, 12 padecían afecciones pulmonares. p. (1-p) IC 95% (p)=p±1.96 ( √ -------- ) =0,096± 0,052 = IC 95%(p)= (0,044-0,148) n Donde p es la proporción de afecciones pulmonares encontradas en la muestra. La prevalencia de afecciones pulmonares de la región está entre 4,44 y 14,8% con una confianza del 95%; un individuo de esa región seleccionado al azar tiene una probabilidad de entre 0,044 y 0,148 de padecer una afección pulmonar DE UNA MEDIA Ejem: Un cardiólogo está interesado en encontrar un intervalo de confianza de 95% (IC 95%), para la presión sistólica media de una población (μ) después de un ejercicio físico. Para ello selecciona una muestra aleatoria de 100 individuos, obteniendo una media (x =145) y una desviación (s = 8) IC 95% (μ)= x ± 1,96 . ( s/√n) = 145± 1,57 La presión sistólica media tras un ejercicio está entre 143,4 y 146,6 con una seguridad del 95%.
- 25. EJEMPLOS: 1).- Objetivo del proyecto de investigación: “Estimar la proporción (P) de mujeres en edad reproductiva que usan anticoncepción efectiva”. Preguntas: Que tipo de población es? Que tipo de inferencia será realizada? Que tipo de parámetro será estimado? Cual es la variable de interés y en que escala se encuentra? Datos previos: Los investigadores piensan que el parámetro P esta alrededor de 40% (0.40) También deciden tener un margen de error (error aleatorio o precisión) del 10% (.10) Los investigadores aspiran a tener una confianza del 95% Z2 PQ Proporción en una población n= ------------- d² 1.962 x .40 (1- .40) .921984 n= -------------------------------= --------------------- .102 .01 Se requieren estudiar 92 mujeres para lograr el objetivo. ( Calcular en EpiInfo) TAMAÑO DE MUESTRA PARA UN PROYECTO DE TOXOPLASMOSIS 1) UNIVERSO : INFINITO (NO SABEMOS EL NÚMERO DE ABORTOS QUE SE PRESENTARÁN) 2) PREVALENCIA ESTIMADA: 16% (OBTENIDA DEL ESTUDIO PILOTO)
- 26. 3) PRESICIÓN: 3% (5% ES EL CONVENCIONAL, PERO USAMOS EL 3% PARA DISMINUIR EL IC) 4) ERROR & DE : 5% (NIVEL DE CONFIANZA DE 95%) Z2 PQ n=--------- d2 1.962 x (.16 x .84) 3.84 x 0.1344 n= ---------------------------= -----------------------= 573 .32 .09 EL ESTUDIO ANALIZARÁ COMO MÍNIMO 600 MUESTRAS DE SANGRE Y PLACENTA DE MUJERES QUE ABORTEN EN HOSPITALES QUE SE ENCUENTRAN EN TRES SECTORES (200 MUESTRAS POR SECTOR)EN QUE SE DIVIDE EL ESTADO DE YUCATÁN SEGÚN LA SSY.
- 27. 2).- 1).- Objetivo del proyecto de investigación: “Estimar el promedio (µ) de edad de mujeres en edad reproductiva que usan anticoncepción efectiva”. Preguntas: Que tipo de población es? Que tipo de inferencia será realizada? Que tipo de parámetro será estimado? Cual es la variable de interés y en que escala se encuentra? Datos previos: Los investigadores piensan que los valores extremos de la edad están entre 18 y 42 años. La DE (s) se obtiene dividiendo este rango entre 4 (42-18= 24/4)= 6 También deciden tener un margen de error (error aleatorio o precisión) de 3 años. Los investigadores aspiran a tener una confianza del 95% Z2 s2 Media en una población n= ------------- d² 1.962 x 62 138.297 n= -------------------------------= ---------------------= 15.4 32 9 Se requieren estudiar 15 mujeres para lograr el objetivo ---------------------------------------------------------------------------------------------- Prueba de hipótesis (Diferencia entre parámetros) Preguntas a realizar para poder seleccionar la fórmula matemática adecuada para calcular el tamaño de la muestra. Que tipo de población es? Que tipo de inferencia será realizada? Que tipo de parámetro será empleado? Es una prueba de una o de dos colas?
- 28. Variable de interés y escala? Tipo de prueba de hipótesis Fórmula Diferencia de proporciones de dos (Zα + Zβ)² (P Q +Pо Qо) poblaciones o de una proporción n= --------------------------------- de referencia (P - Pо)² Ejem: Demostrar que la proporción de mujeres en edad reproductiva, residentes de zonas urbanas, en uso de anticoncepción efectiva, es mayor que la proporción correspondiente en zonas rurales Valores de significancia Zα de mayor uso (PARA PRUEBAS DE HIPOTESIS) α de 1 cola Valor de Z α de dos colas Valor de Z 0.10 1.28 0.10 1.64 0.05 1.64 0.05 1.96 0.01 2.33 0.01 2.57 ______________________________________________________________ _______________________________________________________________ Valores de Zβ para potencias de uso frecuente (PARA PRUEBAS DE HIPOTESIS) β de una cola Potencia Valor de Z β de dos colas Potencia valor de Z _______________________________________________________________ 0.30 0.70 0.52 0.30 0.70 1.0 0.20 0.80 0.84 0.20 0.80 1.2 0.10 0.90 1.28 0.10 0.90 1.6 _______________________________________________________________ EXPLICACIÓN:
- 29. 1.-Si el estudio encuentra una diferencia en los tratamientos, cuando de hecho no hay diferencia (casilla B), se presenta un error tipo I. 2.- Si el estudio no encuentra una diferencia en los tratamientos cuando en realidad si la hay (casilla C), se dice que ha ocurrido un error de tipo II. Recomendaciones para evitar los errores o sesgos: -Aumentar el tamaño de la muestra PODER ESTADÍSTICO DE UNA PRUEBA En algunas ocasiones, los resultados de un estudio no son significativos. Se habla entonces de “estudios negativos”. No obstante, la ausencia de significación estadística no implica necesariamente que no exista relación entre el factor de estudio y la respuesta. Puede ocurrir, que aún existiendo tal asociación o una diferencia clínicamente relevante, el estudio haya sido incapaz de detectarla como estadísticamente significativa. En estudios de este tipo se concluirá que no existen diferencias cuando realmente sí las hay. Este error se conoce como error de tipo II. La probabilidad de cometer un error de este tipo suele denotarse por β y su complementario, 1-β, es lo que se conoce como poder estadístico o potencia estadística Factores que influyen en el poder estadístico de un estudio. Resultados Estudio Trat. Difererentes Trat. Iguales A B Correcto Error tipo I C D Error tipoII Correcto d Trat.diferentes Trat.iguales REALIDAD
- 30. El tamaño del efecto a detectar, es decir, la magnitud mínima de la diferencia o asociación entre los grupos que se considera clínicamente relevante. Cuanto mayor sea el tamaño del efecto que se desea detectar, mayor será la probabilidad de obtener hallazgos significativos y, por lo tanto, mayor será el poder estadístico. La variabilidad de la respuesta estudiada. Así, cuanto mayor sea la variabilidad en la respuesta, más difícil será detectar diferencias entre los grupos que se comparan y menor será el poder estadístico de la investigación. De ahí que sea recomendable estudiar grupos lo más homogéneos posibles. El tamaño de la muestra a estudiar. Cuanto mayor sea el tamaño muestreal, mayor será la potencia estadística de un estudio. Es por ello que en los estudios con muestras muy grandes se detectan como significativas diferencias poco relevantes, y en los estudios con muestras menores es más fácil obtener resultados falsamente negativos. El nivel de significación estadística. Si disminuimos la probabilidad de cometer un error de tipo I aumentamos simultáneamente la probabilidad de un error de tipo II, por lo que se trata de encontrar un punto de “equilibrio” entre ambas. Habitualmente se trabaja con un nivel de significación del 0.05 y un error β de 0.2. Esto significa que la probabilidad de cometer un error del tipo II es cuatro veces mayor que la probabilidad de cometer un error tipo I lo que refleja que, en general, un error tipo I se considera mucho mas grave que un error del tipo II. Ejem. Toxoplasmosis Tabla 3.-Análisis de variables potencialmente asociadas a seropositividad a Toxoplasma gondii en mujeres que abortan. Variables Total: 62 # % Seropositivos a IgG e IgM: 31 # % Seronegativo a : IgG e IgM:31 # % Ama de casa* 47 75.8 23 75.4 24 80 Aborto en el primer trimestre* 46 74.1 25 80.6 21 72.4 Convivencia con gatos* 40 64.5 22 71 18 58.1 Convivencia con gatos menores de 6 meses* 14 22.5 7 31.8 7 35 Convivencia con roedores(ratas y ratones)* 30 48.3 17 56.7 13 43.3 Agua potable para 62 100 31 100 31 100
- 31. consumo* Higiene en el consumo de alimentos(lavar y desinfectar vegetales)* 62 100 31 100 31 100 Higiene personal(lavarse las manos ocasionalmente)* 18 29 11 35.5 7 22.5 *p>0.05 Ejem. Leptospirosis Table 3 CONTACT FREQUENCY WITH TRANSMISSION FACTORS IN A POPULATION FROM YUCATAN, MEXICO. CONTACT WITH RESERVOIRS PEOPLE SURVEYED 400 % NEGATIVE 343 % POSITIVE 57 % RODENTS * DOGS OPOSSUMS PIGS BOVINES 262 286 240 120 53 65.5 71.5 60.0 30.0 13.2 219 247 206 102 43 63.8 72.0 60.0 29.7 12.5 44 39 33 17 10 77.2 68.4 58.0 29.8 17.5 INADEQUATE WATER 267 66.7 230 67 37 65.0
- 32. STORAGE CONTACT WITH NATURAL WATER DEPOSITS ** 93 23.2 74 21.6 19 33.3 (1) * P≤0.05 (2) **P≤0.05 Table 1 SEROREACTIVITY FREQUENCY, BY AGE AND SEX, IN YUCATAN MEXICO SAMPLE SIZE 400 POSITIVES 57 % 14.2 AGE GROUPS * <15 15-35 36-56 >56 25 161 160 54 1 21 25 10 4.0 13.0 15.6 18.5 SEX ** FEMALE MALE 266 134 31 26 11.6 19.4 * P≥0.05 ** P≤ 0.05 Ejercicio:
- 33. Supongamos que se quiere llevar a cabo un ensayo clínico para comparar la efectividad de un nuevo fármaco con la de otro estándar en el tratamiento de una determinada enfermedad. Al inicio del estudio, se sabe que la eficacia del tratamiento habitual está en torno al 40%, y se espera que con el nuevo fármaco la eficacia aumente al menos en un 15%. El estudio se diseñó para que tuviese un poder del 80%, asumiendo una seguridad del 95%. Esto implica que son necesarios 173 pacientes en cada uno de los grupos para llevar a cabo la investigación. Tras finalizar el estudio, sólo fue posible tratar con cada uno de los fármacos a 130 pacientes en cada grupo en lugar de los 173 pacientes estimados inicialmente. Al realizar el análisis estadístico, se objetivó que no hay diferencias significativas en la efectividad de ambos tratamientos. A partir de las fórmulas de la Tabla 2, podemos calcular cuál ha sido finalmente el poder del estudio. Aplicando la fórmula para el cálculo del poder estadístico de comparación de dos proporciones ante un planteamiento unilateral se obtiene: ( ) ( ) ( ) ( ) ( ) ( ) 467.0 55.0155.04.014.0 475.01475.02645.113055.04.0 11 12 645.105.0 130 475.0 55.0 4.0 2211 121 1 1 2 1 = −+− −⋅⋅⋅−− = = −+− −−− =⇒ =⇒= = =⇒ = = − − − pppp ppznpp z z n p p p α β αα A partir de la Tabla 3, podemos determinar que un valor de 467.01 =−βz corresponde a un poder en torno al 65%-70%. Utilizando las tablas de la distribución normal, se sabe que el poder es del 68%, es decir, el estudio tendría un 68% de posibilidades de detectar una mejora en la eficacia del tratamiento del 15%. Tabla 3. Valores de α−1 z , 2 1 α− z y β−1z más frecuentemente utilizados. Seguridad α Test unilateral α−1 z Test bilateral 2 1 α− z 80 % 0,200 0,842 1,282
- 34. 85 % 0,150 1,036 1,440 90 % 0,100 1,282 1,645 95 % 0,050 1,645 1,960 97,5 % 0,025 1,960 2,240 99 % 0,010 2,326 2,576 Poder estadístico β−1 β β−1z 99 % 0,99 0,01 2,326 95 % 0,95 0,05 1,645 90 % 0,90 0,10 1,282 85 % 0,85 0,15 1,036 80 % 0,80 0,20 0,842 75 % 0,75 0,25 0,674 70 % 0,70 0,30 0,524 65 % 0,65 0,35 0,385 60 % 0,60 0,40 0,253 55 % 0,55 0,45 0,126 50 % 0,50 0,50 0,000 Figura 1.
- 35. Poder estadístico en función del tamaño muestral y la magnitud del efecto a detectar. Comparación de dos proporciones p1 y p2. 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% 0 50 100 150 200 250 300 350 400 450 500 Número de casos por grupo p1=40% p2=50% p1=40%; p2=55% p1=40%; p2=60% Figura 2.
- 36. Poder estadístico en función del tamaño muestral y el número de controles por caso en un estudio de casos y controles. p2=40%; OR=2 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% 0 50 100 150 200 250 300 350 400 450 500 Número de casos c=1 c=2 c=3 c=4 c=5 Tabla 2. Fórmulas para el cálculo del poder estadístico para diferentes tipos de diseño. Test unilateral Test bilateral Comparación de dos proporciones ( ) ( ) ( )2211 121 1 11 12 pppp ppznpp z −+− −−− = − − α β ( ) ( ) ( )2211 2 121 1 11 12 pppp ppznpp z −+− −−− = − − α β Comparación de dos media αβ −− −= 11 2 z S dn z 2 11 2 αβ −− −= z S dn z Estimación de un OR en estudios de ( ) 22 2 1 1 pORp pOR p ⋅+− ⋅ = ( ) 22 2 1 1 pORp pOR p ⋅+− ⋅ =
- 37. casos y controles ( ) ( ) ( )2211 121 1 11 1)1( ppppc ppczncpp z −+−⋅ −+−− = − − α β ncm ⋅= ( ) ( ) ( )2211 2 121 1 11 1)1( ppppc ppczncpp z −+−⋅ −+−− = − − α β ncm ⋅= Estimación de un RR 21 pRRp ⋅= ( ) ( ) ( )2211 121 1 11 12 pppp ppznpp z −+− −−− = − − α β 21 pRRp ⋅= ( ) ( ) ( )2211 2 121 1 11 12 pppp ppznpp z −+− −−− = − − α β Estimación de un coeficiente de correlación lineal αβ −− − − + −= 11 1 1 ln 2 1 3 z r r nz 2 11 1 1 ln 2 1 3 αβ −− − − + −= z r r nz n = Tamaño muestral. En un estudio de casos y controles, n es el número de casos. 1p = En un estudio transversal o de cohortes, proporción de expuestos que desarrollan la enfermedad. En un estudio de casos y controles, proporción de casos expuestos. 2p = En un estudio transversal o de cohortes, proporción de no expuestos que desarrollan la enfermedad. En un estudio de casos y controles, proporción de controles expuestos. 2 21 pp p + = d = Valor mínimo de la diferencia a detectar entre dos medias S2 = Varianza en el grupo control o de referencia c = Número de controles por caso m = En un estudio de casos y controles, número de controles OR = Valor aproximado del odds ratio a detectar RR = Valor aproximado del riesgo relativo a detectar r = Magnitud del coeficiente de correlación a detectar
- 38. TAMAÑO DE MUESTRA PARA ESTUDIOS DE CASOS Y CONTROLES Y ESTUDIOS DE COHORTES EJEM: CASOS Y CONTROLES Asociación entre consumo reciente de carne y enteritis necrotizante en Papua Nueva Guinea EXPOSICIÓN SI NO TOTAL CASOS 50 11 61 CONTROLES 16 41 57 TOTAL 66 52 118 50 X 41 OR= -------------= 11.6 11 X 16 Tamaño de la muestra para casos y controles: -Razón de controles por caso= 1 -Valor de la razón de ventajas( OR)= 11.6 -% de controles expuestos en la población de controles= 28% -Riesgo 5% -Potencia 80% n= casos 16 controles 16 total= 32
- 39. EJEM: COHORTE Fumar en el embarazo y tener un recién nacido de bajo peso (datos supuestos) E f e c t o (bajo peso) Exposición (fumar) Si No Total Si 20 180 200 No 40 760 800 Total 60 940 1000 I de expuestos 20/200 RR= ----------------------= -----------= 2 I de no expuestos 40/800 Tamaño de muestra para estudios de COHORTE Razón de no expuesto por expuesto 1: 4 Valor del riesgo relativo (RR) detectado 2 Tasa de ataque entre no expuestos 40/800 =0.05 Riesgo 5% Potencia de la prueba (1-β) 80% n= 314 Exp y 1256 No expuestos total= 1570 OBTENCIÒN DE TAMAÑO DE MUESTRA EN PROGRAMA ESTADÍSTICO EPI-INFO (EPITABLE) U OTRA LITERATURA.
- 40. Muestreo probabilístico (aleatorio): Método que consiste en extraer al azar una parte o muestra de una población o universo, de tal forma que, cada elemento de la población tiene la misma oportunidad de ser incluido dentro de la muestra. En el muestreo no probabilística no se utilizan técnicas de azar para seleccionar las muestras. MUESTREO PROBABILÍSTICO (estudios transversales) 1.-MUESTREO ALEATORIO SIMPLE a).-Realizar el marco de muestreo b).-Seleccionar las unidades de estudio -Tabla de números al azar - Utilizando un programa estadístico - Otros Ejemplo: Población = 2000 historias clínicas de un Hospital Tamaño de la muestra (n)= 100 -Enumerar todas las historias -Selección de las 100 historias en la tabla -Comenzar en un lugar de la tabla también elegido al azar - El número de cifras que se incluirán es igual al de la población -Sí se repiten los números se sustituyen por otros Probabilístico No probabilístico Aleatorio simple Sistemático Por conveniencia intencionado TIPOS DE MUESTREO Estratificado Conglomerados
- 41. 2.-MUESTREO SISTEMÁTICO -Enumerar los números entre uno y N -Calcular el espaciamiento de muestreo N 2000 _____ = K ------ = 20 n 100 -Elegir al azar un número entre uno y K - A partir de este número se obtendrán los demás sumándoles K Ejemplo: Suponiendo que es 17, 37, 57, 77 etc. 3.-MUESTREO ESTRATIFICADO -Se utiliza cuando la población es muy heterogenea, siendo afectada la variable de estudio por otras variables. -Se divide en estratos -Cada uno tendrá cierto número de elementos N1, N2, N3 cuya suma será N -Cada estrato se determina proporcionalmente del tamaño de la muestra de manera que la suma de los estratos será igual al tamaño de la muestra. -La elección de los elementos dentro de cada estrato se hace usando el método al azar o el sistemático. Ejem: Estudiar el diagnóstico de pacientes en un Hospital Estratos: en pediatría, en clínica, en obstetricia etc. 4.-MUESTREO EN ETAPAS MÚLTIPLES O MULTIETÁPICO -Se usa cuando no puede ser fácilmente enumerada la población(marco de muestreo), entonces se hace una numeración geográfica. -Ejem: se desea obtener una prevalencia de x enfermedad en un estado Se clasifican en sectores geográficos y se extrae una muestra En cada sector se procede a listar manzanas y se extrae una muestra De cada manzana se extrae una muestra de habitantes o familias (unidades de estudio). -Sus inferencias son menos precisas que el método estratificado, sin embargo es a veces el único método que podemos realizar. 5.- CONGLOMERADOS -Agrupa un número de sujetos o unidades de observación que tienen algo en común -La población se divide en conglomerados y luego en unidades de estudio que son seleccionadas mediante técnicas aleatorias como muestreo simple, sistemático etc- NUMEROS ALEATORIOS
- 42. CRITERIOS DE INCLUSIÓN: Son aquellas características que deben reunir los sujetos o unidades de observación para formar parte del estudio. CRITERIOS DE EXCLUSIÓN: Son aquellas características que deben estar ausentes en los sujetos o unidades de observación para formar parte del estudio. CRITERIOS DE ELIMINACIÓN: Son aquellas características que aparecen una vez que ya han sido seleccionados los sujetos o unidades de observación y que obligan a eliminarlas del estudio. Definición de caso: En términos generales “caso” se ha utilizado para indicar a un individuo que tiene la enfermedad o manifiesta un resultado relevante. En epidemiología la prevalencia e incidencia hacen referencia a la frecuencia de los casos entre grupos de población. Definición de control: Estándar frente al cual pueden valorarse observaciones experimentales o analíticas observacionales. VARIABLES: Son las características que estudiamos en cada individuo de la muestra (género, edad, talla, peso, IMC, TA etc) Cuantitativas (No categóricas): Variables que pueden medirse, cuantificarse o expresarse numéricamente. - Continuas: si admiten tomar cualquier valor dentro de un rango numérico determinado (edad, peso, talla) - Discretas: si no admiten todos los valores intermedios en un rango. Toman solamente valores enteros (Nº de integrantes de la familia, Nº nacimientos, FR etc.) Cualitativas (categóricas): variables que representan una cualidad o atributo que clasifica a cada caso en una de varias categorías. -Escalas nominales: Forma de observar o medir en la que los datos se ajustan por categorías que no mantienen una relación de orden entre sí (color de ojos, sexo, profesión, grupo sanguíneo). Son datos dicotómicos o binarios aquellos
- 43. que la presencia de uno excluye al otro (sano/enfermo, positivo/negativo, parto/no parto) -Escalas ordinales: son aquellas en que existe un cierto orden o jerarquía entre las categorías (curso clínico., estudiante de primaria, secundaria, preparatoria., médico interno, residente, de base) VARIABLES DEPENDIENTES VARIABLES INDEPENDIENTES DATOS: Son los valores que toma la variable según el caso PLAN DE RECOLECCIÓN DE LA INFORMACIÓN Métodos e instrumentos de recolección de datos.- 1.- La observación. - Registro visual de lo que ocurre en una situación real, clasificando y consignando los acontecimientos pertinentes de acuerdo con algún esquema previsto y según el problema que se estudia. 2.- La encuesta -Método que consiste en obtener información de los sujetos de estudio, proporcionada por ellos mismos, sobre opiniones, actitudes o sugerencias. 2.1.La entrevista -Comunicación interpersonal establecida entre el investigador y el sujeto de estudio a fin de obtener respuestas verbales a las interrogantes planteadas sobre el problema propuesto. Ejem. Entrevista por telefono, por correo electrónico etc. 2.1.El cuestionario -Consiste en un conjunto de preguntas respecto a una o más variables a medir. Las preguntas se clasifican en: a)Cerradas Después de la pregunta se presentan diversas opciones de las que el entrevistado debe escoger una, o varias, según sea el caso. b)Abiertas Se deja un espacio para que el entrevistado escriba su opinión.
- 44. c)Mixtas Preguntas con varias respuestas posibles, algunas de ellas abiertas y otras cerradas. Características deseables de las preguntas.- - Las preguntas deben plantearse en lenguaje sencillo y claro, de acuerdo con la preparación del encuestado. - Deben ser breves, sin que ello altere su contenido. - No preguntar lo obvio -Cada pregunta debe referirse a una sola idea -Deben evitarse preguntas que requieren de muchos datos. -No hay que inducir la respuesta -Evitar palabras que tengan una intensa carga afectiva -Debe seguirse un orden lógico en las preguntas -Si se desea conocer el grado de satisfacción de una persona por un servicio, no debe preguntársele directamente si fue de su agrado o no. Requisitos que debe cubrir un instrumento de medición: Confiabilidad y Validez La confiabilidad se refiere al grado en que su aplicación repetida al mismo sujeto u objeto produce resultados iguales. La validez se refiere al grado en que un instrumento realmente mide la variable que pretende medir. Prueba piloto del instrumento de validación.- Sirve para analizar si las instrucciones se comprenden y funcionan de manera adecuada. Los resultados se usan para calcular la confiabilidad y de ser posible la validez del instrumento. (también sirve para estimar la prevalencia o “p”) Se realiza con una pequeña muestra (inferior a la muestra definitiva. Se aconseja que cuando la muestra definitiva sea mayor de 200 o más, se lleve a cabo la prueba piloto con 25-60 personas. Ejemplo cuestionario: EPIDEMIOLOGICA PROGRAMA: TOXOPLASMOSIS La información recabada en este cuestionario será utilizada únicamente para fines de investigación en forma discreta y sin mención de los nombres de las personas entrevistadas. 1.- DATOS DEL ENTREVISTADO:
- 45. Fecha: Nombre: Edad: Meses de embarazo: Ocupación: Primípara ( ) Multípara ( ) 1.- ¿Convive con gatos ? Si ( ) No ( ) 2.- ¿Ve roedores en su casa? Si ( ) No ( ) 3.- En caso de tener gatos en su vivienda ¿son menores de 6 meses de edad? Si ( ) No ( ) 4.- La carne que usted consume es de: cerdo ( ) Res ( ) Otra_______________________ 5.- El modo de preparación es: Bien cocida ( ) 6.- El agua que usted consume ¿es potable? Si ( ) No ( ) 7.- ¿Lava o desinfecta frutas y vegetales destinados para su consumo? Si ( ) No ( ) 8.- ¿Se lava las manos antes de ingerir algún alimento? Siempre ( ) En ocasiones ( ) Casi nunca ( ) Nunca ( ) 9.- ¿Presentó algún síntoma? Si ( ) No ( ) Inflamación ganglionar Mialgia Fiebre Artralgia Adinamia Hepatomegalia Cefalea Esplenomegalia Visión borrosa 10.- ¿Presentó alguna otra enfermedad durante el embarazo? Si ( ) No ( ) Cual ______________________________ Resultado ELISA IgM: ______________ Resultado de ELISA IgG_______________
- 46. FUERZA DE LA ASOCIACIÓN O RIESGOS Riesgo: probabilidad de que los individuos que están expuestos a ciertos factores (factores de riesgo) desarrollen ulteriormente una enfermedad determinada u otro evento o fenómeno. Factor de riesgo: Características que se asocian aumentando la probabilidad de contraer la enfermedad u otro evento. 1.-RAZÓN DE PRODUCTOS CRUZADOS O RM= RAZÓN DE MOMIOS (RM) o (OR a x d Casos y controles b x c Ejem: Asociación entre consumo de carne y enteritis necrotizante en Nueva Guinea Exp. No Exp. total casos 50(a) 11(b) 61 Controles(sanos) 16(c) 41(d) 57 total 66 52 118 50 x 41 RM: --------- = 11.6 veces más frecuente en consumidores de carne que en no 11 x 16 consumid. o sea 11.6 veces más probable que te enfermes cuando comes carne. 2.- RIESGO RELATIVO (RR) RR= a/ (a+b) Estudios de cohorte c/ (c+d) Mide incidencia Ensayos aleatorios Exposición Enfer. No enfer. total Alcohol ≥ 80g/día 175(a) 2825(b) 3000
- 47. Alcohol < 80g/día 207(c) 6793(d) 7000 total 382 9618 10,000 175/3000 0.0583 RR: ----------- = ------- =1.97 Por tanto es 2 veces más probable que te enfermes cuando 207/7000 0.0295 ingieras alcohol ≥ 80g/día que cuando bebes menor cantidad. Otras medidas de riesgo: Riesgo atribuible ( en expuestos) o diferencia de riesgos (expuestos menos no expuestos). Fracción atribuible o fracción etiológica (en los expuestos). Proporción de enfermedad que se eliminaría en la población de estudio si no existiera exposición. SESGOS POTENCIALES EN LOS ESTUDIOS EPIDEMIOLÓGICOS SESGOS DE SELECCIÓN El sesgo de selección sucede cuando los individuos seleccionados difieren en características importantes de la población de origen (a la que se pretende extrapolar los hallazgos del estudio) o de otro grupo de personas ( con el que se buscan hacer comparaciones). SESGO DE MEDICIÓN Ocurre cuando durante la fase de obtención de información, los investigadores utilizan para cada uno de los grupos estudiados criterios diferentes de recolección o interpretación de datos o ambos. -SESGO DE CONFUSIÓN Se produce cuando dos factores están asociados entre sí o viajan juntos y el efecto de uno está confundido con otro o distorsionado por el efecto del otro. FENÓMENO DE CONFUSIÓN: CONSUMO DE CAFÉ, CONSUMO DE TABACO Y CARDIOPATÍA ISQUÉMICA.
- 48. CONTROL DEL SESGO 1)Experiencias a ciego simple 2) Experiencias a doble ciego 3) Experiencias a triple ciego PRUEBA DE HIPÓTESIS Y PLAN DE ANÁLISIS ESTADISTICO Para realizar una prueba de hipótesis se necesita de la ejecución de una serie de pasos: 1.- Plantear la hipótesis 2.-Definir el tipo de prueba a realizar Unilateral o bilateral 3.-Fijar el nivel de significancia o valor de alpha 0.05 0.01 4.-Identificar el estadístico de prueba a utilizar, cuya elección depende de los siguiente: EXPOSICIÓN ENFERMEDAD (consumo de café) Cardiopatía isquémica VARIABLE DE CONFUSIÓN (consumo de cigarrillos)
- 49. a) Lo que se pretende comparar: promedios, varianzas, medidas de riesgo, porcentajes. b) Número de grupos de muestras por estudiar: una, dos, tres etc. c) Tipo de muestras: independientes, relacionadas o pareadas, aleatorias o no aleatorias (por conveniencia). d)Tamaño de la(s) muestras e)Escala de medición de las variables: cuantitativas, ( discretas, continuas), cuantitativas, (nominales, ordinales). Con base en lo anterior, la prueba estadística apropiada será paramétrica o no paramétrica. Las paramétricas requieren para su aplicación de las siguientes condiciones: -Observaciones independientes -Que las observaciones procedan de poblaciones con distribución normal -Con varianzas iguales o conocidas -Variables cuantitativas Pertenecen a este tipo de pruebas: “Z”, “T”, “Análisis de varianza”, “F” y la prueba de “correlación de Pearson” entre otras. Las no paramétricas, no exigen el cumplimiento de condiciones tan estrictas y por tanto pueden ser aplicadas a varias medidas, aun en una escala nominal u ordinal. Pertenecen a este tipo: “Chi cuadrada”, “Prueba exacta de Fisher”, “Prueba del cambio de Mc Nemar”, “Prueba de signos entre otras”. 5.-Plantear la regla de decisión para el rechazo de la hipótesis de nulidad. ASOCIACIÓN DE VARIABLES CUALITATIVAS 1).-Prueba de chi² 2).-Prueba exacta de Fisher 3).-Prueba del cambio Mc Nemar 4).- Otras (Signos, Willconson, Man Whitney ) Prueba de Ji cuadrada -Pruebas no paramétricas -Variables cualitativas -Datos de frecuencia -No se recomienda para porcentajes
- 50. Se aplica a datos en una tabla de contingencia, solamente si las frecuencias esperadas son suficientemente grandes (mínima de 5 observaciones) Ejemplo: supongamos que deseamos saber si existe asociación entre los factores sexo y color de cabello. Para ello observamos a 50 hombres y 50 mujeres que van a comprar a una plaza comercial y registramos cuantas (os) tienen el pelo rubio o castaño en cada grupo. COLOR DEL CABELLO SEXO RUBIO(AS) CASTAÑO (AS) HOMBRES 20 30 50 MUJERES 24 26 50 44 56 100 Como no tenemos idea de las frecuencias esperadas, entonces debemos calcularlas bajo el supuesto de que el color del cabello no es dependiente del sexo (no existe asociación). Si esto es verdad podemos esperar que la mitad de ambas muestras (hombres y mujeres) sean rubias (os) y la otra mitad castaños (as). Trabajando con totales marginales tenemos : 50 50 ---- x 44 = 22 (rubios) ---- x 44 = 22 (rubias) 100 100 50 50 ----- X 56 = 28 (castaños) ----- X 56= 28 (castañas) 100 100 Una vez calculados los valores esperados: RUBIOS CASTAÑOS HOMBRES MUJERES 20 (22) 24(22) 30(28) 26(28) 50 50 44 56 100 Ahora se calcula el valor de Ji cuadrada y como se trata de una tabla de dos x dos se utiliza el factor de corrección de Yates (0.50): X² = ( / O –E / - 0.50)² ( / O – E / - 0.50)² --------------------- + --------------------- E E
- 51. X² = ( / 20 – 22 / - 0.50)² + ( / 30 – 28 / - 0.50 )² ------------------------- ------------------------ 22 28 + ( / 24 – 22 / - 0.50)² + ( / 26 – 28 / - 0.50 )² ------------------------- ------------------------ 22 28 = 0.102 + 0.080 + 0.102 + 0.080 = 0.364 Buscando en la tabla a un grado de libertad (2-1) (2-1)= 1 y a (0.05) encontramos Que es igual a 3.841 > 3.64 por tanto no es significativo. Así el color del pelo no se encontró asociado al sexo. Se pueden utilizar más de dos categorías. Percentiles de la distribución de chi2 Gl X2 .005 X2 .025 X2 ……….X2 .90 X2 .95…… -------------------------------------------------------------------------------------------------------------- 1 .000000393 .000982 .000393 2.706 3.841 2 3 4 n PRUEBA DEL CAMBIO DE MC NEMAR Aplicable a los diseños “antes-después” o “pre-post” donde cada sujeto es su propio control, las variables son cualitativas y/o la escala de medición es nominal u ordinal (solo con dos categorías) La hipótesis de investigación debe aludir a que existirán cambios significativos en las categorías después de la intervención. La hipótesis nula Ho: establece que no habrán cambios o si existen diferencias, estas no serán significativas. Se define la regla de decisión, esto es, la situación que llevará al rechazo de la Ho, si el valor calculado de la prueba de Mc Nemar es mayor que el valor crítico de la tabla. ANTES DESPUÉS + - + A B A+B - C D C+D A+C B+D A+B+C+D
- 52. Para calcular: X² = ( /A-D/ ) -1)² A+D El valor obtenido se compara con valor de tabla para X² con 1 grado de libertad, α 0.05 = 3.84 Una vez obtenido este valor, se aplica la regla de decisión. Si el valor calculado es mayor que el valor de tabla, se rechaza la Ho: concluyendo que hay cambios después de la intervención. Pero si el valor calculado es menor al valor crítico de la tabla, no será posible rechazar la Ho: y se concluirá que los cambios después de la intervención no son significativos. Ejemplo de ficción: Se entrevistó a una muestra aleatoria de 75 burocratas acerca de su preferencia para el candidato presidencial antes y después de de un debate televisivo. Después del debate, de los 41 foxistas, 13 continuaban fieles y 28 traidores, lo cambiaron por Labastida, en tanto que los 34 simpatizantes de Labastida, 7 continuaron con él hasta el desempleo y 27 rectificaron a tiempo, por lo que aún conservan su empleo. La hipótesis de trabajo suponía que Labastida con sus argumentos ganaría adeptos. ANTES DEBATE DESPUÉS DEBATE FOX LABASTIDA FOX 13 A 28 B 41 ( A+B) LABASTIDA 27 C 7 D 34 ( C+D) 40 (A+C) 35 (B+D) 75 (A+B+C+D) Regla de decisión: Rechazar Ho si el valor de Mcnemar calculado es mayor que el de tabla o crítico para el test de X² con 1 grado de libertad, α 0.05= 5.024, cuando la hipótesis plantea la dirección del cambio, lo que significa localizarse en una cola, pero si solamente hubiera propuesto que existirían cambios en las preferencias, sin apostar por algún candidato, sería una prueba de dos colas y α 0.05= 3.84. Se calcula= ( /13 -7 / ) -1)² = (6-1)² 25 = 1.25 13+7 20 20 Dado que 1.25 es < el valor de tabla 5.024 No se rechaza la hipótesis Ho,concluyéndose que no hubieron cambios en las preferencias por Labastida después del debate. ESTUDIOS EXPERIMENTALES
- 53. DISEÑO DE UN ENSAYO CLÍNICO ALEATORIZADO CONTROLADO -Investigación experimental epidemiológica destinada a estudiar un nuevo protocolo preventivo o terapéutico. -Las unidades de estudio son pacientes. -Las personas de una población se asignan de forma aleatoria a uno de dos grupos llamados generalmente de tratamiento y de control. -Los resultados se valoran comparando la evolución en los dos grupos. -La distribución aleatoria asegura que ambos grupos serán comparables al inicio de la investigación y cualquier diferencia entre estos será debido al azar y no a la influencia de sesgos introducidos por los investigadores. -Todas las personas que intervienen en el estudio han de cumplir criterios especificados para la enfermedad de manera que garanticen grupos homogéneos. -Estos estudios han sido útiles en los países en desarrollo para comprobar el valor de tratamientos nuevos para enfermedades agudas.
- 54. ENSAYO DE CAMPO -Participan personas sanas y la investigación se realiza en personas de la población general no ingresadas en instituciones. -Su objetivo principal es prevenir las enfermedades. -Por lo general son costosos e implican grandes tareas. -Se pueden utilizar para evaluar intervenciones tendientes a reducir la exposición, ejem. Métodos de protección frente a la exposición a plaguicidas. POBLACIÓN A ESTUDIAR SELECCIÓN MEDIANTE CRITERIOS DEFINIDOS NO PARTICIPANTES (NO CUMPLIERON CON LOS CRITERIOS DE SELECCIÓN) PARTICIPANTES POTENCIALES NO PARTICIPANTES INVITACIÓN A PARTICIPAR PARTICIPANTES ASIGNACIÓN ALEATORIZADA GRUPO DE TRATAMIENTO GRUPO CONTROL
- 55. ENFERMOS: 32 37 RESULTADOS NO ENFERMOS 635 608 ENSAYOS COMUNITARIOS O DE COMUNIDADES -Se estudian comunidades en lugar de personas. -Diseño adecuado para investigar enfermedades que tienen origen en condiciones sociales. -Solo pueden incluirse un pequeño grupo de comunidades complicando la aleatorización. -Resulta difícil aislar las comunidades en las que se hace la intervención. Ajustes a la población: Cuado no se reemplaza el tamaño de la población durante el muestreo (en muestras iguales o mayores al 5% y poblaciones pequeñas), esta disminuye y por tanto la probabilidad de seleccionar una unidad de la población se incrementa. Factor de ajuste: n TMA=-------- 1+ n ---- ENSAYO DE CAMPO SOBRE UNA VACUNA CONTRA LEISHMANIASIS CUTANEA AMERICANA (LCA) RECLUTAS DEL EJERCITO (1436) EXCLUIDOS (124) ASIGNACIÓN ALEATORIZADA (1312) TRATAMIENTO (VACUNA) (667) CONTROL (PLACEBO) (645)
- 56. N EL VALOR DE “p” La pregunta que genera el investigador debe ser planteada en forma de una hipótesis nula (Ho). La hipótesis nula establece que no existe diferencia entre grupos de estudio o que no existe asociación entre los factores potenciales de riesgo y la enfermedad en cuestión. Para aceptarla o rechazarla el investigador selecciona la prueba estadística adecuada. Una vez aplicada la prueba se obtiene un resultado final que se expresa como probabilidad (p) > 0.05 o < 0.05 o >0.01 o < 0.01. Con base en este valor el investigador decide si acepta la Ho (no existe diferencias entre grupos o no hay asociación) o rechaza la Ho (existen diferencias estadísticamente significativas entre grupos o hay asociación significativa). En la prueba de hipótesis pueden existir dos clases de errores: establecer que existe diferencia cuandoen realidad no existe (error de tipo I) y establecer que no existe diferencia cuando en realidad si existe (error de tipo II). El valor de alfa (probabilidad de cometer un error tipo I o valor de p) convencionalmente se acepta como de 0.05 (nivel de significancia que se establece en el protocolo). Esto quiere decir que el investigador reconoce 5% de posibilidades de equivocarse al decir que existe diferencia cuando en realidad no la hay. Ante un valor de p significativo (p<0.05), si se contempló la participación del azar y se evitó o disminuyo el sesgo, queda la opción de considerar que existe realmente una diferencia que se explica al aceptar la hipótesis alternativa. Los resultados negativos (p>0.05) pueden tener un error de tipo II, ya que realmente existe una Diferencia que el estudio no pudo detectar; es decir que el trabajo no tuvo el poder suficiente para detectarla. El poder de un estudio esta en función del número de sujetos ( una pequeña diferencia puede ser estadísticamente significativa si se estudia un gran número de individuos) y de la variabilidad del fenómeno de interés ( si existe gran variabilidad será más difícil encontrar significancia). Debe considerarse también la dirección del estudio. Si se ignora la dirección del fenómeno (la prevalencia de una enfermedad en una entidad puede ser mayor, menor o diferente a la prevalencia nacional) el investigador debe evaluar una p unidireccional ( una cola) o bidireccional (dos colas), que en general requiere más individuos que una de una cola.
- 57. 1.-Si el estudio encuentra una diferencia en los tratamientos, cuando de hecho no hay diferencia (casilla B), se presenta un error tipo I. 2.- Si el estudio no encuentra una diferencia en los tratamientos cuando en realidad si la hay (casilla C), se dice que ha ocurrido un error de tipo II. Recomendaciones para evitar los errores: -Aumentar el tamaño de la muestra Representación gráfica en el Análisis de Datos Pértega Díaz S. Pita Fernández S. Unidad de Epidemiología Clínica y Bioestadística. Complexo Hospitalario Juan Canalejo. A Coruña (España) La realización de los estudios clínico-epidemiológicos implica finalmente emitir unos resultados cuantificables de dicho estudio o experimento. La claridad de dicha presentación es de vital importancia para la comprensión de los resultados y la interpretación de los mismos. A la hora de representar los resultados de un análisis estadístico de un modo adecuado, son varias las publicaciones que podemos consultar1 . Aunque se aconseja que la presentación de datos numéricos se haga habitualmente por medio de tablas, en ocasiones un diagrama o un gráfico pueden ayudarnos a representar de un modo más eficiente nuestros datos. Análisis descriptivo. Cuando se dispone de datos de una población, y antes de abordar análisis estadísticos más complejos, un primer paso consiste en presentar esa información de forma que ésta se Resultados Trat. Difer Trat Iguales A B Correcto Error tipo I C D Error tipoII Correcto d Trat.diferentess stintos Disdistintos Trat.iguales VERDAD
- 58. pueda visualizar de una manera más sistemática y resumida. Los datos que nos interesan dependen, en cada caso, del tipo de variables que estemos manejando2 . Para variables categóricas3 , como el sexo, estadio TNM, profesión, etc., se quiere conocer la frecuencia y el porcentaje del total de casos que "caen" en cada categoría. Una forma muy sencilla de representar gráficamente estos resultados es mediante diagramas de barras o diagramas de sectores. En los gráficos de sectores, también conocidos como diagramas de "tartas", se divide un círculo en tantas porciones como clases tenga la variable, de modo que a cada clase le corresponde un arco de círculo proporcional a su frecuencia absoluta o relativa. Un ejemplo se muestra en la Figura 1. Como se puede observar, la información que se debe mostrar en cada sector hace referencia al número de casos dentro de cada categoría y al porcentaje del total que estos representan. Si el número de categorías es excesivamente grande, la imagen proporcionada por el gráfico de sectores no es lo suficientemente clara y por lo tanto la situación ideal es cuando hay alrededor de tres categorías. En este caso se pueden apreciar con claridad dichos subgrupos. Los diagramas de barras son similares a los gráficos de sectores. Se representan tantas barras como categorías tiene la variable, de modo que la altura de cada una de ellas sea proporcional a la frecuencia o porcentaje de casos en cada clase (Figura 2). Estos mismos gráficos pueden utilizarse también para describir variables numéricas discretas que toman pocos valores (número de hijos, número de recidivas, etc.). Para variables numéricas continuas, tales como la edad, la tensión arterial o el índice de masa corporal, el tipo de gráfico más utilizado es el histograma. Para construir un gráfico de este tipo, se divide el rango de valores de la variable en intervalos de igual amplitud, representando sobre cada intervalo un rectángulo que tiene a este segmento como base. El criterio para calcular la altura de cada rectángulo es el de mantener la proporcionalidad entre las frecuencias absolutas (o relativas) de los datos en cada intervalo y el área de los rectángulos. Como ejemplo, la Tabla I muestra la distribución de frecuencias de la edad de 100 pacientes, comprendida entre los 18 y 42 años. Si se divide este rango en intervalos de dos años, el primer tramo está comprendido entre los 18 y 19 años, entre los que se encuentra el 4/100=4% del total. Por lo tanto, la primera barra tendrá altura proporcional a 4. Procediendo así sucesivamente, se construye el histograma que se muestra en la Figura 3. Uniendo los puntos medios del extremo superior de las barras del histograma, se obtiene una imagen que se llama polígono de frecuencias. Dicha figura pretende mostrar, de la forma más simple, en qué rangos se encuentra la mayor parte de los datos. Un ejemplo, utilizando los datos anteriores, se presenta en la Figura 4. Comparación de dos o más grupos. Cuando se quieren comparar las observaciones tomadas en dos o más grupos de individuos una vez más el método estadístico a utilizar, así como los gráficos apropiados para visualizar esa relación, dependen del tipo de variables que estemos manejando. Cuando se trabaja con dos variables cualitativas podemos seguir empleando gráficos de barras o de sectores. Podemos querer determinar, por ejemplo, si en una muestra dada, la frecuencia de sujetos que padecen una enfermedad coronaria es más frecuente en aquellos que tienen algún familiar con antecedentes cardiacos. A partir de dicha muestra podemos representar, como se hace en la Figura 7, dos grupos de barras: uno para los sujetos con
- 59. antecedentes cardiacos familiares y otro para los que no tienen este tipo de antecedentes. En cada grupo, se dibujan dos barras representando el porcentaje de pacientes que tienen o no alguna enfermedad coronaria. No se debe olvidar que cuando los tamaños de las dos poblaciones son diferentes, es conveniente utilizar las frecuencias relativas, ya que en otro caso el gráfico podría resultar engañoso. Por otro lado, la comparación de variables continuas en dos o más grupos se realiza habitualmente en términos de su valor medio, por medio del test t de Student, análisis de la varianza o métodos no paramétricos equivalentes, y así se ha de reflejar en el tipo de gráfico utilizado. En este caso resulta muy útil un diagrama de barras de error, como en la Figura 8. En él se compara el índice de masa corporal en una muestra de hombres y mujeres. Para cada grupo, se representa su valor medio, junto con su 95% intervalo de confianza. Conviene recordar que el hecho de que dichos intervalos no se solapen, no implica necesariamente que la diferencia entre ambos grupos pueda ser estadísticamente significativa, pero sí nos puede servir para valorar la magnitud de la misma. Así mismo, para visualizar este tipo de asociaciones, pueden utilizarse dos diagramas de cajas, uno para cada grupo. Estos diagramas son especialmente útiles aquí: no sólo permiten ver si existe o no diferencia entre los grupos, sino que además nos permiten comprobar la normalidad y la variabilidad de cada una de las distribuciones. No olvidemos que las hipótesis de normalidad y homocedasticidad son condiciones necesarias para aplicar algunos de los procedimientos de análisis paramétricos. Por último, señalar que también en esta situación pueden utilizarse los ya conocidos gráficos de barras, representando aquí como altura de cada barra el valor medio de la variable de interés. Los gráficos de líneas pueden resultar también especialmente interesantes, sobre todo cuando interesa estudiar tendencias a lo largo del tiempo (Figura 9). No son más que una serie de puntos conectados entre sí mediante rectas, donde cada punto puede representar distintas cosas según lo que nos interese en cada momento (el valor medio de una variable, porcentaje de casos en una categoría, el valor máximo en cada grupo, etc). Relación entre dos variables numéricas. Cuando lo que interesa es estudiar la relación entre dos variables continuas, el método de análisis adecuado es el estudio de la correlación. Los coeficientes de correlación (Pearson, Spearman, etc.) valoran hasta qué punto el valor de una de las variables aumenta o disminuye cuando crece el valor de la otra. Cuando se dispone de todos los datos, un modo sencillo de comprobar, gráficamente, si existe una correlación alta, es mediante diagramas de dispersión, donde se confronta, en el eje horizontal, el valor de una variable y en el eje vertical el valor de la otra. Un ejemplo sencillo de variables altamente correlacionados es la relación entre el peso y la talla de un sujeto. Partiendo de una muestra arbitraria, podemos construir el diagrama de dispersión de la Figura 10. En él puede observarse claramente como existe una relación directa entre ambas variables, y valorar hasta qué punto dicha relación puede modelizarse por la ecuación de una recta. Este tipo de gráficos son, por lo tanto, especialmente útiles en la etapa de selección de variables cuando se ajusta un modelo de regresión lineal. Otros gráficos.
- 60. Los tipos de gráficos mostrados hasta aquí son los más sencillos que podemos manejar, pero ofrecen grandes posibilidades para la representación de datos y pueden ser utilizados en múltiples situaciones, incluso para representar los resultados obtenidos por métodos de análisis más complicados. Podemos utilizar, por ejemplo, dos diagramas de líneas superpuestos para visualizar los resultados de un análisis de la varianza con dos factores (Figura 11). Un diagrama de dispersión es el método adecuado para valorar el resultado de un modelo de regresión logística (Figura 12). Existen incluso algunos análisis concretos que están basados completamente en la representación gráfica. En particular, la elaboración de curvas ROC (Figura 13) y el cálculo del área bajo la curva constituyen el método más apropiado para valorar la exactitud de una prueba diagnóstica. Hemos visto, por lo tanto, como la importancia y utilidad que las representaciones gráficas pueden alcanzar en el proceso de análisis de datos. La mayoría de los textos estadísticos y epidemiológicos4 hacen hincapié en los distintos tipos de gráficos que se pueden crear, como una herramienta imprescindible en la presentación de resultados y el proceso de análisis estadístico. No obstante, es difícil precisar cuándo es más apropiado utilizar un gráfico que una tabla. Más bien podremos considerarlos dos modos distintos pero complementarios de visualizar los mismos datos. La creciente utilización de distintos programas informáticos hace especialmente sencillo la obtención de las mismas. La mayoría de los paquetes estadísticos (SPSS, STATGRAPHICS, S-PLUS, EGRET,...) ofrecen grandes posibilidades en este sentido. Además de los gráficos vistos, es posible elaborar otros gráficos, incluso tridimensionales, permitiendo grandes cambios en su apariencia y facilidad de exportación a otros programas para presentar finalmente los resultados del estudio. Figura 1. Ejemplo de gráfico de sectores. Distribución de una muestra de pacientes según el hábito de fumar.
- 61. Arriba Figura 2. Ejemplo de gráfico de barras. Estadio TNM en el cáncer gástrico. Arriba Tabla I. Distribución de frecuencias
- 62. de la edad en 100 pacientes. Edad Nº de pacientes 18 1 19 3 20 4 21 7 22 5 23 8 24 10 25 8 26 9 27 6 28 6 29 4 30 3 31 4 32 5 33 3 34 2 35 3 36 1 37 2 38 3 39 1 41 1 42 1 Arriba Figura 3. Ejemplo de un histograma correspondiente a los datos de la Tabla I.
- 63. Figura 4. Polígono de frecuencias para los datos de la Tabla I. Arriba
- 64. Figura 6. Gráfico P-P de normalidad para los datos de la Tabla I. Arriba Figura 7. Diagrama de barras agrupadas. Relación entre la presencia de alguna enfermedad coronaria y los antecedentes cardiacos familiares en una muestra.
- 65. Figura 8. Barras de error. Variación en el índice de masa corporal según el sexo.
- 66. Figura 9. Gráfico de líneas. Número de pacientes trasplantados renales en el Complexo Hospitalario "Juan Canalejo" durante el periodo 1981-1997. Figura 10. Diagrama de dispersión entre la talla y el peso de una muestra de individuos.
- 67. Figura 11. Dos diagramas de líneas superpuestos. Variación en el peso medio de una muestra de recién nacidos según el control ginecológico del embarazo y el hábito de fumar de la madre. Figura 12. Diagrama de dispersión (regresión logística). Probabilidad de padecer cirrosis hepática, según un modelo de regresión logística ajustando por el % de protrombina y el presentar o no hepatomegalia.
- 68. Figura 13. Curva ROC para el porcentaje de protrombina en la predicción de cirrosis.