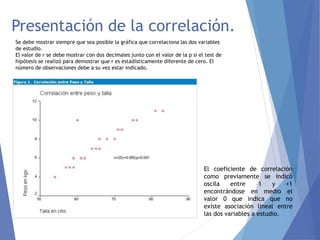
El documento explica el coeficiente de correlación de Pearson y Spearman. El coeficiente de Pearson mide la relación lineal entre dos variables cuantitativas, calculando cómo varían juntas y considerando valores entre -1 y 1, donde 1 indica una correlación positiva perfecta y -1 una negativa perfecta. El coeficiente de Spearman usa rangos en lugar de valores y es adecuado para variables ordinales o cuando los supuestos de Pearson no se cumplen. Ambos coeficientes proporcionan una medida de la fuerza de la asociación entre variables pero no implican causalidad.